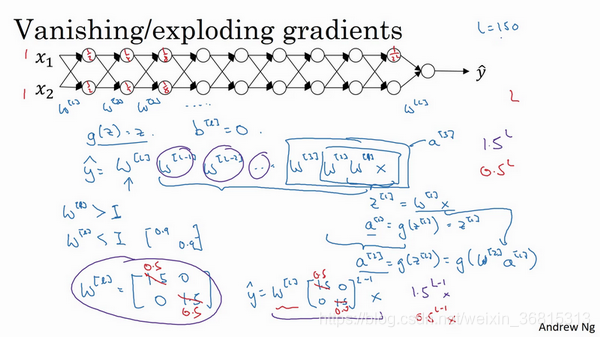
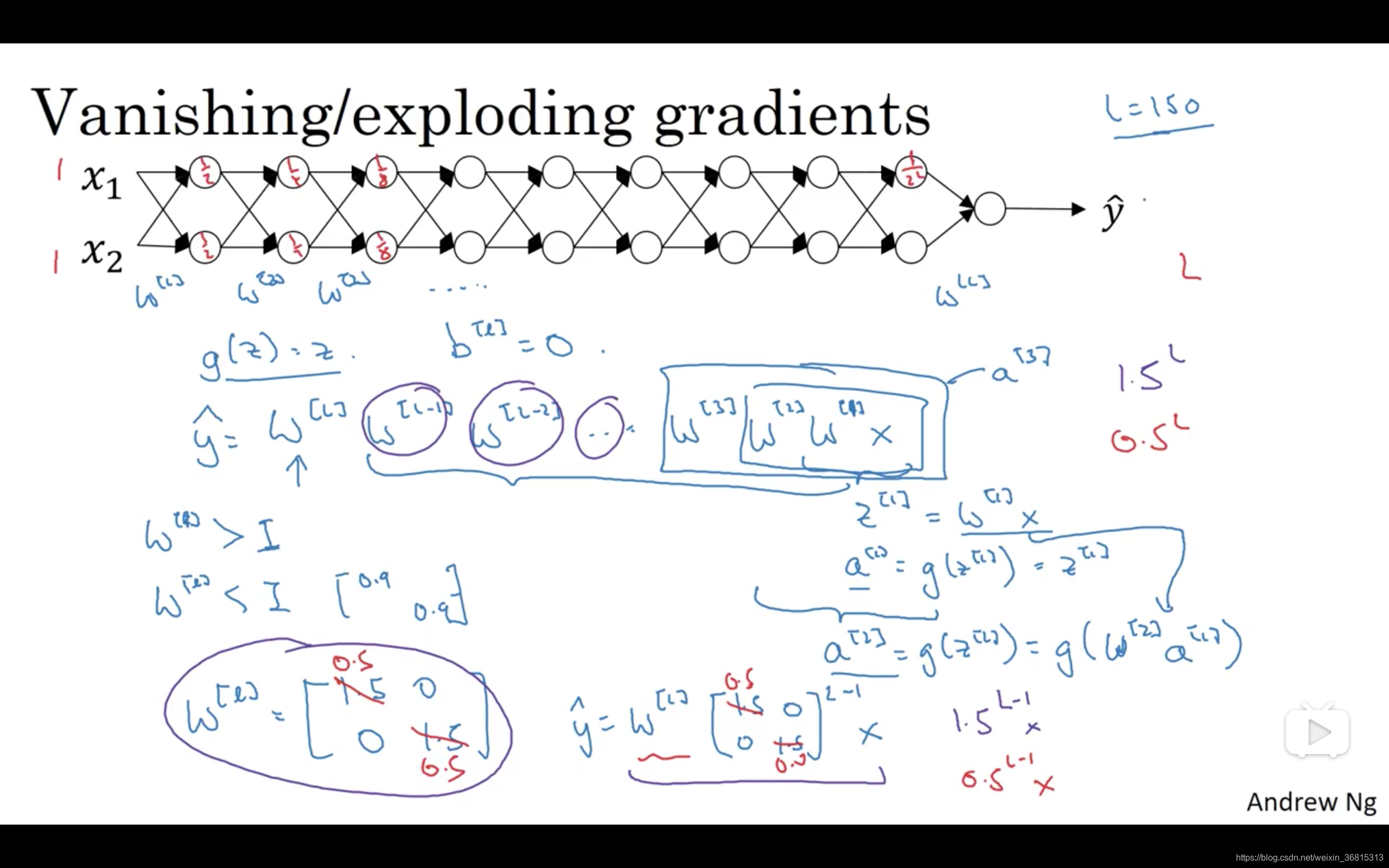
训练神经网络,尤其是深度神经所面临的一个问题就是梯度消失或梯度爆炸,也就是你训练神经网络的时候,导数或坡度有时会变得非常大,或者非常小,甚至于以指数方式变小,这加大了训练的难度。
这节课,你将会了解梯度消失或梯度爆炸的真正含义,以及如何更明智地选择随机初始化权重,从而避免这个问题。 假设你正在训练这样一个极深的神经网络,为了节约幻灯片上的空间,我画的神经网络每层只有两个隐藏单元,但它可能含有更多,但这个神经网络会有参数
w
[
1
]
w^{[1]}
w [ 1 ]
w
[
2
]
w^{[2]}
w [ 2 ]
w
[
3
]
w^{[3]}
w [ 3 ]
w
[
l
]
w^{[l]}
w [ l ]
g
(
z
)
=
z
g(z)=z
g ( z ) = z
b
b
b
b
[
l
]
b^{[l]}
b [ l ]
y
=
w
[
l
]
w
[
l
−
1
]
w
[
l
−
2
]
⋯
w
[
3
]
w
[
2
]
w
[
1
]
x
y=w^{[l]}w^{[l-1]}w^{[l-2]}\cdots w^{[3]}w^{[2]}w^{[1]}x
y = w [ l ] w [ l − 1 ] w [ l − 2 ] ⋯ w [ 3 ] w [ 2 ] w [ 1 ] x
w
[
1
]
x
=
z
[
1
]
w^{[1]}x=z^{[1]}
w [ 1 ] x = z [ 1 ]
b
=
0
b=0
b = 0
z
[
1
]
=
w
[
1
]
x
z^{[1]}=w^{[1]}x
z [ 1 ] = w [ 1 ] x
a
[
1
]
=
g
(
z
[
1
]
)
a^{[1]}=g(z^{[1]})
a [ 1 ] = g ( z [ 1 ] )
z
[
1
]
z^{[1]}
z [ 1 ]
w
[
1
]
x
=
a
[
1
]
w^{[1]}x=a^{[1]}
w [ 1 ] x = a [ 1 ]
w
[
2
]
w
[
1
]
x
=
a
[
2
]
w^{[2]}w^{[1]}x=a^{[2]}
w [ 2 ] w [ 1 ] x = a [ 2 ]
a
[
2
]
=
g
(
z
[
2
]
)
a^{[2]}=g(z^{[2]})
a [ 2 ] = g ( z [ 2 ] )
g
(
w
[
2
]
a
[
1
]
)
g(w^{[2]}a^{[1]})
g ( w [ 2 ] a [ 1 ] )
w
[
1
]
x
w^{[1]}x
w [ 1 ] x
a
[
1
]
a^{[1]}
a [ 1 ]
a
[
2
]
a^{[2]}
a [ 2 ]
a
[
3
]
(
w
[
3
]
w
[
2
]
w
[
1
]
x
)
a^{[3]}(w^{[3]}w^{[2]}w^{[1]}x)
a [ 3 ] ( w [ 3 ] w [ 2 ] w [ 1 ] x )
所有这些矩阵数据传递的协议将给出
y
^
\hat{y}
y ^
y
y
y
假设每个权重矩阵
w
[
l
]
=
[
1.5
0
0
1.5
]
w^{[l]}=\left[\begin{matrix}1.5&0\\0&1.5\end{matrix}\right]
w [ l ] = [ 1 . 5 0 0 1 . 5 ]
y
=
w
[
1
]
[
1.5
0
0
1.5
]
(
L
−
1
)
x
y=w^{[1]}\left[\begin{matrix}1.5&0\\0&1.5\end{matrix}\right]^{(L-1)}x
y = w [ 1 ] [ 1 . 5 0 0 1 . 5 ] ( L − 1 ) x
y
^
\hat{y}
y ^
1.
5
(
L
−
1
)
x
1.5^{(L-1)}x
1 . 5 ( L − 1 ) x
L
L
L
y
^
\hat{y}
y ^
1.
5
L
1.5^L
1 . 5 L
y
y
y
相反的,如果权重是0.5,
w
[
l
]
=
[
0.5
0
0
0.5
]
w^{[l]}=\left[\begin{matrix}0.5&0\\0&0.5\end{matrix}\right]
w [ l ] = [ 0 . 5 0 0 0 . 5 ]
0.
5
L
0.5^L
0 . 5 L
y
=
w
[
1
]
[
1.5
0
0
1.5
]
(
L
−
1
)
x
y=w^{[1]}\left[\begin{matrix}1.5&0\\0&1.5\end{matrix}\right]^{(L-1)}x
y = w [ 1 ] [ 1 . 5 0 0 1 . 5 ] ( L − 1 ) x
w
[
L
]
w^{[L]}
w [ L ]
x
1
x_1
x 1
x
2
x_2
x 2
1
2
\frac12
2 1
1
2
\frac12
2 1
1
4
\frac14
4 1
1
4
\frac14
4 1
1
8
\frac18
8 1
1
8
\frac18
8 1
1
2
L
\frac1{2^L}
2 L 1
我希望你得到的直观理解是,权重
w
w
w
w
w
w
[
0.9
0
0
0.9
]
\left[\begin{matrix}0.9&0\\0&0.9\end{matrix}\right]
[ 0 . 9 0 0 0 . 9 ]
在深度神经网络中,激活函数将以指数级递减,虽然我只是讨论了激活函数以与
L
L
L
L
L
L
对于当前的神经网络,假设
L
=
150
L=150
L = 1 5 0
L
L
L
L
L
L
总结一下,我们讲了深度神经网络是如何产生梯度消失或爆炸问题的,实际上,在很长一段时间内,它曾是训练深度神经网络的阻力,虽然有一个不能彻底解决此问题的解决方案,但是已在如何选择初始化权重问题上提供了很多帮助。