3.8 介绍:softmax 回归
softmax回归虽然叫‘回归’,但和logistic回归一样,其实是分类问题,和logistic回归不同的是, logistic回归是二分类问题,而softmax回归解决的是多分类问题,如下图所示:


假设我们需要学习器将图片分类,1表示猫,2表示狗,3表示小鸡,0表示其他。在softmax回归中,类别数C=4,输出层我们也称为softmax layer。既然是多分类问题,我们希望输出的结果是分为不同类别的概率,且希望概率和为1,如上图所示,我们希望softmax layer第一个节点输出x属于其他的概率,第二个节点输出x属于猫的概率等,输出层节点个数就是类别个数,即是一个4维向量。
softmax layer具体计算过程如下图所示:

因为希望概率和为1,所以softmax layer采用了softmax激活函数,不同于其他激活函数,它的作用就是保证概率和为1。
具体实现如上图所示:通过上一层计算得到
,
是一个4维向量,对
的每一个元素进行指数操作(elementwise),记为临时变量t,t也是一个4维向量,令
,
也是一个4维向量,具体为
。通过softmax激活函数,得到满足条件的输出结果
,即每一个元素表示分为某一类别的概率,且所有元素和相加为1。具体实例如上图右侧所示。
softmax激活函数相比其他激活函数特殊的地方在于,比如ReLU和sigmoid激活函数每次都是处理一个实数值(real value),且输出一个实数值,但是softmax激活函数作用的对象是向量,输出的结果也是向量,且该向量的维度是多分类的类别数。
这里列了一些没有隐藏层的神经网络softmax多分类的分类结果,如下图所示。

在没有隐藏层的情况下,softmax分类器是线性分类器,就像logistic回归一样,LR也是一个线性分类器,且针对二分类。LR为什么是线性分类器,这里简单讲一下。前提假设,
。若
,即
,则将X判为正类,而
,两边取对数得,
,即若
,就把X分为正类,可见LR分界面为线性分界面,所以LR是线性分类器。
softmax分类器也是同理,因为softmax激活函数做的变换也是指数变换,只不过要选取概率最大的那一类,这就需要两两比较,所以如上图所示,每两类之间分界面都是线性的,比如第一类和第二类比较,分界面是。
当然如果神经网络加入很多隐藏层,我们就可以得到更加复杂的非线性分界面了。
3.9 实战:如何训练softmax分类器

上图用实例表现了softmax激活函数的工作,3.8节我们也已经详细描述过了,这里主要讲一下为什么我们称其为‘softmax’。‘softmax’对应于‘hardmax’,因为softmax回归其实是多分类问题,所以hardmax指的是输出结果不是概率,而直接就是0或1,1表示属于这一类,0表示不属于,对应与hard的soft表示的就是输出结果为概率啦。那max在这里表示什么呢?这个对应于激活函数中我们做指数变换,因为指数函数是单增函数,所以其实越大,他所对应的
就越大,因为分母都一样,如上图实例中元素5,这就是softmax中max含义。
softmax回归其实是logistic回归由二分类向多分类的推广,因为应用于没有隐藏层的神经网络,这二者都是线性分类器(3.8已证明),本质上也可以表现这一点。而当softmax回归中的种类个数C等于2时,softmax回归也就退化成logistic回归,因为按照softmax回归方法去计算X归属于两类的概率,因为只有两类且概率和为1,所以也可以直接按照logistic回归方法,即x归属另一类概率为1-y,两种方法本质是一样的。
既然softmax回归是logistic回归的推广,那softmax回归的loss function是怎样的呢?如下图所示:

老师这里通过实例给误差函数一种intuition的理解方式,即loss function如上图所示,还是3.8中的例子,假设我们的实际label是(0;1;0;0),即图片中是一只猫,但预测结果是(0.3;0.2;0.1;0.4),即预测该图片是一只猫的概率是0.2,预测结果很不好。loss function的intuition理解是怎么的呢?我们定义的损失函数如上图所示,在图片是猫的情况下,
,
就变为
,我们希望损失函数值越小越好,那就是希望
能够越大越好,也就是将图片预测为猫的概率越大越好,这一切分析是说得通的。
但我想从数学层面来讲一下这里损失函数的定义方法,理解LR损失函数的同学应该能够很容易理解这里为什么这么定义,所以我先讲一下LR损失函数的定义方法。为了更好地过渡到多分类问题,这里定义使用老师的定义方法,即表示将X判为第j类的概率,
表示X真实label。在LR问题中,我们直觉会希望
值越大越好,因为若X属于第一类,
=
,即我们希望X预测为第一类的概率越高越好,同理预测为第二类也是这样。然后对
作log处理,得到
,即我们希望这个值越大越好,但一般损失函数我们都希望越小越好,求最小值,所以这里取相反数,即loss function为
,同多分类loss function相同,背后的数学思想就是这样的。
当然这个loss function表示形式针对的是一个X,对于所有样本,目标函数还要对m个样本求和得到J,如上图所示,所以我们的目标就是求目标函数的最小值。
注意真实label Y矩阵和矩阵的不同,Y矩阵的每一列是样本m所属类别的one-hot编码,除了所属类别为1,其余位置都为0,而
矩阵的每一列就是样本m输出结果,表示将样本判为每一类别的概率。
接下来讲一下softmax在神经网络中实现梯度下降,如下图所示:
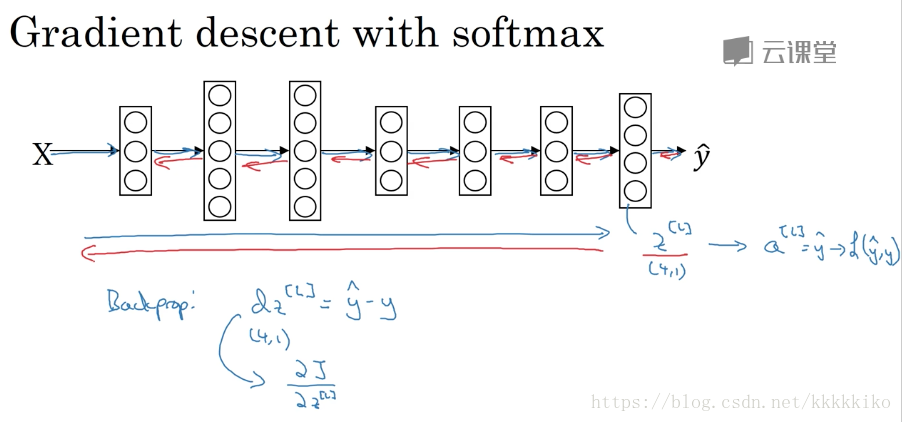
向前传播还好,其实主要是向后传播梯度如何计算,在softmax回归中,通过softmax激活函数将变为
,
就是loss function中
。之前在backprop选修那一小节,老师推导过LR情况下(即最后一层激活函数是sigmoid)
,softmax情况下也是一样,我们来推导一下。
直接将值代入
得到
与
的关系式,即
,L对
求导得
,所以
。梯度结果也在本质上反映出softmax回归是logistic回归的推广。
若我们使用深度学习框架,可以不考虑向后传播,只要保证正确进行向前传播,框架可以直接计算梯度下降需要的梯度。
版权声明:尊重博主原创文章,转载请注明出处https://blog.csdn.net/kkkkkiko/article/details/81564578