结构化机器学习项目
机器学习策略(ML Strategy)1
一、机器学习策略介绍(Introduction to ML Strategy)
1、机器学习策略
就是超参数调优的策略,怎么调?怎们评估调优的效果?调哪些超参的效果更好?超参数调优的次序?
下图是一些经常调优的超参:

2、正交化(Orthogonalization)
正交化或正交性是一种系统设计属性,可确保修改算法的某一部分不会对系统的其他部分产生或传播副作用。 它使得相互独立验证算法变得更加容易,且减少了测试和开发时间。
(Orthogonalization or orthogonality is a system design property that assures that modifying an instruction or a component of an algorithm will not create or propagate side effects to other components of the system. It becomes easier to verify the algorithms independently from one another, it reduces testing and development time.)
其实就是类似于我们做实验时的控制变量法,一次只调优一个超参,保持其它超参不变,超参相互独立。
当设计一个监督型的学习模型时,下面的4个假设需要成立且相互正交。
(When a supervised learning system is design, these are the 4 assumptions that needs to be true and orthogonal.)
(1) Fit training set well in cost function
If it doesn’t fit well, the use of a bigger neural network or switching to a better optimization algorithm might help.
(2)Fit development set well on cost function
If it doesn’t fit well, regularization or using bigger training set might help.
(3)Fit test set well on cost function
If it doesn’t fit well, the use of a bigger development set might help
(4)Performs well in real world
If it doesn’t perform well, the development test set is not set correctly or the cost function is not evaluating the right thing.
二、设置优化目标(Setting up your goal)
1、单一数字评估指标(Single number evaluation metric)

查准率 (Precision);查全率 (Recall);F1-Score:查准率与查全率的 trade off;

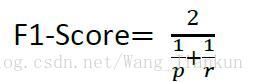
如果同时关注 precision 和 recall 两个指标,很难对算法效果做出判断。所以通常以F1-Score作为评估算法效果的单一指标。F1-Score 越大效果越好。

有时候也会把平均数作为单一数字评估指标:
下表的百分比表示误差,所以平均误差越小越好

2、设置满足和优化目标(Satisficing and Optimizing metrics)
满足目标:只要达到要求就行,不一定得很好
优化目标:尽可能的达到最好,不断优化。

分类器的性能有许多不同的评估指标,称为评估矩阵。它们可以归类为满足矩阵和优化矩阵。要注意,这些评估指标必须在训练集、开发集或测试集上进行评估。
(There are different metrics to evaluate the performance of a classifier, they are called evaluation matrices. They can be categorized as satisficing and optimizing matrices. It is important to note that these evaluation matrices must be evaluated on a training set, a development set or on the test set.)
一般的(general),如果要有N个指标,通常选择其中一个指标为优化指标,其它的N-1个指标为满足指标:

以算法的运行时间(Running time)和准确率(Accuracy)为例,通常运行时间只需要满足一定要求即可,如<100ms; 而准确率越高越好;所以把运行时间设为满足目标,准确率设为优化目标。
三、设置训练、开发、测试集(Setting up training、development and test sets)
1、开发、测试集中的数据选择建议
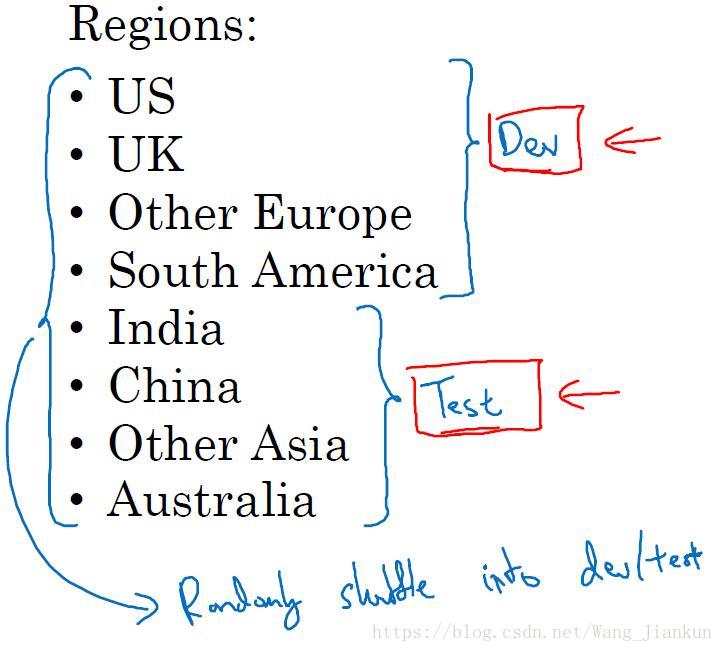
- 开发集和测试集要来自同一分布 (same distribution )且随机选择样本 (randomly select)
例:数据来自不同区域,开发集和测试集的数据选择不能使两个数据集分别从不同的某几个地区选取。正确的做法是在所有的地区中随机选择样本来分配给开发集和测试集。
- 开发集和测试集中的数据最好能反应未来的数据(Choose a development set and test set to reflect data you expect to get in the future and consider important to do well)
2、训练、开发、测试集中的数据量(size)
训练集: 越大越好
开发集: 不用太大,够用就行,主要用来评估不同模型的效果,能区分不同模型的的差别即可。
测试集:视应用目标而定,越大置信度越高,一般不用太大。
三、修改评估指标或开发、测试集
1、开发模型也可以看做是Orthogonalization
首先,设置优化目标(评估指标),类比于靶心。
然后,不断的优化向优化目标逼近,类比瞄准靶心发射。

2、修改评估指标
当我们的算法中不允许包含某一向错误时,我们就要修改评价指标(错误率),给这项错误设置一个很大的权重,这样算法为了减小错误率会优先减小这项错误的产生。

3、修改开发、测试集
如果在训练开发测试的过程中得到的模型效果比较好,但是在实际应用中效果却不好的时候,就需要改变开发、测试集或者评估指标。例:当开发、测试集是高质量的图片而应用中用户的是低质量的图片时法,算法效果比较差。这时候应该把改变开发、测试集应为随机选择高低质量的图片。

四、人类表现比较(Comparing to human-level performance)
1.人类水平和贝叶斯最优误差
人类水平(Human level):对于某项任务,人类能达到的准确率。人类误差不是固定值,因为普通人和专家是有区别的,人为水平的定义取决于分析的目的和应用场景而定。

贝叶斯最优误差(Bayes optimal error):对于某项任务,理论上能达到的准确率,一定优于人类水平。
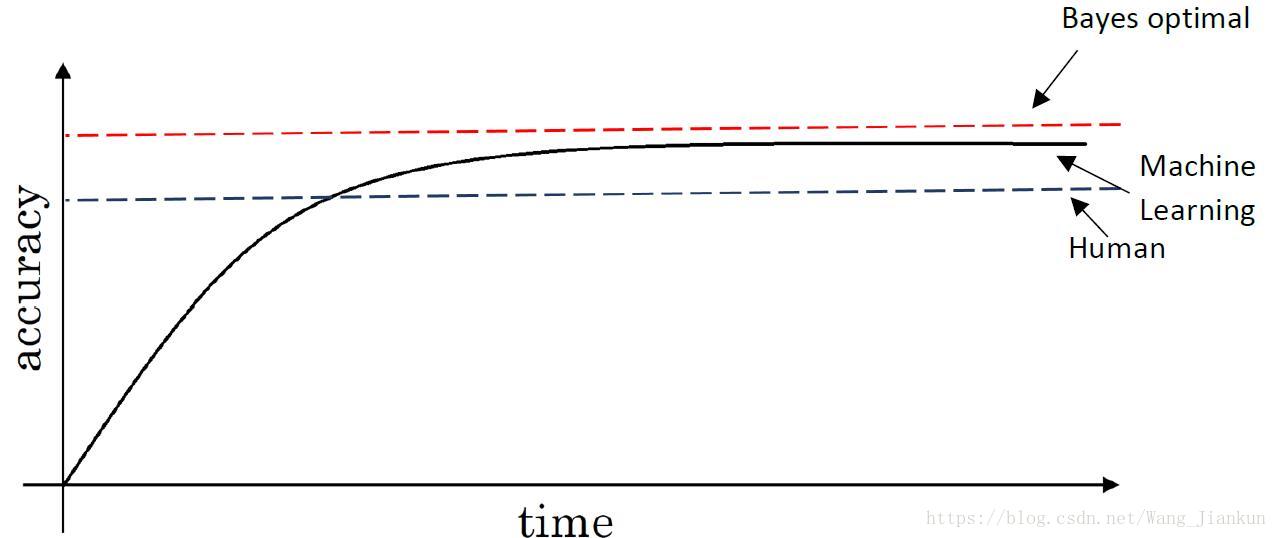
通常在语音识别、计算机视觉中可以把贝叶斯最优误差约等于人类误差,因为人类很擅长这方面的处理。
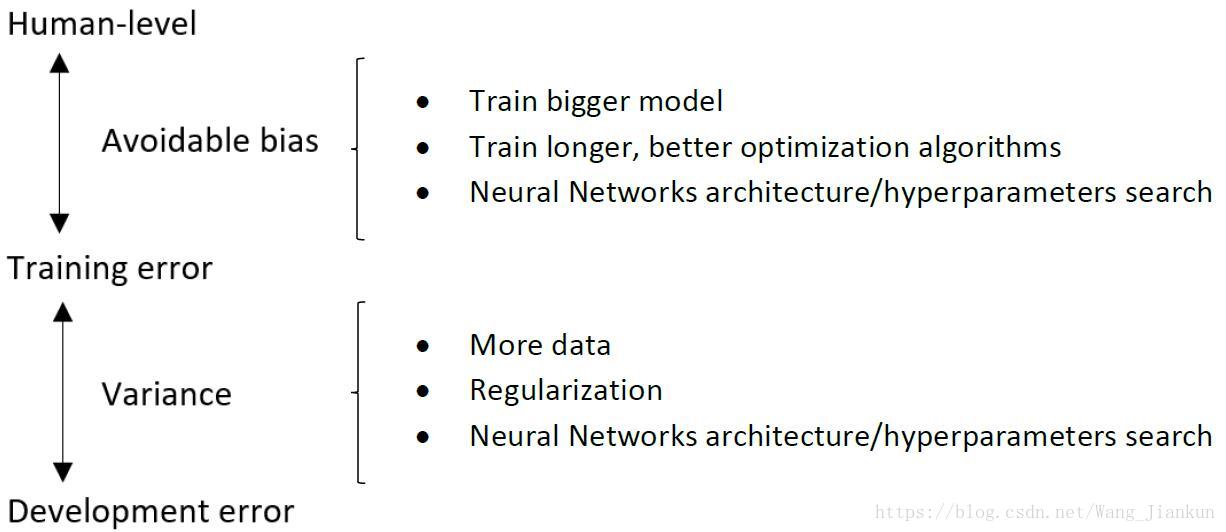
可避免的偏差(Avoidable bias)和方差variance:
可避免的偏差:人类水平或贝叶斯与训练集误差的差
方差:开发集与训练集误差的差。

哪个大优先优化即减小哪个,因为可提升的空间较大。
超过人的表现(Surpassing human-level performance)
以下是目前机器学习超过人类水平的几个方面,它们基本上是结构化数据的学习,因为计算机擅长于与数值计算与统计,而且数据量大,所以表现比人好。但在非结构化数据的学习方面,目前在这方面的学习超过人类水平的应用并不多,大部分还无法超过人类。

改善模型的表现(Improving your model performance)
Two fundamental assumptions of supervised learning:
- The first one is to have a low avoidable bias which means that the training set fits well.
- The second one is to have a low or acceptable variance which means that the training set performance generalizes well to the development set and test set.
不满足这两个假设的改进方法: