0. 承前启后
通过学习前两篇文章如何搭建LSTM和如何理解LSTM的输入输出格式之后我们以此为基础开始学习如何训练LSTM。
1. 定义LSTM的结构
rnn = torch.nn.LSTM(30, 1, 2, batch_first=True) #(input_size,hidden_size,num_layers)
input = train_y #(seq_len, batch, input_size)
h0 = torch.randn(2, 193, 1) #(num_layers,batch,hidden_size)
c0 = torch.randn(2, 193, 1) #(num_layers,batch,hidden_size)
rnn = torch.nn.LSTM(30, 1, 2, batch_first=True)
这里定义了这个LSTM的几个参数:
输入数据的大小为30,即input_size=10,也就是说每个周期输入一个大小为30的数据向量
隐藏层的大小为1,即hidden_size=1
LSTM的层数为2,即num_layers=2
输入的形状本来是(seq_len,batch,input_size),当设定batch_first=True时表示输入的的形状变为(batch,seq_len,input_size),与此同时输出的形状也从(seq_len,batch,num_directionshidden_size)变为了(batch,seq_len,num_directionshidden_size)
input = train_y #(seq_len, batch, input_size)
将输入的张量按照((seq_len, batch, input_size))的形状来排好之后赋给input,
这里seq_len* batch*input_size=input的元素总数
接下来将根据使用时会遇到的两种输入情况来分析一下:
(1)如果最原始的输入为一维的数据,比如在预测股票的时候最原始的输入为每日最高股价随天数变化的序列,这时候的最原始输入即为一维的。
这时候第一步一般会将这个一维数据先变成一个二维数据,比如:
最原始的一维数据:
[ 10.52 14.62 5.48 9.35 3.91 9.35 3.91 14.62 14.62 3.91
7.05 5.48 3.91 7.05 10.52 10.52 14.62 10.52 7.05 14.62]
设每10个为1组化为二维张量:
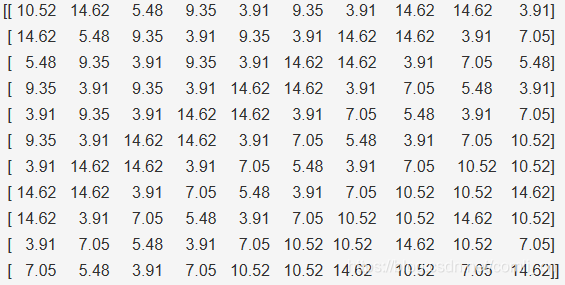
这样变换之后再给每一行数据对应一个target值,也就是说这个LSTM会根据10个连续的序列值来学习一个目标值。
但是LSTM的输入值要求是一个三维的张量即(seq_len, batch, input_size),这时候我们还要将上述的二维张量进行重构,使其变为三维的张量。(重构的方法参考张量操作)
这里我们令seq_len=11;input_size=10;批量操作意思是我们进行几次前向计算再进行反向计算来更新权值,拿上面的数据来说,因为变成二维的数据之后20个数据变成了11行,所以批量操作的话,比如我们选定batch=3,那么就会每计算完上面二维张量的三行更新一次权值,最后剩下两行就会计算完这两行再更新权值,但因为前面seq_len=11,input_size=10所以batch=1(更深入的理解请看如何理解LSTM的输入输出格式)
(2)如果最原始的输入为二维的数据,比如在对一个句子中的单词进行词性识别的时候,我们会用一个属性向量来描述一个单词,所以这时候最原始的输入的一个句子就变成了一个二维的矩阵。
例如:
最原始的数据
data_ = [[1, 10, 11, 15, 9, 100],
[2, 11, 12, 16, 9, 100],
[3, 12, 13, 17, 9, 100],
[4, 13, 14, 18, 9, 100],
[5, 14, 15, 19, 9, 100],
[6, 15, 16, 10, 9, 100],
[7, 15, 16, 10, 9, 100],
[8, 15, 16, 10, 9, 100],
[9, 15, 16, 10, 9, 100],
[10, 15, 16, 10, 9, 100]]
这里面每一行代表一个单词,同样的需要把它重构为3为张量,这时候我们就可以设置input的结构值了,比如当seq_len=2,batch=5,input_size=6时
我们的第一个batch为:
tensor([[ 1., 10., 11., 15., 9., 100.],
[ 2., 11., 12., 16., 9., 100.]]
最后一个batch为:
tensor([[ 9., 15., 16., 10., 9., 100.],
[ 10., 15., 16., 10., 9., 100.]])
其中batch=2批量操作意思是我们进行几次前向计算再进行反向计算来更新权值
h0 = torch.randn(2, 193, 1) #(num_layers,batch,hidden_size)
这里的hidden_size要根据想要的output的形状来定,比如我想让输出是一个一维的向量,那么hidden_size=1,如果想让输出为二维的矩阵,则hidden_size的值为这个矩阵第二维的大小,比如输出为3*5,则hidden_size=5。
c0 = torch.randn(2, 193, 1) #(num_layers,batch,hidden_size)
c0与h0是完全相同的
2. 正向计算
output, (hn, cn) = rnn(input, (h0, c0))
3. 选择优化器和损失函数
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.MSELoss()
4. 多次正向反向计算更新参数
for step in range(EPOCH):
output,(hn, cn)= rnn(input,(h0, c0))
loss = loss_func(output, train_target_nom)
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # back propagation, compute gradients
optimizer.step()
5. 将输出output转换为想要的形式
因为output是个三维的张量,但是我们最后不一定要这种类型的结果,所以要变换。
例如变为二维的输出:
output=output.view(193,-1)
