pytorch如何使用torchtext初始化LSTM的embedding层?
由于我开始使用的是torchtext这个预处理的工具,使得建立词典,初始化embedding变得非常方便,一般下面几行就可以搞定调用预训练glove词向量模型初始化embedding。
vectors = Vectors(name='./vector/glove.6B.50d.txt') # 存放50d的glove词向量
TEXT.build_vocab(train_data, vectors=vectors)
self.vocab = TEXT.vocab # 获取字典
self.pretrained_embedding = TEXT.vocab.vectors # 保存词向量
model.embeddings.weight.data.copy_(dataset.pretrained_embedding) # 使用训练好的词向量初始化embedding层
这里比较断章取义,但是意思到位,详细操作可以看加载glove或者word2vec训练好的词向量进行训练LSTM等模型的训练
这样的工具虽然用起来十分迅速,但是封装的越好,调整起来就越头大,因为torchtext并不支持bert等预训练模型,因此如果我既想用torchtext来数据预处理,又想用bert预训练模型来初始化embedding,那该怎么办呢?
首先,我们需要清楚pytorch里是如何初始化LSTM的embedding的。
举个例子就知道了(下面只是我代码中的一部分,不可以直接运行,看缩进就知道了),但是我会详细解释这段代码的输出。
我的思路:首先应该清楚embedding层就是相当于字典中每个词的词向量,可以在训练中不断更新,也可以冻结不进行更新。那么如果其实初始化最好的思路就是按照字典的顺序下来,构造[len(字典), len(词向量)]的一个二维tensor矩阵初始化就可以了。事实上确实如此。
vectors = Vectors(name='./vector/glove.6B.50d.txt') # 存放50d的glove词向量
TEXT.build_vocab(train_data, vectors=vectors)
self.vocab = TEXT.vocab # 获取字典
self.pretrained_embedding = TEXT.vocab.vectors # 保存词向量
print("字典大小", len(self.vocab))
print("字典词向量大小", self.pretrained_embedding.shape)
print("len(self.vocab.itos)", len(self.vocab.itos))
print("举例")
print("self.vocab.itos[:5]",self.vocab.itos[:5])
dic = ['<unk>', '<pad>', 'the', 'a', 'and']
for i in range(5):
# 输出初始化embedding矩阵的第i行
print("self.pretrained_embedding["+str(i)+", :]",self.pretrained_embedding[i, :])
# 输出字典的第i个词
print(self.vocab.itos[i])
# 输出字典的第i个词的索引
print(self.vocab.stoi[dic[i]])
# 获取对应单词的词向量
print("vectors.get_vecs_by_tokens([dic["+str(i)+"]]",vectors.get_vecs_by_tokens([dic[i]], lower_case_backup=True))
print(self.pretrained_embedding)
print("字典大小", len(self.vocab))
print("字典词向量大小", self.pretrained_embedding.shape)
print("len(self.vocab.itos)", len(self.vocab.itos))
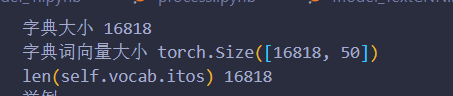
这一段对应的输出如上所示,字典大小就是我放入训练文本的所有词建立的字典,一共有16818个不同的词,由于我是使用50维的glove词向量,那么对应字典大小就是 16818 * 50( [len(字典), len(词向量)] )self.vocab.itos就是字典中所有词的一个列表,长度为16818。
print("举例")
print("self.vocab.itos[:5]",self.vocab.itos[:5])
dic = ['<unk>', '<pad>', 'the', 'a', 'and']

这一段对应的输出如上所示,取出字典前5个单词,发现第3个词开始才是有意义的词。
for i in range(5):
# 输出初始化embedding矩阵的第i行
print("self.pretrained_embedding["+str(i)+", :]",self.pretrained_embedding[i, :])
# 输出字典的第i个词
print(self.vocab.itos[i])
# 输出字典的第i个词的索引
print(self.vocab.stoi[dic[i]])
# 获取对应单词的词向量
这一段的思路就是验证之前的想法,初始化embedding矩阵就是按照字典编号下来的。

第1、2个字符(对应子弹编号就是0,1)就是<unk>,<pad>分别用来表示未知字符和填充,由于是特殊的字符,无实际意义,因此用全0来表示。

当看到第三个字符”the“的时候,可以发现,他在字典中的索引为2,即第三个元素,这个词的词向量就在embedding矩阵的第3行(索引为[2, :])
那么可以以此类推
 "a"在第四个位置
"a"在第四个位置

”and“在第五个位置
print(self.pretrained_embedding)
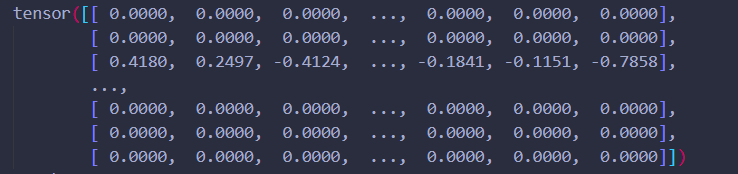
因此在torchtext中初始化embedding的矩阵其实就是按照字典序依次排列成的二维矩阵。(不用torchtext应该也一样吧)
如何用各种预训练模型初始化embedding层?
那么清楚了torchtext初始化embedding的操作,如何使用各种预训练模型来初始化就变得十分简单了。
例如Bert预训练模型默认768维,因为torchtext默认不支持,那么需要自己构造embedding矩阵来初始化,构造思路就是先获取torchtext中的字典,然后遍历获取对应Bert的词向量,构造按字典序编排的词向量矩阵,最后用这个矩阵来初始化embedding层,就达到了使用Bert预训练模型来初始化的目的了。那么对于预训练模型,操作也是类似。
不过我还没这么操作过,因为之前有这个疑问,感觉按我这套思路应该可以解决,因为之前用来Bert预训练模型来训练究极满,等下次有需求了再来补代码吧
可以贴上调用Bert的代码(英文预训练模型):
from transformers import BertTokenizer
tokenizer=BertTokenizer.from_pretrained('bert-base-uncased')
print(len(tokenizer))
token=tokenizer.tokenize("Don't Make sUch a fuss,get StUFf!")
print(token)
indexes=tokenizer.convert_tokens_to_ids(token)
print(indexes)