相关文章:
LSTM 01:理解LSTM网络及训练方法
LSTM 02:如何为LSTMs准备数据
LSTM 03:如何使用Keras编写LSTMs
LSTM 04:4种序列预测模型及Keras实现
LSTM 05:如何开发 Vanilla LSTMs 和 Stacked LSTMs
LSTM 06:如何用Keras开发CNN LSTM
LSTM 07:如何用Keras开发 Encoder-Decoder LSTM
文章目录
- 相关文章:
- 6. How to Develop Vanilla LSTMs
- 6.1 The Vanilla LSTM
- 6.2 Echo Sequence Prediction Problem
- 6.2.1 Generate Random Sequences
- 6.2.2 One Hot Encode Sequences
- 6.2.3 Worked Example
- 6.2.4 Reshape Sequences
- 6.3 Define and Compile the Model
- 6.4
- 6.5 Evaluate the Model
- 6.6 Make Predictions With the Model
- 6.7 Complete Example
- 7. How to Develop Stacked LSTMs
6. How to Develop Vanilla LSTMs
本课程的目的是学习如何开发和评估Vanilla LSTM模型。完成本课程后,您将知道:
- 用于序列预测的Vanilla LSTM的体系结构及其一般功能。
- 如何定义和实现回声序列预测问题。
- 如何开发香草LSTM,以学习回声序列预测问题并做出准确的预测。
6.1 The Vanilla LSTM
6.1.1 Architecture
Vanilla LSTM是一种简单的LSTM形式。本书中将其命名为Vanilla(香草),以将其与更深的LSTM和更复杂的配置模型区分开。在最初的1997年LSTM论文中定义的是LSTM体系结构,该体系结构将在大多数小序列预测问题上给出良好的结果。香草LSTM定义为:
- Input layer.
- Fully connected LSTM hidden layer.
- Fully connected output layer.
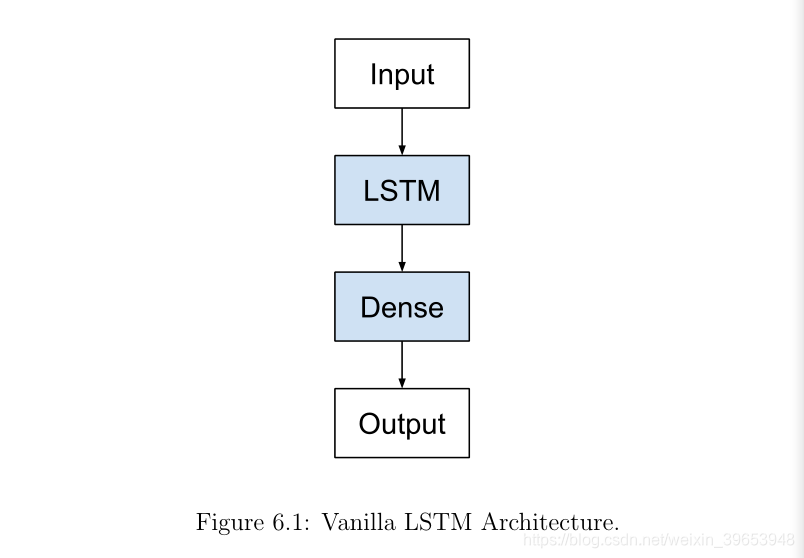
6.1.2 Implementation
在Keras中,以下定义了Vanilla LSTM,其中省略号表示每层神经元数量的特定配置。
model = Sequential()
model.add(LSTM(..., input_shape=(...)))
model.add(Dense(...))
这是在深度学习中有关LSTM的许多工作和讨论中引用的默认LSTM或标准LSTM,也是在序列预测问题上开始使用LSTM的良好起点。香草LSTM具有以下5种吸引人的特性,其中大部分已在原始论文中得到证明:
- 序列分类取决于多个分布式输入时间步长。
- 可以存储数千个时间步长的精确输入观测值。
- 根据先前时间步长进行序列预测。
- 在输入序列上插入随机时间步的鲁棒性。
- 可靠地将信号数据放置在输入序列上。
6.2 Echo Sequence Prediction Problem
回波(echo)序列预测问题是用于证明香草LSTM的存储能力的人为问题。任务是在给定随机整数序列作为输入的情况下,在未指定给模型的特定时间输入步骤处输出随机整数的值。
例如,给定随机整数[5、3、2]的输入序列,而所选的时间步长是第二个值,则预期输出为3。从技术上讲,这是一个序列分类问题。它被表述为多对一预测问题,在序列末尾有多个输入时间步长和一个输出时间步长。
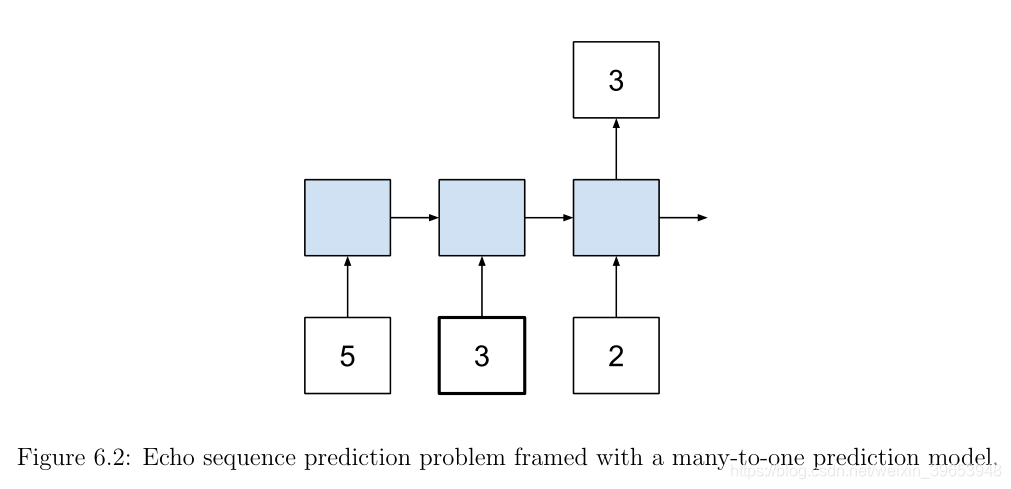
精心选择了这个问题,以证明Vanilla LSTM的存储能力。此外,我们将手动执行模型生命周期中的某些元素,例如拟合和评估模型,以便更深入地了解幕后情况。接下来,我们将开发代码来生成此问题的示例。这涉及以下步骤:
- Generate Random Sequences.
- One Hot Encode Sequences.
- Worked Example
- Reshape Sequences.
6.2.1 Generate Random Sequences
我们可以使用randint() 函数在Python中生成随机整数,该函数采用两个参数来指示从中绘制值的整数范围。在本课程中,我们将问题定义为具有0到99之间的整数值和100个唯一值。
randint(0, 99)
我们可以将其放在一个名为generate_sequence() 的函数中,该函数将生成所需长度的随机整数序列。此功能在下面列出。
# generate a sequence of random numbers in [0, n_features)
def generate_sequence(length, n_features):
return [randint(0, n_features-1) for _ in range(length)]
6.2.2 One Hot Encode Sequences
生成随机整数序列后,我们需要将其转换为适合训练LSTM网络的格式。一种选择是将整数重新缩放为[0,1]范围。这将奏效,并要求将问题表述为回归。
我们感兴趣的是预测正确的数字,而不是接近期望值的数字。这意味着我们宁愿将问题归类为分类而不是回归,因为预期输出是一个类,并且有100个可能的类值。在这种情况下,我们可以对整数值使用一种热编码,其中每个值都由一个100个元素的二进制矢量表示,除整数的索引标记为1之外,该矢量全部为0值。
下面的函数称为一个hot_encode(),它定义了如何对整数序列进行迭代并为每个整数创建二进制矢量表示,然后将结果作为二维数组返回。
# one hot encode sequence
def one_hot_encode(sequence, n_features):
encoding = list()
for value in sequence:
vector = [0 for _ in range(n_features)]
vector[value] = 1
encoding.append(vector)
return array(encoding)
我们还需要对编码值进行解码,以便可以利用预测。在这种情况下,只需对其进行审查。可以使用argmax() NumPy函数反转一次热编码,该函数返回向量中具有最大值的值的索引。下面的函数被称为一个hot_encode(),它将对编码序列进行解码,并可用于以后对来自我们网络的预测进行解码。
# decode a one hot encoded string
def one_hot_decode(encoded_seq):
return [argmax(vector) for vector in encoded_seq]
6.2.3 Worked Example
我们可以将所有这些结合在一起。以下是生成25个随机整数的序列并将每个整数编码为二进制向量的完整代码列表。
from random import randint
from numpy import array
from numpy import argmax
# generate a sequence of random numbers in [0, n_features)
def generate_sequence(length, n_features):
return [randint(0, n_features-1) for _ in range(length)]
# one hot encode sequence
def one_hot_encode(sequence, n_features):
encoding = list()
for value in sequence:
vector = [0 for _ in range(n_features)]
vector[value] = 1
encoding.append(vector)
return array(encoding)
# decode a one hot encoded string
def one_hot_decode(encoded_seq):
return [argmax(vector) for vector in encoded_seq]
# generate random sequence
sequence = generate_sequence(25, 100)
print(sequence)
# one hot encode
encoded = one_hot_encode(sequence, 100)
print(encoded)
# one hot decode
decoded = one_hot_decode(encoded)
print(decoded)
运行示例首先显示25个随机整数的列表,然后是该序列中所有整数的二进制表示的截断视图,每行一个矢量,然后再次显示解码后的序列。您可能会得到不同的结果,因为每次运行代码时都会生成不同的随机整数。
[37, 99, 40, 98, 44, 27, 99, 18, 52, 97, 46, 39, 60, 13, 66, 29, 26, 4, 65, 85, 29, 88, 8,
23, 61]
[[0 0 0 ..., 0 0 0]
[0 0 0 ..., 0 0 1]
[0 0 0 ..., 0 0 0]
...,
[0 0 0 ..., 0 0 0]
[0 0 0 ..., 0 0 0]
[0 0 0 ..., 0 0 0]]
[37, 99, 40, 98, 44, 27, 99, 18, 52, 97, 46, 39, 60, 13, 66, 29, 26, 4, 65, 85, 29, 88, 8,
23, 61]
6.2.4 Reshape Sequences
最后一步是将一个热编码序列整形为可以用作LSTM输入的格式。这涉及将编码序列重塑为具有n个时间步长和k个特征,其中n是生成的序列中整数的数量,k是每个时间步长(例如100)的可能整数的集合。
一个或一个25 100整数的序列,或为25 100个整数的单个序列[1]。如下:
X = encoded.reshape(1, 25, 100)
序列的输出只是在特定预定义位置的编码整数。对于一个模型生成的所有示例,此位置必须保持一致,以便模型可以学习。例如,通过直接从编码序列中获取编码值,我们可以将第二时间步长作为具有25个时间步长的序列的输出:
y = encoded[1, :]
我们可以将其与以上所有生成和编码步骤放在一起,称为一个名为generate_example()的新函数,该函数生成一个序列,对其进行编码,然后返回输入(X)和输出(y)。
# generate one example for an lstm
def generate_example(length, n_features, out_index):
# generate sequence
sequence = generate_sequence(length, n_features)
# one hot encode
encoded = one_hot_encode(sequence, n_features)
# reshape sequence to be 3D
X = encoded.reshape((1, length, n_features))
# select output
y = encoded[out_index].reshape(1, n_features)
return X, y
我们可以将所有这些放到一起,并测试准备好适合或评估LSTM的一个示例的生成,如下所示:
from random import randint
from numpy import array
from numpy import argmax
# generate a sequence of random numbers in [0, n_features)
def generate_sequence(length, n_features):
return [randint(0, n_features-1) for _ in range(length)]
# one hot encode sequence
def one_hot_encode(sequence, n_features):
encoding = list()
for value in sequence:
vector = [0 for _ in range(n_features)]
vector[value] = 1
encoding.append(vector)
return array(encoding)
# decode a one hot encoded string
def one_hot_decode(encoded_seq):
return [argmax(vector) for vector in encoded_seq]
# generate one example for an lstm
def generate_example(length, n_features, out_index):
# generate sequence
sequence = generate_sequence(length, n_features)
# one hot encode
encoded = one_hot_encode(sequence, n_features)
# reshape sequence to be 3D
X = encoded.reshape((1, length, n_features))
# select output
y = encoded[out_index].reshape(1, n_features)
return X, y
X, y = generate_example(25, 100, 2)
print(X.shape)
print(y.shape)
运行代码将生成一个编码序列,并打印出LSTM序列的输入和输出组件的形状。
(1, 25, 100)
(1, 100)
既然我们知道如何准备和表示整数的随机序列,我们可以看看使用LSTM来学习它们。
6.3 Define and Compile the Model
我们将从定义和编译模型开始。为了保持模型的小型化,并确保在合理的时间内进行拟合,我们将通过将序列长度减少到5个整数,将特征数减少到10(例如0-9)来大大简化问题。模型必须指定输入数据的预期维度。在这种情况下,根据时间步time steps(5)和特征features(10)。我们将使用一个单一的隐藏层LSTM与25个记忆单元,选择了一个小的尝试和错误。
输出层是一全连接层(密集层),对于可能输出的10个整数,有10个神经元。在输出层使用softmax激活函数,允许网络学习和输出可能输出值的分布。
该网络将在训练时使用对数损失函数,适用于多类分类问题,并采用高效的Adam优化算法。准确率指标将在每个训练阶段报告,以便了解模型的技能以及损失。
# define model
length = 5
n_features = 10
out_index = 2
model = Sequential()
model.add(LSTM(25, input_shape=(length, n_features)))
model.add(Dense(n_features, activation= softmax ))
model.compile(loss= categorical_crossentropy , optimizer= adam , metrics=[ acc ])
print(model.summary())
运行示例将定义并编译模型,然后打印模型结构的摘要。通常,打印模型结构的摘要是一个很好的做法,以确认已按预期定义并编译了模型。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 25) 3600
_________________________________________________________________
dense_1 (Dense) (None, 10) 260
=================================================================
Total params: 3,860
Trainable params: 3,860
Non-trainable params: 0
_________________________________________________________________
6.4
我们现在可以在示例序列上拟合模型。我们为echo序列预测问题开发的代码生成随机序列。我们可以生成大量的示例序列,并将它们传递给模型的fit()函数。数据集将被加载到内存中,训练将是快速的,我们可以用不同数量的epoch与数据集的大小和批量进行实验。
一种更简单的方法是手动管理训练过程,其中生成一个训练样本并用于更新模型,并清除所有内部状态。时期数是生成样本的迭代数,并且批大小实质上是1个样本。以下是通过反复试验发现的10,000个时期拟合模型的示例。
# fit model
for i in range(10000):
X, y = generate_example(length, n_features, out_index)
model.fit(X, y, epochs=1, verbose=2)
拟合模型将报告每种模式的对数损失和准确性。在这里,准确性是0或1(0%或100%),因为我们要对一个样本进行序列分类预测并报告结果。
...
Epoch 1/1
0s - loss: 0.1610 - acc: 1.0000
Epoch 1/1
0s - loss: 0.0288 - acc: 1.0000
Epoch 1/1
0s - loss: 0.0166 - acc: 1.0000
Epoch 1/1
0s - loss: 0.0013 - acc: 1.0000
Epoch 1/1
0s - loss: 0.0244 - acc: 1.0000
6.5 Evaluate the Model
一旦模型拟合,我们就可以在对新的随机序列进行分类时估计模型的技巧。我们可以通过简单地对100个随机生成的序列进行预测并计算正确预测的次数来做到这一点。
与拟合模型一样,我们可以生成大量示例,将它们连接在一起,并使用evaluate()函数对模型进行求值。在这种情况下,我们将手动进行预测,并计算正确结果的数量。我们可以在生成样本、进行预测并在预测正确时递增计数器的循环中执行此操作。
# evaluate model
correct = 0
for i in range(100):
X, y = generate_example(length, n_features, out_index)
yhat = model.predict(X)
if one_hot_decode(yhat) == one_hot_decode(y):
correct += 1
print( Accuracy: %f % ((correct/100)*100.0))
评估模型会将模型的估计技能报告为100%。
Accuracy: 100.000000
6.6 Make Predictions With the Model
最后,我们可以使用拟合模型对新的随机产生的序列进行预测。对于这个问题,这与评估模型的情况基本相同。因为这更多的是面向用户的活动,我们可以解码整个序列、预期输出和预测,并将它们打印到屏幕上。
如果模型出错,不要惊慌。LSTMs是随机的,模型的一次运行可能会收敛到一个没有完全学习问题的解上。如果这种情况发生在你身上,试着再运行几个例子。
# prediction on new data
X, y = generate_example(length, n_features, out_index)
yhat = model.predict(X)
print( Sequence: %s % [one_hot_decode(x) for x in X])
print( Expected: %s % one_hot_decode(y))
print( Predicted: %s % one_hot_decode(yhat))
运行示例将打印解码后的随机生成的序列,预期结果以及(希望)满足预期值的预测。您的具体结果会有所不同。
Sequence: [[7, 0, 2, 6, 7]]
Expected: [2]
Predicted: [2]
6.7 Complete Example
from random import randint
from numpy import array
from numpy import argmax
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
# generate a sequence of random numbers in [0, n_features)
def generate_sequence(length, n_features):
return [randint(0, n_features-1) for _ in range(length)]
# one hot encode sequence
def one_hot_encode(sequence, n_features):
encoding = list()
for value in sequence:
vector = [0 for _ in range(n_features)]
vector[value] = 1
encoding.append(vector)
return array(encoding)
# decode a one hot encoded string
def one_hot_decode(encoded_seq):
return [argmax(vector) for vector in encoded_seq]
# generate one example for an lstm
def generate_example(length, n_features, out_index):
# generate sequence
sequence = generate_sequence(length, n_features)
# one hot encode
encoded = one_hot_encode(sequence, n_features)
# reshape sequence to be 3D
X = encoded.reshape((1, length, n_features))
# select output
y = encoded[out_index].reshape(1, n_features)
return X, y
# define model
length = 5
n_features = 10
out_index = 2
model = Sequential()
model.add(LSTM(25, input_shape=(length, n_features)))
model.add(Dense(n_features, activation= softmax ))
model.compile(loss= categorical_crossentropy , optimizer= adam , metrics=[ acc ])
print(model.summary())
# fit model
for i in range(10000):
X, y = generate_example(length, n_features, out_index)
model.fit(X, y, epochs=1, verbose=2)
# evaluate model
correct = 0
for i in range(100):
X, y = generate_example(length, n_features, out_index)
yhat = model.predict(X)
if one_hot_decode(yhat) == one_hot_decode(y):
correct += 1
print( Accuracy: %f % ((correct/100)*100.0))
# prediction on new data
X, y = generate_example(length, n_features, out_index)
yhat = model.predict(X)
print( Sequence: %s % [one_hot_decode(x) for x in X])
print( Expected: %s % one_hot_decode(y))
print( Predicted: %s % one_hot_decode(yhat))
7. How to Develop Stacked LSTMs
本节的目标是学习如何开发和评估堆叠的LSTM模型。完成本课程后,您将知道:
- 创建多层LSTM的动机以及如何在Keras中开发堆叠的LSTM模型。
- damped sine wave prediction problem及如何为拟合LSTM模型准备实例(examples)。
- 如何为damped sine wave prediction problem开发、拟合和评估堆叠的LSTM模型。
7.1 The Stacked LSTM
堆叠的LSTM是一个具有多个隐藏LSTM层的模型,其中每个层包含多个记忆单元(memory cell)。我们在这里将其称为堆叠LSTM(Stacked LSTM),以便将其与未堆叠的LSTM(Vanilla LSTM)和基本LSTM模型的各种其他扩展区分开来。
7.1.1 Why Increase Depth?
为一种深度学习技术,堆叠LSTM的隐藏层使模型更深,更准确地获得描述。神经网络的深度通常归因于该方法在一系列具有挑战性的预测问题上的成功。
[深度神经网络的成功]通常归因于由多个层引入的层次结构。每个层处理我们希望解决的任务的某些部分,并将其传递给下一个层。从这个意义上讲,DNN可以看作是一个处理管道,在这个管道中,每一层在将任务的一部分传递给下一层之前解决它,直到最后一层提供输出。— Training and Analyzing Deep Recurrent Neural Networks, 2013.
额外的隐藏层可以添加到多层感知器神经网络,使其更深。附加的隐藏层被理解为重新组合从先前层学习到的表示,并在高抽象级别创建新的表示。例如,从线条到形状再到对象。
一个足够大的单隐层多层感知器可以用来逼近大多数函数。增加网络的深度提供了另一种解决方案,它需要更少的神经元和更快的训练速度。最后,添加深度是一种表示优化。
深度学习是建立在一个深度的,层次化的假设的基础上的模型,在表示一些函数方面比一个浅的模型更有效。— How to Construct Deep Recurrent Neural Networks, 2013.
7.1.2 Architecture
LSTMs也可以利用同样的优势。考虑到LSTMs对序列数据进行操作,这意味着随着时间的推移,添加的层增加了输入观测的抽象级别。在等时技术中,随着时间的推移将观察结果分块或在不同的时间尺度上表示问题。
… 通过将多个重复的隐藏状态叠加在一起来构建一个深度RNN。这种方法可能允许每个级别的隐藏状态在不同的时间尺度下操作。— How to Construct Deep Recurrent Neural Networks, 2013.
Graves等人引入了叠层LSTMs或深层LSTMs。在将LSTMs应用于语音识别时,在一个具有挑战性的标准问题上超过了当时的基准(benchmark)。
RNN固有的时间深度,因为它们的隐藏状态是以前所有隐藏状态的函数。启发本文的问题是RNNs是否也能从空间的深度中受益,也就是说,像传统的深网络那样,将多个递归的隐藏层叠加在一起。— Speech Recognition With Deep Recurrent Neural Networks, 2013.
在同一项研究中,他们发现网络的深度比给定层中记忆单元的数量更重要。堆叠LSTMs是一种稳定的序列预测技术。堆叠的LSTM架构可以定义为由多个LSTM层组成的LSTM模型。上面的LSTM层提供序列输出,而不是一个值输出到下面的LSTM层。具体来说,每个输入时间步一个输出,而不是所有输入时间步对应一个输出时间步。

7.1.3 Implementation
我们可以在Keras中轻松创建Stacked LSTM模型。每个LSTM的存储单元都需要3D输入。当LSTM处理一个时间步长的输入序列时,每个记忆单元将以2D数组的形式输出整个序列的一个单值预测。我们可以在下面的模型中对此进行演示,该模型具有一个隐藏的LSTM层,该层也是输出层。
# Example of one output for whole sequence
from keras.models import Sequential
from keras.layers import LSTM
from numpy import array
# define model where LSTM is also output layer
model = Sequential()
model.add(LSTM(1, input_shape=(3,1)))
model.compile(optimizer= adam , loss= mse )
# input time steps
data = array([0.1, 0.2, 0.3]).reshape((1,3,1))
# make and show prediction
print(model.predict(data))
输入序列具有3个值。运行示例将输入序列的单个值作为2D数组输出。
[[ 0.00031043]]
要堆叠LSTM层,我们需要更改前一个LSTM层的配置以输出3D作为后续层的输入,可以通过将层上的return_sequences参数设置为True(默认为False)来实现。每个输入时间步长将返回一个输出,并提供3D阵列。以下是与上述相同的示例,其中return_sequences = True。
# Example of one output for each input time step
from keras.models import Sequential
from keras.layers import LSTM
from numpy import array
# define model where LSTM is also output layer
model = Sequential()
model.add(LSTM(1, return_sequences=True, input_shape=(3,1)))
model.compile(optimizer= adam , loss= mse )
# input time steps
data = array([0.1, 0.2, 0.3]).reshape((1,3,1))
# make and show prediction
print(model.predict(data))
运行示例将为输入序列中的每个时间步输出一个值。
[[[-0.02115841]
[-0.05322712]
[-0.08976141]]]
以下是定义两个隐藏层Stacked LSTM的示例:
model = Sequential()
model.add(LSTM(..., return_sequences=True, input_shape=(...)))
model.add(LSTM(...))
model.add(Dense(...))
只要先前的LSTM层提供3D输出作为后续层的输入,我们就可以继续添加隐藏的LSTM层。例如,下面是具有4个隐藏层的Stacked LSTM。
model = Sequential()
model.add(LSTM(..., return_sequences=True, input_shape=(...)))
model.add(LSTM(..., return_sequences=True))
model.add(LSTM(..., return_sequences=True))
model.add(LSTM(...))
model.add(Dense(...))
接下来,我们将定义一个问题,我们可以在该问题上演示堆叠式LSTM。
7.2 Damped Sine Wave Prediction Problem
本节介绍并实现阻尼正弦波预测问题。本节分为以下几部分:
- 正弦波。
- 阻尼正弦波。
- 随机阻尼正弦波。
- 阻尼正弦波序列。
7.2.1 Sine Wave
正弦波表示随时间变化的振荡,该振荡具有一致的幅度(相对于基线的移动)和频率(最小值和最大值之间的时间步长)。在不陷入正弦波方程式的情况下,我们可以准备代码以将正弦波创建为序列并将其绘制出来。
from math import sin
from math import pi
from matplotlib import pyplot
# create sequence
length = 100
freq = 5
sequence = [sin(2 * pi * freq * (i/length)) for i in range(length)]
# plot sequence
pyplot.plot(sequence)
pyplot.show()
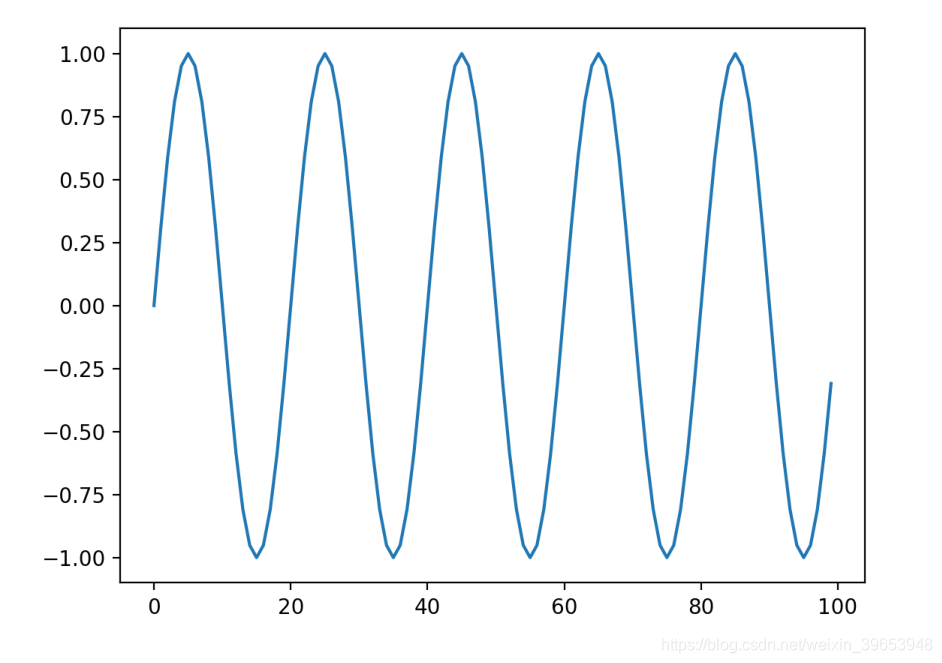
我们可以看到正弦波序列具有随时间向上和向下移动而变化的特性。这是Vanilla LSTM可以模拟的良好局部运动。 LSTM可以记住序列,也可以使用最后几个时间步来预测下一个时间步。
7.2.2 Damped Sine Wave
有一种正弦波会随着时间而减小。幅度的减小提供了额外的长期移动,这可能需要LSTM中的抽象级别进行学习。同样,无需深入探讨方程式,我们可以在Python中如下实现。实施过程中要确保所有值都在0到1之间。
from math import sin
from math import pi
from math import exp
from matplotlib import pyplot
# create sequence
length = 100
period = 10
decay = 0.05
sequence = [0.5 + 0.5 * sin(2 * pi * i / period) * exp(-decay * i) for i in range(length)]
# plot sequence
pyplot.plot(sequence)
pyplot.show()
运行示例显示了正弦波和衰减效果随时间的变化。周期参数确定一个完整周期完成之前有多少时间步长,而衰减参数确定序列向零减小的速度。
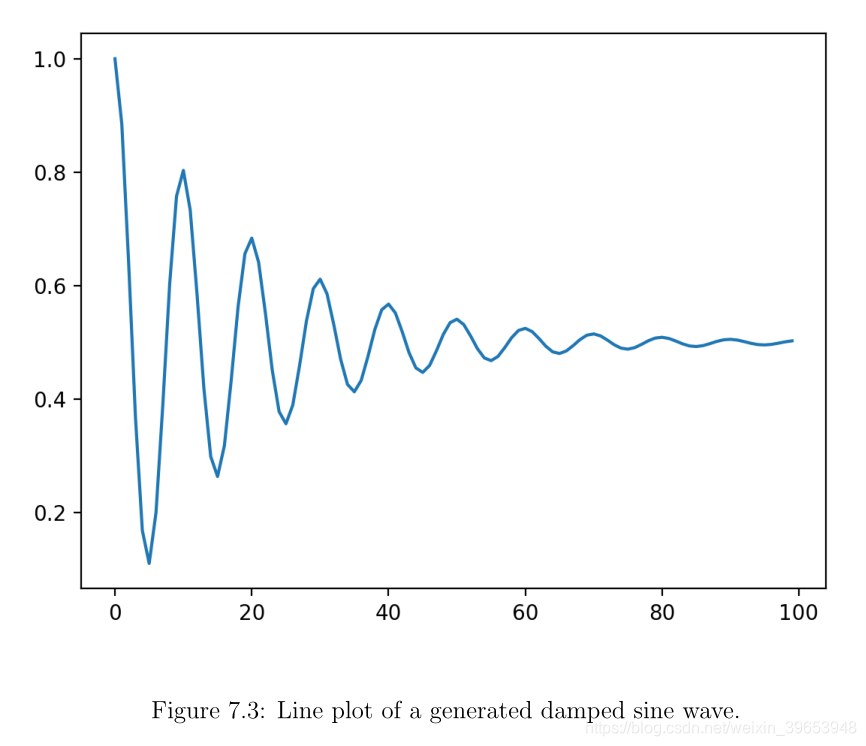
我们将使用它作为序列预测问题来演示Stacked LSTM。
7.2.3 Random Damped Sine Waves
我们可以生成具有不同周期和衰减值的阻尼正弦波序列,保留序列的最后几个点,并让模型进行预测。首先,我们可以定义一个函数,它定义了一个generate_sequence()。
# generate damped sine wave in [0,1]
def generate_sequence(length, period, decay):
return [0.5 + 0.5 * sin(2 * pi * i / period) * exp(-decay * i) for i in range(length)]
7.2.4 Sequences of Damped Sine Waves
接下来,我们需要一个函数来生成具有随机选择的周期和衰减的序列。我们将使用randint()函数选择介于10到20之间的均匀随机周期,以及之间的均匀随机衰减。 0.01和0.1使用uniform()函数。
p = randint(10, 20)
d = uniform(0.01, 0.1)
我们将拆分每个序列的最后n个时间步,并将其用作要预测的输出序列。我们将使其与要生成的序列数和序列的长度一起配置。下面名为generate_examples()的函数将实现此功能,并返回准备用于训练或评估LSTM的输入和输出示例数组。
# generate input and output pairs of damped sine waves
def generate_examples(length, n_patterns, output):
X, y = list(), list()
for _ in range(n_patterns):
p = randint(10, 20)
d = uniform(0.01, 0.1)
sequence = generate_sequence(length + output, p, d)
X.append(sequence[:-output])
y.append(sequence[-output:])
X = array(X).reshape(n_patterns, length, 1)
y = array(y).reshape(n_patterns, output)
return X, y
我们可以通过生成一些示例并绘制序列来测试此功能。
from math import sin
from math import pi
from math import exp
from random import random
from random import randint
from random import uniform
from numpy import array
from matplotlib import pyplot
# generate damped sine wave in [0,1]
def generate_sequence(length, period, decay):
return [0.5 + 0.5 * sin(2 * pi * i / period) * exp(-decay * i) for i in range(length)]
# generate input and output pairs of damped sine waves
def generate_examples(length, n_patterns, output):
X, y = list(), list()
for _ in range(n_patterns):
p = randint(10, 20)
d = uniform(0.01, 0.1)
sequence = generate_sequence(length + output, p, d)
X.append(sequence[:-output])
y.append(sequence[-output:])
X = array(X).reshape(n_patterns, length, 1)
y = array(y).reshape(n_patterns, output)
return X, y
# test problem generation
X, y = generate_examples(20, 5, 5)
for i in range(len(X)):
pyplot.plot([x for x in X[i, :, 0]] + [x for x in y[i]], -o )
pyplot.show()
运行示例将创建5个阻尼正弦波序列,每个序列具有20个时间步长。在序列的末尾会生成另外5个时间步长,这些步长将保留为测试数据。对于实际问题,我们会将其扩展到50个时间步长。
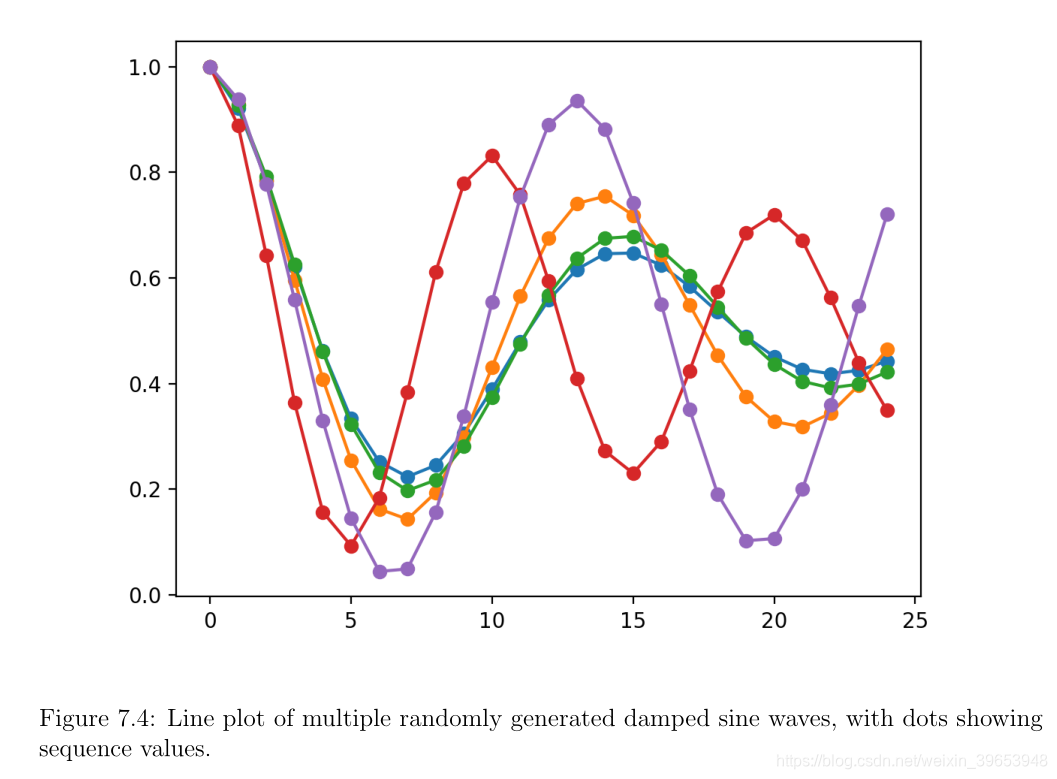
这是回归类型序列预测问题。也可以将其视为时间序列预测回归问题。在时间序列预测中,优良作法是使序列平稳,即在对问题建模之前从序列中删除任何系统趋势和季节性(seasonality)。建议在使用LSTM时使用。
在本课中,我们无意使该系列静止不动,以演示堆叠LSTM的功能。
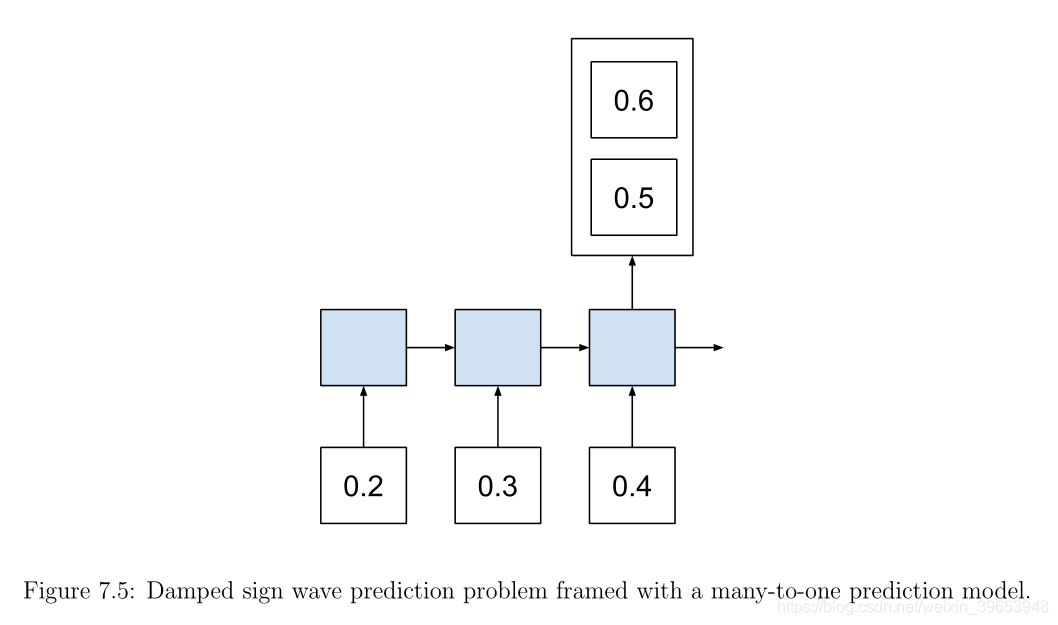
从技术上讲,这是一个多对一的序列预测问题。这可能会造成混淆,因为我们显然打算预测一系列输出时间步长。之所以是多对一的预测问题,是因为该模型不会分段预测输出时间步长。整个预测将立即产生。
从模型的角度来看,输入了n个时间步长的序列,然后在序列的末尾进行了单个预测。碰巧的是,预测是n个特征的向量,我们将其解释为时间步长。通过对提议的LSTM进行体系结构更改,我们可以使模型适应多对多的需求。考虑将此作为扩展。
7.3 Define and Compile the Model
我们将定义具有两个隐藏LSTM层的Stacked LSTM。每个LSTM层将具有20个记忆单元(memory cell)。输入维度将是20个时间步长(time steps)的1个特征(feature)。模型的输出维将是5个值的向量,我们将其解释为5个时间步长。输出层将使用线性激活函数,这是未指定任何函数时的默认值。
将对平均绝对误差(mae)损失函数进行优化,并使用梯度下降优化算法的Adam实现。下面列出了模型定义的代码。
# configure problem
length = 50
output = 5
# define model
model = Sequential()
model.add(LSTM(20, return_sequences=True, input_shape=(length, 1)))
model.add(LSTM(20))
model.add(Dense(output))
model.compile(loss= mae , optimizer= adam )
print(model.summary())
经过一些反复试验后,选择了此模型配置,特别是使用2层,每层使用20个单元。模型配置可以胜任,但没有必要对此问题进行调整。仅运行此部分即可定义并编译模型,然后打印模型结构的摘要。在结构中,我们可以确认模型的输入和输出的形状以及两个隐藏的LSTM层的使用。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 50, 20) 1760
_________________________________________________________________
lstm_2 (LSTM) (None, 20) 3280
_________________________________________________________________
dense_1 (Dense) (None, 5) 105
=================================================================
Total params: 5,145
Trainable params: 5,145
Non-trainable params: 0
_________________________________________________________________
7.4 Fit the Model
现在,我们可以将在随机生成的阻尼正弦波示例的数据集上拟合模型。该模型有望推广到预测阻尼正弦波时间序列的最后几个时间步。我们可以生成少量的例子,并将模型拟合到多个时期的随机例子上。缺点是模型会多次看到相同的随机例子,可能会试图记住它们。
或者,我们可以生成大量随机示例,并将模型拟合到该数据集的一个纪元上。它需要更多的内存,但可能更快的训练和更普遍的解决方案。这是我们将采用的方法。
我们将生成10000个随机阻尼正弦波示例来拟合模型,并使用此数据集的一个历元来拟合模型。这就像是为10000个时代装配模型。理想情况下,通过将批大小设置为1,我们可以在每个样本之后重置模型的内部状态。在这种情况下,我们将权衡纯度和训练速度,并将batch_size设置为10。这意味着,每10个样本后,模型权重将更新,LSTM存储单元内部状态将重置。
# fit model
X, y = generate_examples(length, 10000, output)
model.fit(X, y, batch_size=10, epochs=1)
训练可能需要几分钟,因此,由于模型合适,进度条将显示出来。如果这在笔记本或开发环境中引起问题,则可以通过在对fit()函数的调用中将verbose = 0设置为零来解决该问题。
10000/10000 [==============================] - 169s - loss: 0.0481
7.5 Evaluate the Model
模型适合后,我们就可以对其进行评估。在这里,我们生成了一组新的1000个随机序列,并报告了平均绝对误差(MAE)。
# evaluate model
X, y = generate_examples(length, 1000, output)
loss = model.evaluate(X, y, verbose=0) #verbose=0 表示不打印进度
print( MAE: %f % loss)
评估模型报告的技能约为0.02 MAE。由于神经网络的随机性,特定技能得分在您运行时可能会有所不同。
MAE: 0.021665
7.6 Make Predictions with the Model
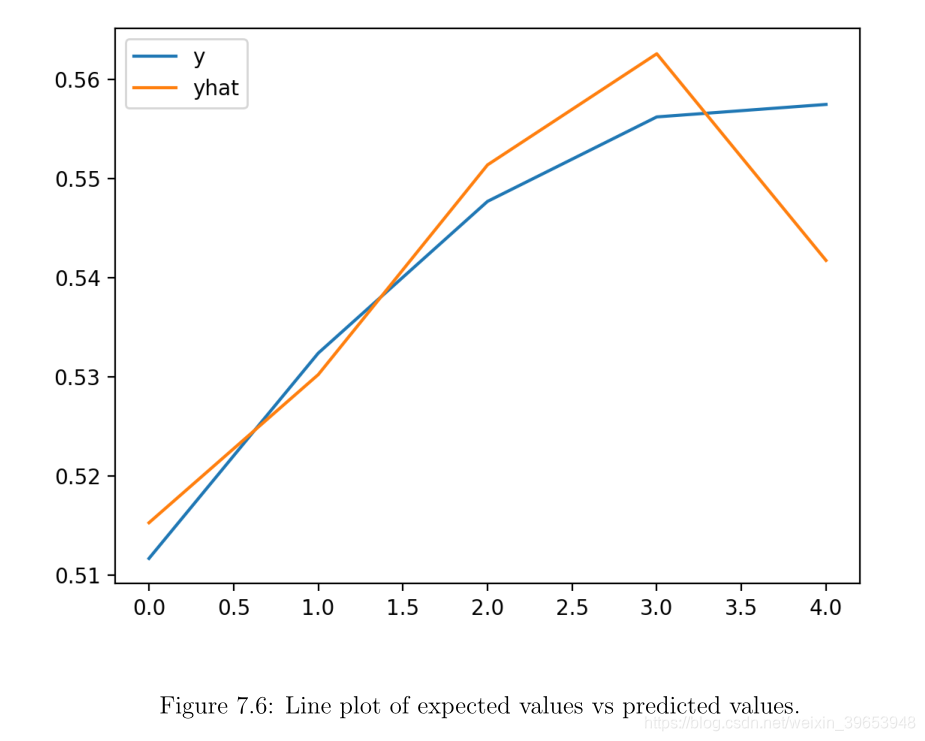
通过生成独立的预测并将其相对于预期的输出序列进行绘制,我们可以更好地了解模型的熟练程度。我们可以调用generate_examples() 函数并生成一个示例,然后使用拟合模型进行预测。然后绘制预测序列和预期序列以进行比较。
# prediction on new data
X, y = generate_examples(length, 1, output)
yhat = model.predict(X, verbose=0)
pyplot.plot(y[0], label= y )
pyplot.plot(yhat[0], label= yhat )
pyplot.legend()
pyplot.show()
至少在此运行中以及在此特定示例上,生成图显示了预测似乎对预期序列是合理的拟合。
完整代码:
from math import sin
from math import pi
from math import exp
from random import random
from random import randint
from random import uniform
from numpy import array
from matplotlib import pyplot
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
# generate damped sine wave in [0,1]
def generate_sequence(length, period, decay):
return [0.5 + 0.5 * sin(2 * pi * i / period) * exp(-decay * i) for i in range(length)]
# generate input and output pairs of damped sine waves
def generate_examples(length, n_patterns, output):
X, y = list(), list()
for _ in range(n_patterns):
p = randint(10, 20)
d = uniform(0.01, 0.1)
sequence = generate_sequence(length + output, p, d)
X.append(sequence[:-output])
y.append(sequence[-output:])
X = array(X).reshape(n_patterns, length, 1)
y = array(y).reshape(n_patterns, output)
return X, y
# configure problem
length = 50
output = 5
# define model
model = Sequential()
model.add(LSTM(20, return_sequences=True, input_shape=(length, 1)))
model.add(LSTM(20))
model.add(Dense(output))
model.compile(loss= mae , optimizer= adam )
print(model.summary())
# fit model
X, y = generate_examples(length, 10000, output)
history = model.fit(X, y, batch_size=10, epochs=1)
# evaluate model
X, y = generate_examples(length, 1000, output)
loss = model.evaluate(X, y, verbose=0)
print( MAE: %f % loss)
# prediction on new data
X, y = generate_examples(length, 1, output)
yhat = model.predict(X, verbose=0)
pyplot.plot(y[0], label= y )
pyplot.plot(yhat[0], label= yhat )
pyplot.legend()
pyplot.show()
7.8 Further Reading
7.8.1 Research Papers
-
How to Construct Deep Recurrent Neural Networks, 2013.
https://arxiv.org/abs/1312.6026 -
Training and Analyzing Deep Recurrent Neural Networks, 2013.
-
Speech Recognition With Deep Recurrent Neural Networks, 2013.
https://arxiv.org/abs/1303.5778 -
Generating Sequences With Recurrent Neural Networks, 2014.
https://arxiv.org/abs/1308.0850
7.8.2 Articles
-
Sine Wave on Wikipedia.
https://en.wikipedia.org/wiki/Sine_wave -
Damped Sine Wave on Wikipedia.
https://en.wikipedia.org/wiki/Damped_sine_wave
参考:Jason Brownlee《long-short-term-memory-networks-with-python》chapter 6-7
