尊敬的读者您好:笔者很高兴自己的文章能被阅读,但原创与编辑均不易,所以转载请必须注明本文出处并附上本文地址超链接以及博主博客地址:https://blog.csdn.net/vensmallzeng。若觉得本文对您有益处还请帮忙点个赞鼓励一下,笔者在此感谢每一位读者,如需联系笔者,请记下邮箱:[email protected],谢谢合作!
最近又是准备组会报告、所会报告,又是安排支部发展会、转正会,因此直到今天才有时间继续往下谈另一版用于实现NER的bi-lstm+CRF程序,该版本中的词向量不是随机生成的,而是训练生成的,且该版本的代码写的也甚是规范,所以非常想跟大家分享一下该版本的bi-lstm+CRF。
1、如果需要本文源码请自行转向“https://download.csdn.net/download/vensmallzeng/11237257”。
2、该版本主要包括以下几个部分:

data_path文件夹用于存放训练数据、测试数据、以及word2id.pkl文件,其中word2id.pkl是对给单词进行编号,以便查找词向量;

data_path_save文件夹用于保存训练好的模型以及参数,其中每一个以数字命名的文件夹代表一次训练好的模型以及参数;

pics文件夹用于存放图片以展示模型的效果

3、data.py文件包含一些语料数据预处理的函数如read_corpus、build_vocab、sentence2id、read_dictionary、pad_sequences以及batch_yield等,各函数具体功能见注释。






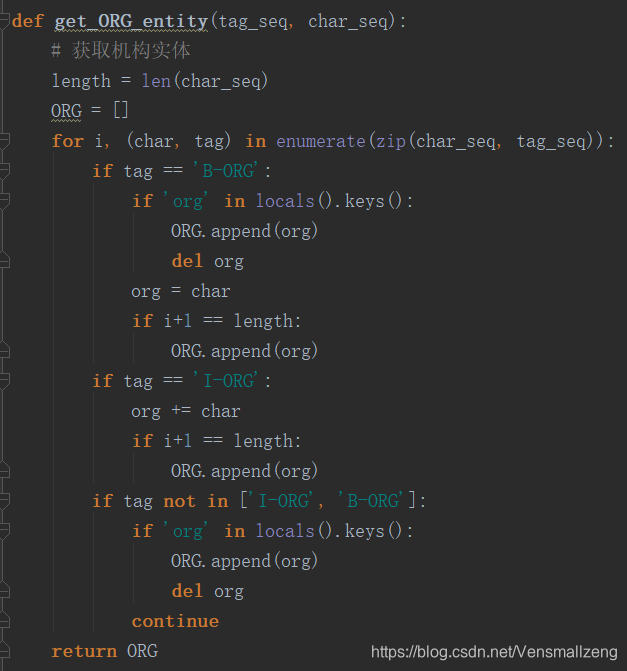
4、utils.py文件包含一些功能函数如str2bool、get_entity、get_PER_entity、get_LOC_entity、get_ORG_entity以及get_logger,各函数具体功能见注释。





5、model.py文件主要是用于搭建bi-Lstm+CRF模型。
首先对模型的基本参数进行初始化

建立张量计算图

添加并导入数据

根据训练好的词向量,通过word2id查找得到对应词向量

搭建bi-lstm+CRF模型

计算损失函数

优化损失函数,更新模型参数

测试模型函数

调整数据格式以适应于模型输入

评估模型的训练效果

6、main.py主要用于调用各种函数,并实现NER功能。
对超参数进行初始化

与随机生成词向量的Bi-lstm+CRF不同的是,这里的词向量是要训练生成(可用word2vec生成)且固定不变的。在该版本中既可选择随机生成词向量也可以选择训练生成词向量。

获取训练数据并用于训练模型(训练模型时,需对'--mode'超参数设置成train)

获取测试数据并用于测试模型(训练模型时,需对'--mode'超参数设置成test)

实际应用部分,即实现输入一句话,自动提取出人名、地点和机构(应用模型时,需对'--mode'超参数设置成demo)

实际效果如下:

日积月累,与君共进,增增小结,未完待续。
