相关文章:
LSTM 01:理解LSTM网络及训练方法
LSTM 02:如何为LSTMs准备数据
LSTM 03:如何使用Keras编写LSTMs
LSTM 04:4种序列预测模型及Keras实现
LSTM 05:如何开发 Vanilla LSTMs 和 Stacked LSTMs
LSTM 06:如何用Keras开发CNN LSTM
文章目录
- 相关文章:
- 9.How to Develop Encoder-Decoder LSTMs
- 9.1 Lesson Overview
- 9.2 The Encoder-Decoder LSTM
- 9.2.1 Sequence-to-Sequence Prediction Problems
- 9.2.2 Architecture
- 9.2.3 Applications
- 9.2.4 Implementation
- 9.3 Addition Prediction Problem
- 9.3.1 Generate Sum Pairs
- 9.3.2 Integers to Padded Strings
- 9.3.3 Integer Encoded Sequences
- 9.3.4 One Hot Encoded Sequences
- 9.3.5 Sequence Generation Pipeline
- 9.3.6 Decode Sequences
- 9.4 Define and Compile the Model
- 9.5 Fit the Model
- 9.6 Evaluate the Model
- 9.7 Make Predictions with the Model
- 9.8 Complete Example
9.How to Develop Encoder-Decoder LSTMs
本文内容是学习如何开发编码器-解码器LSTM(encoder-decoder LSTM)模型。主要内容如下:
- 编码器-解码器LSTM体系结构以及如何在Keras中实现它。
- 加法序列间预测问题。
- 如何为加法序列间预测问题开发编码器-解码器LSTM。
9.1 Lesson Overview
- 编码器-解码器LSTM。
- 加法预测问题。 3.
- 定义并编译模型。
- 拟合模型。
- 评估模型。
- 使用模型进行预测。
- 完整示例。
9.2 The Encoder-Decoder LSTM
9.2.1 Sequence-to-Sequence Prediction Problems
序列预测通常包括预测实值序列中的下一个值或输出输入序列的类标签。这通常被框定为一个输入时间步到一个输出时间步(例如,一对一)或多个输入时间步到一个输出时间步(多对一)类型的序列预测问题。
有一种更具挑战性的序列预测问题,它以一个序列作为输入,要求一个序列预测作为输出。这些问题称为序列到序列预测问题,简称seq2seq。使这些问题具有挑战性的一个建模问题是,输入和输出序列的长度可能不同。由于存在多个输入时间步和多个输出时间步,这种形式的问题被称为多对多类型序列预测问题。
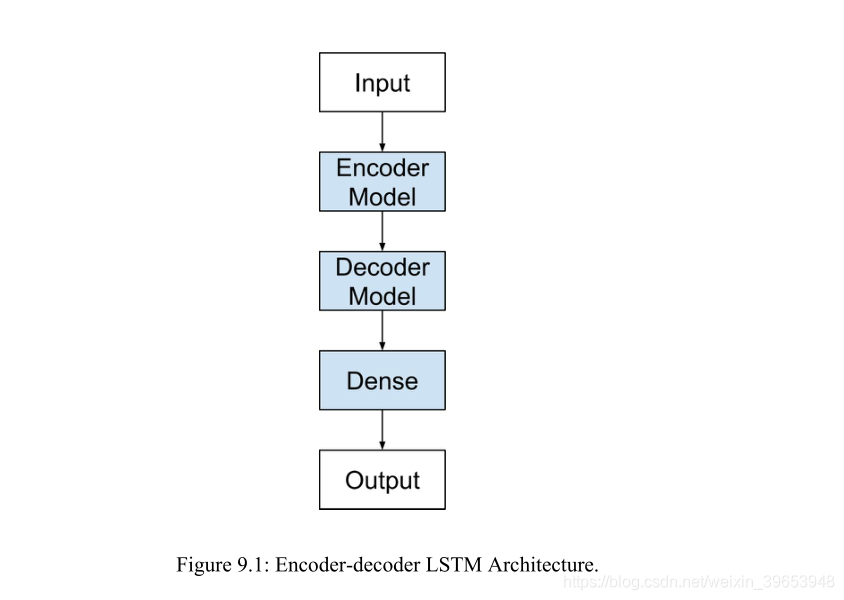
9.2.2 Architecture
seq2seq预测问题的一种方法被证明是非常有效的,称为编码器LSTM。该结构由两个模型组成:一个用于读取输入序列并将其编码为固定长度矢量,另一个用于解码固定长度矢量并输出预测序列。这些模型的协同使用为该体系结构命名为专门为seq2seq问题设计的编码器-解码器LSTM(Encoder-Decoder LSTM)。
… RNN编码器-解码器,由两个作为编码器和解码器对的递归神经网络(RNN)组成。编码器将可变长度源序列映射到固定长度矢量,解码器将矢量表示映射回可变长度目标序列。——Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.
编码器-解码器LSTM是针对自然语言处理问题而开发的,它展示了最先进的性能,特别是在称为统计机器翻译的文本翻译领域。该体系结构的创新之处在于在模型的心脏中使用了固定大小的内部表示形式,该模型将读取输入序列并从中读取输出序列。
在该体系结构首次应用于英法翻译的过程中,对编码的英语短语的内部表示进行了可视化。这些情节揭示了用于翻译任务的短语在质量上有意义的学习结构。
所提出的RNN编码器解码器自然地生成短语的连续空间表示。[…]从可视化的角度来看,很明显,RNN编码器解码器捕获短语的语义和句法结构。——Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.

在翻译任务中,当输入序列颠倒时,该模型更为有效。此外,该模型被证明即使在很长的输入序列上也是有效的。
我们之所以能在长句上做得很好,是因为我们在训练和测试中颠倒了源句中单词的顺序,而不是目标句。通过这样做,我们引入了许多短期依赖项,使优化问题变得更简单…这项工作的一个关键技术贡献是,把源句中的单词颠倒过来。——Sequence to Sequence Learning with Neural Networks, 2014.
这种方法也用于图像输入,其中卷积神经网络用作输入图像的特征提取器,然后由解码器LSTM读取。
… 我们建议遵循这种优雅的方法,用深卷积神经网络(CNN)代替编码器RNN。[…]使用CNN作为图像“编码器”是很自然的,首先对其进行图像分类任务的预训练,然后使用最后一个隐藏层作为生成句子的RNN解码器的输入。——Show and Tell: A Neural Image Caption Generator, 2014.
9.2.3 Applications
下面的列表重点介绍了Encoder-Decoder LSTM体系结构的一些有趣应用。
- 机器翻译,如短语的英法翻译。
- 学习执行,例如计算小程序的结果。
- 图像字幕,例如生成图像的文本描述。
- 会话建模,例如生成文本问题的答案。
- 动作分类,例如从一系列手势中生成一系列命令。
9.2.4 Implementation
编码器-解码器LSTM可以直接在Ker as中实现。可以认为模型由两个关键部分组成:编码器和解码器。首先,将输入序列一次显示给网络一个编码字符。需要一个编码级别来学习输入序列中步骤之间的关系,并开发这些关系的内部表示形式。
一层或多层LSTM层可用于实现编码器模型。该模型的输出是一个固定大小的向量,代表输入序列的内部表示。该层中的存储单元数定义了此固定大小的向量的长度。
model = Sequential()
model.add(LSTM(..., input_shape=(...)))
解码器必须将学习到的内部输入序列表示形式转换为正确的输出序列。一个或多个LSTM层也可以用于实现解码器模型。该模型从编码器模型的固定大小的输出中读取。与Vanilla LSTM一样,Dense层用作网络的输出。通过将Dense层包装在TimeDistributed包装器中,可以使用相同的权重来输出输出序列中的每个时间步。
model.add(LSTM(..., return_sequences=True))
model.add(TimeDistributed(Dense(...)))
注意,不能将编码器与解码器直接连接。因为,编码器产生一个二维输出矩阵,其长度由该层中存储单元的数量定义。解码器是一个LSTM层,它期望[样本,时间步长,特征]的3D输入,以便产生问题定义的某种不同长度的解码序列。
如果尝试将这些部分拼合在一起,则会出现错误,提示解码器的输出为2D,并且需要将3D输入解码器。我们可以使用RepeatVector层解决此问题。该层简单地多次重复提供的2D输入以创建3D输出。
可将RepeatVector层用作适配器,以将网络的编码器和解码器部分连接在一起。可以将RepeatVector配置为对输出序列中的每个时间步重复一次固定长度向量。
model.add(RepeatVector(...))
完整模型如下:
model = Sequential()
model.add(LSTM(..., input_shape=(...)))
model.add(RepeatVector(...))
model.add(LSTM(..., return_sequences=True))
model.add(TimeDistributed(Dense(...)))
综上所述,使用RepeatVector作为适配器,将编码器的固定大小的2D输出与解码器期望的不同长度和3D输入相匹配。TimeDistributed包装器允许对输出序列中的每个元素重用相同的输出层。
9.3 Addition Prediction Problem
加法问题(Addition Prediction Problem)是一个序列到序列,或seq2seq,预测问题。Wojciech Zaremba和Ilya Sutskever在他们2014年的论文中探讨了LSTM的编译码能力,题为“学习执行(Learning to Execute)”,该架构演示了如何学习计算小程序的输出。
这个问题定义为计算两个输入数的输出和。这很有挑战性,因为每个数字和数学符号都是作为字符提供的,预期的输出也是作为字符提供的。例如,输入10+6,输出16,用序列表示:
Input: [ 1 , 0 , + , 6 ]
Output: [ 1 , 6 ]
模型不仅要了解字符的整数性质,还要了解要执行的数学运算的性质。请注意,现在序列是多么重要,而随机打乱输入将创建一个没有意义的序列,不能与输出序列相关。还要注意在输入和输出序列中数字的数量是如何变化的。从技术上讲,这使得附加预测问题成为一个序列到序列的问题,需要处理多对多模型。
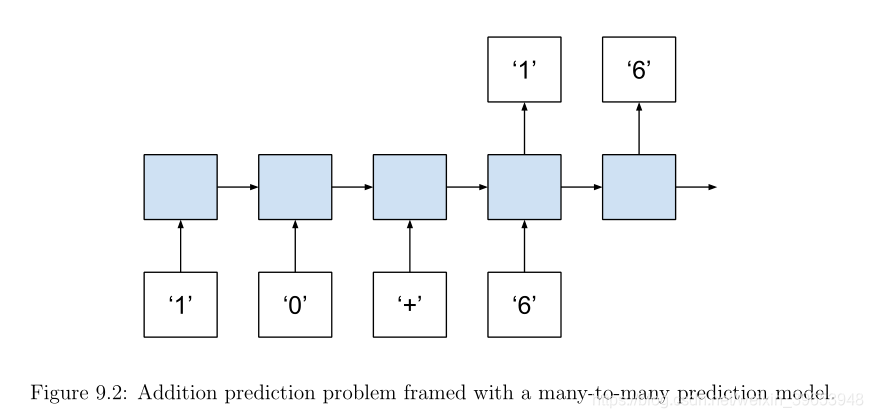
可以通过添加两个变量来简化问题,但是可以看到这个变量是如何缩放成一个可变数量的项和数学运算的,这些项和数学运算可以作为模型的输入来学习和推广。这个问题可以在Python中实现,分为以下几个步骤:
- Generate Sum Pairs.
- Integers to Padded Strings.
- Integer Encoded Sequences.
- One Hot Encoded Sequences.
- Sequence Generation Pipeline.
- Decode Sequences.
9.3.1 Generate Sum Pairs
第一步是生成随机整数序列及其和。定义random sum pairs()函数:
from random import seed
from random import randint
# generate lists of random integers and their sum
def random_sum_pairs(n_examples, n_numbers, largest):
X, y = list(), list()
for i in range(n_examples):
in_pattern = [randint(1,largest) for _ in range(n_numbers)]
out_pattern = sum(in_pattern)
X.append(in_pattern)
y.append(out_pattern)
return X, y
seed(1)
n_samples = 1
n_numbers = 2
largest = 10
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
print(X, y)
9.3.2 Integers to Padded Strings
下一步是将整数转换为字符串。输入字符串的格式为“10+10”,输出字符串的格式为“20”。此函数的关键是填充数字,以确保每个输入和输出序列具有相同数量的字符。填充字符应该与数据不同,以便模型能够学会忽略它们。在本例中,使用空格字符作为填充(’ '),并将字符串填充到左边,将信息保留在最右边。
还有其他方法可以填充,比如逐个填充每个词。填充需要知道最长的序列有多长。可以通过取所生成的最大整数的log10()和该数的上限来计算这个数,从而了解每个数需要多少个字符。在最大的数上加1,以确保对于整数最大的数(比如200),期望得到3个字符,而不是2个字符,然后取结果的上限(例如ceil(log10(largest+1)))。然后需要添加正确数量的加号(例如n个数字- 1)。
max_length = n_numbers * ceil(log10(largest+1)) + n_numbers - 1
可以用一个实际的例子来具体说明这一点,其中terms的总数(n_numbers)是3,最大的值(maximum)是10。
max_length = n_numbers * ceil(log10(largest+1)) + n_numbers - 1
max_length = 3 * ceil(log10(10+1)) + 3 - 1
max_length = 3 * ceil(1.0413926851582251) + 3 - 1
max_length = 3 * 2 + 3 - 1
max_length = 6 + 3 - 1
max_length = 8
直观地说,希望2个空间为每个term(如[’ 1 ‘,’ 0 ‘]) 乘以3,或输入的最大长度序列添加6个空间与两个空间的符号(如[’ 1 ‘,’ 0 ‘,’ + ‘,’ 1 ‘,’ 0 ‘,’ + ‘,’ 1 ‘,’ 0 '])的最大可能的序列长度8个字符。
在输出序列上重复类似的过程,没有加号。
max_length = ceil(log10(n_numbers * (largest+1)))
同样,可以通过计算上面示例的最大输出序列长度(其中terms的总数(n_numbers)为3,最大值(maximum)为10)来具体说明这一点。
max_length = ceil(log10(n_numbers * (largest+1)))
max_length = ceil(log10(3 * (10+1)))
max_length = ceil(log10(33))
max_length = ceil(1.5185139398778875)
max_length = 2
直观地说,预计最大可能的加法是10+10+10或30。这需要最大长度为2,下面的示例将添加to_string()函数,并演示它在单个输入/输出对中的用法。
from random import seed
from random import randint
from math import ceil
from math import log10
# generate lists of random integers and their sum
def random_sum_pairs(n_examples, n_numbers, largest):
X, y = list(), list()
for i in range(n_examples):
in_pattern = [randint(1,largest) for _ in range(n_numbers)]
out_pattern = sum(in_pattern)
X.append(in_pattern)
y.append(out_pattern)
return X, y
# convert data to strings
def to_string(X, y, n_numbers, largest):
max_length = n_numbers * ceil(log10(largest+1)) + n_numbers - 1
Xstr = list()
for pattern in X:
strp = '+'.join([str(n) for n in pattern])
strp = ''.join([' ' for _ in range(max_length-len(strp))]) + strp
Xstr.append(strp)
max_length = ceil(log10(n_numbers * (largest+1)))
ystr = list()
for pattern in y:
strp = str(pattern)
strp = ''.join([' ' for _ in range(max_length-len(strp))]) + strp
ystr.append(strp)
return Xstr, ystr
seed(1)
n_samples = 1
n_numbers = 2
largest = 10
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
print(X, y)
#convert to strings
X, y = to_string(X, y, n_numbers, largest)
print(X, y)
输出:
[[3, 10]] [13]
[ 3+10 ] [ 13 ]
9.3.3 Integer Encoded Sequences
接下来,需要将字符串中的每个字符编码为整数值。神经网络的输入为数字,而不是字符。整数编码将问题转换为一个分类问题,其中输出序列可以被视为类输出,每个类输出有11个可能的值。这恰好是一些有序数关系的整数(前10个类值)。要执行此编码,必须定义字符串编码中可能出现的符号的完整字母表,如下所示:
alphabet = [ 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , + , ]
整数编码随后变成一个简单的过程,即建立字符到整数o集的查找表,并逐个转换每个字符串的每个字符。下面的示例提供整数编码的integer_encode()函数,并演示如何使用它。
from random import seed
from random import randint
from math import ceil
from math import log10
# generate lists of random integers and their sum
def random_sum_pairs(n_examples, n_numbers, largest):
X, y = list(), list()
for i in range(n_examples):
in_pattern = [randint(1,largest) for _ in range(n_numbers)]
out_pattern = sum(in_pattern)
X.append(in_pattern)
y.append(out_pattern)
return X, y
# convert data to strings
def to_string(X, y, n_numbers, largest):
max_length = n_numbers * ceil(log10(largest+1)) + n_numbers - 1
Xstr = list()
for pattern in X:
strp = '+'.join([str(n) for n in pattern])
strp = ''.join([' ' for _ in range(max_length-len(strp))]) + strp
Xstr.append(strp)
max_length = ceil(log10(n_numbers * (largest+1)))
ystr = list()
for pattern in y:
strp = str(pattern)
strp = ''.join([' ' for _ in range(max_length-len(strp))]) + strp
ystr.append(strp)
return Xstr, ystr
# integer encode strings
def integer_encode(X, y, alphabet):
char_to_int = dict((c, i) for i, c in enumerate(alphabet))
Xenc = list()
for pattern in X:
integer_encoded = [char_to_int[char] for char in pattern]
Xenc.append(integer_encoded)
yenc = list()
for pattern in y:
integer_encoded = [char_to_int[char] for char in pattern]
yenc.append(integer_encoded)
return Xenc, yenc
seed(1)
n_samples = 1
n_numbers = 2
largest = 10
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
print(X, y)
# convert to strings
X, y = to_string(X, y, n_numbers, largest)
print(X, y)
# integer encode
alphabet = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', ' ']
X, y = integer_encode(X, y, alphabet)
print(X, y)
运行该示例将打印每个字符串编码模式的整数编码版本。可以看到空间字符(’’)是用11编码的,三个字符(’’)是用3编码的,依此类推。输出:
[[3, 10]] [13]
[' 3+10'] ['13']
[[11, 3, 10, 1, 0]] [[1, 3]]
9.3.4 One Hot Encoded Sequences
下一步是对整数编码序列进行二进制编码。这包括将每个整数转换为与字母表长度相同的二进制向量,并用1标记特定整数。例如,0整数表示“0”字符,并将被编码为二进制向量,其中1位于11元素向量的第0个位置:[1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。该示例对one_hot_encode()函数进行二进制编码。
from random import seed
from random import randint
from math import ceil
from math import log10
# generate lists of random integers and their sum
def random_sum_pairs(n_examples, n_numbers, largest):
X, y = list(), list()
for i in range(n_examples):
in_pattern = [randint(1,largest) for _ in range(n_numbers)]
out_pattern = sum(in_pattern)
X.append(in_pattern)
y.append(out_pattern)
return X, y
# convert data to strings
def to_string(X, y, n_numbers, largest):
max_length = n_numbers * ceil(log10(largest+1)) + n_numbers - 1
Xstr = list()
for pattern in X:
strp = '+'.join([str(n) for n in pattern])
strp = ''.join([' ' for _ in range(max_length-len(strp))]) + strp
Xstr.append(strp)
max_length = ceil(log10(n_numbers * (largest+1)))
ystr = list()
for pattern in y:
strp = str(pattern)
strp = ''.join([' ' for _ in range(max_length-len(strp))]) + strp
ystr.append(strp)
return Xstr, ystr
# integer encode strings
def integer_encode(X, y, alphabet):
char_to_int = dict((c, i) for i, c in enumerate(alphabet))
Xenc = list()
for pattern in X:
integer_encoded = [char_to_int[char] for char in pattern]
Xenc.append(integer_encoded)
yenc = list()
for pattern in y:
integer_encoded = [char_to_int[char] for char in pattern]
yenc.append(integer_encoded)
return Xenc, yenc
# one hot encode
def one_hot_encode(X, y, max_int):
Xenc = list()
for seq in X:
pattern = list()
for index in seq:
vector = [0 for _ in range(max_int)]
vector[index] = 1
pattern.append(vector)
Xenc.append(pattern)
yenc = list()
for seq in y:
pattern = list()
for index in seq:
vector = [0 for _ in range(max_int)]
vector[index] = 1
pattern.append(vector)
yenc.append(pattern)
return Xenc, yenc
seed(1)
n_samples = 1
n_numbers = 2
largest = 10
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
print(X, y)
# convert to strings
X, y = to_string(X, y, n_numbers, largest)
print(X, y)
# integer encode
alphabet = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', ' ']
X, y = integer_encode(X, y, alphabet)
print(X, y)
# one hot encode
X, y = one_hot_encode(X, y, len(alphabet))
print(X, y)
运行该示例将为每个整数编码打印二进制编码序列。我添加了一些新行,使输入和输出二进制编码更清晰。您可以看到,一个单和模式变成一个由5个二进制编码向量组成的序列,每个向量有11个元素。输出或和变成一个由两个二进制编码向量组成的序列,每个向量又有11个元素。
[[3, 10]] [13]
[ 3+10 ] [ 13 ]
[[11, 3, 10, 1, 0]] [[1, 3]]
[[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]]
[[[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]]]
9.3.5 Sequence Generation Pipeline
我们可以将所有这些步骤绑定到一个名为generate_data() 的函数中,如下所示。给定设计的样本数、项数、每个项的最大值以及可能的字符的字母表,函数将生成一组输入和输出序列。
# generate an encoded dataset
def generate_data(n_samples, n_numbers, largest, alphabet):
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
# convert to strings
X, y = to_string(X, y, n_numbers, largest)
# integer encode
X, y = integer_encode(X, y, alphabet)
# one hot encode
X, y = one_hot_encode(X, y, len(alphabet))
# return as NumPy arrays
X, y = array(X), array(y)
return X, y
9.3.6 Decode Sequences
最后,需要反转编码,将输出向量转换回数字,这样就可以比较预期的输出整数和预期的整数。下面的invert() 函数执行此操作。Key首先使用argmax() 函数将二进制编码转换回整数,然后使用从字母表中的整数到字符的反向映射将整数转换回字符。
# invert encoding
def invert(seq, alphabet):
int_to_char = dict((i, c) for i, c in enumerate(alphabet))
strings = list()
for pattern in seq:
string = int_to_char[argmax(pattern)]
strings.append(string)
return 1 *.join(strings)
9.4 Define and Compile the Model
第一步是定义序列预测问题的规范。为了生成输入输出序列的样本,必须指定3个参数作为generate_data()函数的输入:
- n.terms:方程式中的项数(例如,2表示10+10)。
- largest:每个术语(term)的最大数值(例如,1-10之间的值为10)。
- alphabet:用于编码输入和输出序列的符号(e.g. 0-9, + and ‘ ’)
每个实例将由3个术语组成,每个术语的最大值为10。无论配置值为0-9,“+”,还是n-d“ ”,字母表都保持固定。
n_chars变量用于针对每个输入和输出时间步长定义输入层中的要素数量和输出层中的要素数量。n_in_seq_length变量用于定义网络输入层的时间步数。 n_out_seq_length变量用于定义重复RepeatVector中的编码输入的次数,该次数进而定义了馈送到解码器以创建输出序列的序列的长度。 n_in_seq_length和n_out_seq_length的定义使用与to string()函数相同的代码,该函数用于将整数序列映射到字符串。
# size of alphabet: (12 for 0-9, + and )
n_chars = len(alphabet)
# length of encoded input sequence (8 for 10+10+10)
n_in_seq_length = n_terms * ceil(log10(largest+1)) + n_terms - 1
# length of encoded output sequence (2 for 30 )
n_out_seq_length = ceil(log10(n_terms * (largest+1)))
现在,我们准备定义Encoder-Decoder LSTM。我们将为编码器使用一个LSTM层,为解码器使用另一个单层。编码器定义为75个存储单元,解码器定义为50个存储单元。反复尝试后发现存储单元的数量。考虑到输入序列比输出序列相对较长,编码器和解码器中的层大小不对称看起来很自然。
输出层将分类日志损失用于可以预测的12个可能的类别。使用有效的Adam梯度下降实施方法,并将在训练和模型评估期间计算准确性。
# define LSTM
model = Sequential()
model.add(LSTM(75, input_shape=(n_in_seq_length, n_chars)))
model.add(RepeatVector(n_out_seq_length))
model.add(LSTM(50, return_sequences=True))
model.add(TimeDistributed(Dense(n_chars, activation= softmax )))
model.compile(loss= categorical_crossentropy , optimizer= adam , metrics=[ accuracy ])
print(model.summary())
运行示例将打印网络结构的摘要。我们可以看到,对于给定的输入序列,编码器将输出长度为75的固定大小的向量。将该序列重复两次,以向解码器提供具有75个特征的2个时间步长序列。解码器将两个具有50个特征的时间步长输出到Dense输出层,后者通过TimeDistributed包装器一次处理这些特征,以一次输出一个编码字符。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 75) 26400
_________________________________________________________________
repeat_vector_1 (RepeatVecto (None, 2, 75) 0
_________________________________________________________________
lstm_2 (LSTM) (None, 2, 50) 25200
_________________________________________________________________
time_distributed_1 (TimeDist (None, 2, 12) 612
=================================================================
Total params: 52,212
Trainable params: 52,212
Non-trainable params: 0
_________________________________________________________________
9.5 Fit the Model
该模型适合一个epoch有75,000个随机生成的输入输出对实例。序列数是训练时期数的代理。75000个,batch_size为32,都是经过反复试验发现的,但可能不是最佳配置。
# fit LSTM
X, y = generate_data(75000, n_terms, largest, alphabet)
model.fit(X, y, epochs=1, batch_size=32)
拟合模型时会打印进度条,显示每个批次结束时模型的损失和精度。这个模型不需要很长时间就可以安装到CPU上。如果进度条干扰了开发环境,可以通过在对fit()函数的调用中设置verbose=0来关闭它。
9.6 Evaluate the Model
可以通过在100个随机生成的输入输出对上生成预测来评估模型。结果将给出对随机生成的示例的模型技巧的一般估计。
# evaluate LSTM
X, y = generate_data(100, n_terms, largest, alphabet)
loss, acc = model.evaluate(X, y, verbose=0)
print( Loss: %f, Accuracy: %f % (loss, acc*100))
运行该示例将打印模型的损失和准确率。由于神经网络的随机性,值可能会有所不同,但模型精度应该大于0.9。
9.7 Make Predictions with the Model
可以使用拟合模型进行预测。下例一次进行一个预测,并提供解码输入、预期输出和预测输出的摘要。打印解码的输出给我们一个更具体的连接到问题和模型性能。在这里,生成10个新的随机输入输出序列对,使用每个序列的拟合模型进行预测,解码所有涉及的序列,并将它们打印到屏幕上。
# predict
for _ in range(10):
# generate an input-output pair
X, y = generate_data(1, n_terms, largest, alphabet)
# make prediction
yhat = model.predict(X, verbose=0)
# decode input, expected and predicted
in_seq = invert(X[0], alphabet)
out_seq = invert(y[0], alphabet)
predicted = invert(yhat[0], alphabet)
print( %s = %s (expect %s) % (in_seq, predicted, out_seq))
运行示例表明,该模型可以正确地获取大多数序列。生成的特定序列和仅十个示例上的模型技巧将有所不同。
9+10+9 = 27 (expect 28)
9+6+9 = 24 (expect 24)
8+9+10 = 27 (expect 27)
9+9+10 = 28 (expect 28)
2+4+5 = 11 (expect 11)
2+9+7 = 18 (expect 18)
7+3+2 = 12 (expect 12)
4+1+4 = 9 (expect 9)
8+6+7 = 21 (expect 21)
5+2+7 = 14 (expect 14)
9.8 Complete Example
from random import seed
from random import randint
from numpy import array
from math import ceil
from math import log10
from math import sqrt
from numpy import argmax
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import TimeDistributed
from keras.layers import RepeatVector
# generate lists of random integers and their sum
def random_sum_pairs(n_examples, n_numbers, largest):
X, y = list(), list()
for i in range(n_examples):
in_pattern = [randint(1,largest) for _ in range(n_numbers)]
out_pattern = sum(in_pattern)
X.append(in_pattern)
y.append(out_pattern)
return X, y
# convert data to strings
def to_string(X, y, n_numbers, largest):
max_length = n_numbers * ceil(log10(largest+1)) + n_numbers - 1
Xstr = list()
for pattern in X:
strp = '+'.join([str(n) for n in pattern])
strp = ''.join([' ' for _ in range(max_length-len(strp))]) + strp
Xstr.append(strp)
max_length = ceil(log10(n_numbers * (largest+1)))
ystr = list()
for pattern in y:
strp = str(pattern)
strp = ''.join([' ' for _ in range(max_length-len(strp))]) + strp
ystr.append(strp)
return Xstr, ystr
# integer encode strings
def integer_encode(X, y, alphabet):
char_to_int = dict((c, i) for i, c in enumerate(alphabet))
Xenc = list()
for pattern in X:
integer_encoded = [char_to_int[char] for char in pattern]
Xenc.append(integer_encoded)
yenc = list()
for pattern in y:
integer_encoded = [char_to_int[char] for char in pattern]
yenc.append(integer_encoded)
return Xenc, yenc
# one hot encode
def one_hot_encode(X, y, max_int):
Xenc = list()
for seq in X:
pattern = list()
for index in seq:
vector = [0 for _ in range(max_int)]
vector[index] = 1
pattern.append(vector)
Xenc.append(pattern)
yenc = list()
for seq in y:
pattern = list()
for index in seq:
vector = [0 for _ in range(max_int)]
vector[index] = 1
pattern.append(vector)
yenc.append(pattern)
return Xenc, yenc
# generate an encoded dataset
def generate_data(n_samples, n_numbers, largest, alphabet):
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
# convert to strings
X, y = to_string(X, y, n_numbers, largest)
# integer encode
X, y = integer_encode(X, y, alphabet)
# one hot encode
X, y = one_hot_encode(X, y, len(alphabet))
# return as numpy arrays
X, y = array(X), array(y)
return X, y
# invert encoding
def invert(seq, alphabet):
int_to_char = dict((i, c) for i, c in enumerate(alphabet))
strings = list()
for pattern in seq:
string = int_to_char[argmax(pattern)]
strings.append(string)
return ''.join(strings)
# configure problem
# number of math terms
n_terms = 3
# largest value for any single input digit
largest = 10
# scope of possible symbols for each input or output time step
alphabet = [str(x) for x in range(10)] + ['+', ' ']
# size of alphabet: (12 for 0-9, + and )
n_chars = len(alphabet)
# length of encoded input sequence (8 for 10+10+10)
n_in_seq_length = n_terms * ceil(log10(largest+1)) + n_terms - 1
# length of encoded output sequence (2 for 30 )
n_out_seq_length = ceil(log10(n_terms * (largest+1)))
# define LSTM
model = Sequential()
model.add(LSTM(75, input_shape=(n_in_seq_length, n_chars)))
model.add(RepeatVector(n_out_seq_length))
model.add(LSTM(50, return_sequences=True))
model.add(TimeDistributed(Dense(n_chars, activation='softmax')))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
from keras.utils import plot_model
plot_model(model,to_file='model-seq2seq.png',show_shapes=True,dpi=300)
# fit LSTM
X, y = generate_data(75000, n_terms, largest, alphabet)
model.fit(X, y, epochs=1, batch_size=32)
# evaluate LSTM
X, y = generate_data(100, n_terms, largest, alphabet)
loss, acc = model.evaluate(X, y, verbose=0)
print(' Loss: %f, Accuracy: %f' % (loss, acc*100))
# predict
for _ in range(10):
# generate an input-output pair
X, y = generate_data(1, n_terms, largest, alphabet)
# make prediction
yhat = model.predict(X, verbose=0)
# decode input, expected and predicted
in_seq = invert(X[0], alphabet)
out_seq = invert(y[0], alphabet)
predicted = invert(yhat[0], alphabet)
print(' %s = %s (expect %s)' % (in_seq, predicted, out_seq))
输出结果:
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_3 (LSTM) (None, 75) 26400
_________________________________________________________________
repeat_vector_2 (RepeatVecto (None, 2, 75) 0
_________________________________________________________________
lstm_4 (LSTM) (None, 2, 50) 25200
_________________________________________________________________
time_distributed_2 (TimeDist (None, 2, 12) 612
=================================================================
Total params: 52,212
Trainable params: 52,212
Non-trainable params: 0
_________________________________________________________________
None
Epoch 1/1
75000/75000 [==============================] - 42s 557us/step - loss: 0.6752 - accuracy: 0.8038
Loss: 0.128510, Accuracy: 98.000002
4+3+4 = 11 (expect 11)
1+10+7 = 18 (expect 18)
1+9+6 = 16 (expect 16)
2+3+9 = 14 (expect 14)
7+4+7 = 18 (expect 18)
10+8+1 = 19 (expect 19)
6+9+1 = 16 (expect 16)
4+1+10 = 15 (expect 15)
8+5+4 = 17 (expect 17)
6+1+2 = 9 (expect 9)
模型结构:

参考:Jason Brownlee《long-short-term-memory-networks-with-python》chapter 9
