相关文章
LSTM 01:理解LSTM网络及训练方法
LSTM 02:如何为LSTMs准备数据
LSTM 03:如何使用Keras编写LSTMs
LSTM 04:4种序列预测模型及Keras实现
LSTM 05:如何开发 Vanilla LSTMs 和 Stacked LSTMs
LSTM 06:如何用Keras开发CNN LSTM
LSTM 07:如何用Keras开发 Encoder-Decoder LSTM
文章目录
- 相关文章
- What are LSTMs
- 1.1 Sequence Prediction Problems
- 1.1.1 Sequence
- 1.1.2 Sequence Prediction
- 1.1.3 Sequence Classification
- 1.1.4 Sequence Generation
- 1.1.5 Sequence-to-Sequence Prediction
- 1.2 Limitations of Multilayer Perceptrons
- 1.3 Promise of Recurrent Neural Networks
- 1.4 The Long Short-Term Memory Network
- 1.5 Applications of LSTMs
- 1.5.1 Automatic Image Caption Generation
- 1.5.2 Automatic Translation of Text
- 1.5.3 Automatic Handwriting Generation
- 1.6 Limitations of LSTMs
- 1.7 Further Reading
- 1.7.1 Sequence Prediction Problems
- 2.How to Train LSTMs
What are LSTMs
本章节介绍了LSTMs及其工作原理。完成本课后,你将会知道:
- 什么是序列预测,以及它们与一般预测建模问题有何不同。
- 多层感知器在序列预测方面的局限性,递归神经网络在序列预测方面的前景,以及LSTMs如何实现这一前景。
- 令人印象深刻的LSTMs在挑战序列预测问题上的应用,以及对LSTMs的一些局限性的警告。
1.1 Sequence Prediction Problems
序列预测不同于其他类型的监督学习问题。**在训练模型和进行预测时,必须保持观察结果的顺序。**通常,涉及序列数据的预测问题被称为序列预测问题,尽管根据输入和输出序列有一系列不同的问题。这一节将研究4种不同类型的序列预测问题:
- Sequence Prediction.
- Sequence Classification.
- Sequence Generation.
- Sequence-to-Sequence Prediction.
但首先,要弄清楚**集合(set)和序列(sequence)**之间的区别。
1.1.1 Sequence
在应用机器学习中,我们经常处理集合,例如一列或一组样本的测试集。集合中的每个样本都可以看作是定义域中的一个观察值。在一个集合中,观察的顺序并不重要。
序列是不同的。序列对观测结果施加了明确的顺序。顺序很重要。在使用序列数据作为模型的输入或输出的预测问题的制定过程中,必须考虑到这一点。
1.1.2 Sequence Prediction
序列预测包括预测给定输入序列的下一个值。例如:
Input Sequence: 1, 2, 3, 4, 5
Output Sequence: 6
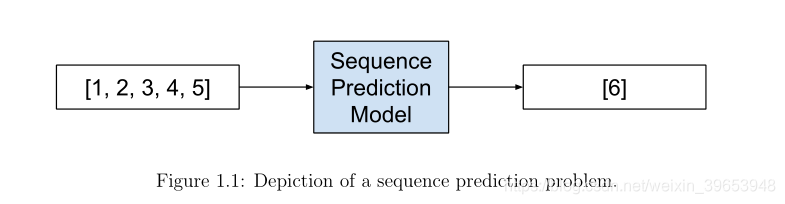
序列预测一般也称为序列学习。从技术上讲,我们可以把下列所有问题都看作是一种序列预测问题。这可能会使初学者感到困惑。
Learning of sequential data continues to be a fundamental task and a challenge in
pattern recognition and machine learning. Applications involving sequential data
may require prediction of new events, generation of new sequences, or decision
making such as classification of sequences or sub-sequences.
— On Prediction Using Variable Order Markov Models, 2004 .
序列数据的学习一直是模式识别和机器学习的基本任务和挑战。涉及顺序数据的应用程序可能需要预测新事件、生成新序列或决策,如序列或子序列的分类。
一般来说,在这本书中,我们将使用**“序列预测”**来指代一般类型的序列数据预测问题。然而,在本节中,我们将把序列预测与其他形式的预测区别开来,将序列数据定义为下一个时间步的预测。
一些序列预测问题的例子包括:
- 天气预报。根据一段时间内对天气的一系列观察,预测明天的天气。
- 股市预测。 给定安全性随时间推移的一系列运动,请预测安全性的下一个运动。
- 产品推荐。 给定客户过去的购买顺序,请预测客户的下一次购买。
1.1.3 Sequence Classification
序列分类涉及到预测给定输入序列的类标签。例如:
Input Sequence: 1, 2, 3, 4, 5
Output Sequence: "good"
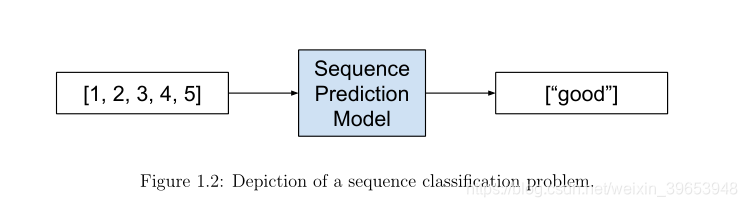
序列分类的目的:利用标记数据集[…]建立分类模型。因此,该模型可用于预测未知序列的类标签。
输入序列可以由实值或离散值组成。在后一种情况下,这类问题可称为离散序列分类问题。一些序列分类问题的例子包括:
- DNA序列分类。给定a、C、G和T值的DNA序列,预测该序列是编码区还是非编码区。
- 异常检测。 给定一系列观察结果,请预测该序列是否异常。
- 情感分析。 给定一系列文本(例如评论或推文),预测文本的情绪是正面还是负面。
1.1.4 Sequence Generation
序列生成包括生成与语料库中的其他序列具有相同一般特征的新输出序列。例如:
Input Sequence: [1, 3, 5], [7, 9, 11]
Output Sequence: [3, 5 ,7]
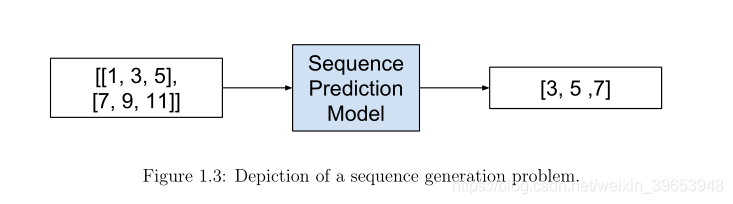
[递归神经网络]可以通过一步一步地处理真实的数据序列并预测接下来会发生什么来训练序列生成。假设预测是概率性的,通过对网络的输出分布进行迭代采样,然后将样本作为下一步的输入,可以从训练好的网络中生成新的序列。换句话说,通过让网络把它的发明当作是真实的,就像在做梦一样。— Generating Sequences With Recurrent Neural Networks, 2013.
一些序列生成问题的例子包括:
- 文字生成。 给定一个文本语料库(例如莎士比亚的作品),生成新的句子或文本段落,阅读它们可能是从该语料库中提取的。
- 手写预测。 给定一个手写示例的语料库,为具有语料库中笔迹特性的新短语生成笔迹。
- 音乐生成。 给定一个音乐实例集,生成具有该音乐集特性的新音乐作品。
序列的产生也可以指代给定单个观察作为输入的序列的产生。 一个示例是图像的自动文本描述。
- 图像标题生成。 给定图像作为输入,生成描述图像的单词序列。
例如:
Input Sequence: [image pixels]
Output Sequence: ["man riding a bike"]
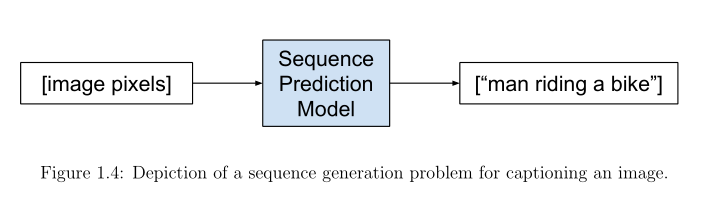
能够用适当的英语句子自动描述图像的内容是一项非常具有挑战性的任务,但它可能会产生巨大的影响[…]事实上,一个描述不仅必须捕获图像中包含的对象,而且还必须表达这些对象如何相互关联,以及它们的属性和它们所涉及的活动。— Show and Tell: A Neural Image Caption Generator, 2015
1.1.5 Sequence-to-Sequence Prediction
序列到序列的预测涉及到给定输入序列的输出序列的预测。例如:
Input Sequence: 1, 2, 3, 4, 5
Output Sequence: 6, 7, 8, 9, 10
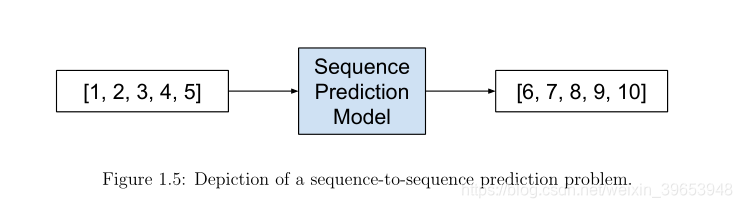
尽管深度神经网络具有灵活性和强大的功能,但它只适用于那些输入和目标可以用固定维数的向量合理编码的问题。这是一个重要的限制,因为许多重要的问题最好用长度未知的序列来表示。例如,语音识别和机器翻译是连续的问题。同样,回答问题也可以看作是将表示问题的单词序列映射到表示答案的单词序列。— Sequence to Sequence Learning with Neural Networks, 2014.
序列到序列预测是序列预测的一种微妙但具有挑战性的扩展,它不是预测序列中的一个单独的下一个值,而是预测一个可能与输入序列具有相同长度或相同时间的新序列。这种类型的问题最近在自动文本翻译(例如,将英语翻译成法语)领域中得到了大量的研究,可以用缩写seq2seq来指代。
*seq2seq学习的核心是使用递归神经网络将可变长度的输入序列映射到可变长度的输出序列。虽然seq2seq方法相对较新,但在……机器翻译方面已经取得了最先进的成果。— Multi-task Sequence to Sequence Learning, 2016. *
如果输入和输出序列是时间序列,则该问题可以称为多步时间序列预测(multi-step time series forecasting)。 序列间问题的一些示例包括:
- 多步时间序列预测。 给定一个时间序列的观测值,可以预测一系列未来时间步长的观测值序列。
- 文字摘要。 给定一个文本文件,该文件描述了源文件的重要部分。
- 程序执行。 给定文本描述程序或数学方程式,可以预测描述正确输出的字符序列。
1.2 Limitations of Multilayer Perceptrons
经典的神经网络称为多层感知器,简称MLPs,可以应用于序列预测问题。mlp近似一个从输入变量到输出变量的映射函数。这种通用能力对于序列预测问题(尤其是时间序列预测)是有价值的,原因有很多。
- 对噪声的鲁棒性(Robust to Noise)。 神经网络对于输入数据和映射功能中的噪声具有鲁棒性,甚至在缺少值的情况下甚至可以支持学习和预测。
- 非线性。神经网络对映射函数没有很强的假设,容易学习线性和非线性关系。
更具体地说,可以将mlp配置为支持映射函数中任意定义但固定数量的输入和输出。这意味着:
- 多变量输入。可以指定任意数量的输入特征,为多元预测提供直接支持。
- 多步骤的输出。可以指定任意数量的输出值,为多步甚至多变量预测提供直接支持。
这种能力克服了使用传统线性方法(如用于时间序列预测的ARIMA等工具)的限制。单就这些能力而言,前馈神经网络在时间序列预测中得到了广泛的应用。
MLPs在序列预测中的应用要求将输入序列分割成较小的重叠子序列,并将这些重叠子序列显示给网络以生成预测。输入序列的时间步长成为网络的输入特征。子序列是重叠的,以模拟一个窗口沿序列滑动,以生成所需的输出。这可以很好地解决一些问题,但它有5个关键的局限性。
- 无状态的(Stateless)。mlp学习一个固定的函数近似值。任何依赖于输入序列上下文的输出都必须被一般化(generalized)并固定(frozen)到网络权值中。
- 不用关心时间结构(Unaware of Temporal Structure)。 时间步长被建模为输入特征,这意味着网络对观察之间的时间结构或顺序没有明确的处理或理解。
- 混乱缩放(Messy Scaling):对于需要对多个并行输入序列进行建模的问题,输入特征的数量会随着滑动窗口大小的增加而增加,而无需明确区分序列的时间步长。
- 固定尺寸的输入(Fixed Sized Inputs):滑动窗口的大小是固定的,必须施加到网络的所有输入上。
- 固定大小的输出(Fixed Sized Outputs)。 输出的大小也是固定的,任何不符合要求的输出都必须强制执行。
MLP确实为序列预测提供了强大的功能,但仍然受到这一关键限制的影响,即必须在模型的设计中明确指定观测值之间的时间相关性范围。 mlp是建模序列预测问题的一个很好的起点,但是我们现在有了更好的选择。
1.3 Promise of Recurrent Neural Networks
长短时记忆(LSTM)网络是一种递归神经网络。递归神经网络(RNNs)是一种特殊的序列问题神经网络。给出一个标准的前馈MLP网络,一个RNN可以被认为是该体系结构中增加的循环。例如,在一个给定的层中,每个神经元除了向下一层传递信号外,还可以向后面(侧面)传递信号。网络的输出可以反馈为网络的输入,并带有下一个输入向量。等等。
重复连接将state或memory添加到网络中,使其能够学习和利用输入序列中观察到的有序特性。
…递归神经网络包含一些周期,这些周期将先前时间步长的网络活动作为输入输入到网络中,从而影响当前时间步的预测。这些激活被存储在网络的内部状态中,这些状态在原则上可以保存长期的时间上下文信息。这种机制允许RNNs在输入序列历史记录上利用动态变化的上下文窗口— Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling, 2014.
长短时记忆(LSTM)能够利用固定大小的时间窗来解决前馈网络无法解决的许多时间序列任务。— Applying LSTM to Time Series Predictable through Time-Window Approaches, 2001.
**除了使用神经网络进行序列预测的一般好处之外,RNNs还可以学习和利用数据的时间依赖性。**也就是说,在最简单的情况下,网络可以从一个序列中一次显示一个观察结果,并可以了解它之前看到的哪些观察结果是相关的,以及它们与做出预测的关系如何。
由于LSTM网络能够学习序列中的长期相关性,因此不需要预先指定的时间窗口,并且能够准确地建模复杂的多元序列。— Long Short Term Memory Networks for Anomaly Detection in Time Series, 2015.
递归神经网络的前景是可以学习输入数据中的时间依赖性和上下文信息。
输入不是固定而是组成输入序列的递归网络可用于将输入序列转换为输出序列,同时以灵活的方式考虑上下文信息。— Learning Long-Term Dependencies with Gradient Descent is Diffcult, 1994.
有许多RNNs,但是LSTM实现了RNNs对序列预测的承诺。这就是为什么现在有这么多关于LSTMs的讨论和应用。
LSTMs具有内部状态,它们明确地知道输入中的时间结构,能够分别对多个并行输入序列进行建模,并且能够单步通过不同长度的输入序列生成可变长度的输出序列,每次一个观察结果。
接下来,让我们进一步了解LSTM网络。
1.4 The Long Short-Term Memory Network
LSTM网络不同于传统的MLP。 像MLP一样,网络由神经元层组成。 输入数据通过网络传播,以便进行预测。
与RNNs一样,LSTMs也有重复的连接,因此来自前一个时间步的神经元激活的状态被用作生成输出的上下文。但与其他RNN不同的是,LSTM有一个独特的配方,它可以避免其他RNN的训练和规模的问题。这一点,以及可以实现的令人印象深刻的结果,是该技术流行的原因。
RNN一直以来面临的关键技术挑战是如何有效地训练它们。实验表明,权重更新程序导致权重变化迅速变小,导致梯度消失,或导致非常大的变化甚至溢出(爆炸梯度)。 LSTM克服了这一挑战。
不幸的是,标准的RNNs所能访问的上下文信息的范围实际上是相当有限的。问题是,给定的输入对隐含层的影响,以及因此对网络输出的影响,在围绕网络的循环连接时,要么衰减,要么呈指数级放大。这个缺点…在文献中被称为消失梯度问题…长短时记忆(LSTM)是一种专门针对消失梯度问题设计的RNN结构。— A Novel Connectionist System for Unconstrained Handwriting Recognition, 2009.
LSTM架构是通过对现有RNN中的错误流进行分析而得出的,该分析发现,现有架构无法访问长时间的信息,因为反向传播的错误会导致梯度爆炸或呈指数级衰减。LSTM层由一组递归连接的块组成,称为内存块。这些块可以被认为是数字计算机中存储芯片的可微版本。每个单元包含一个或多个递归连接的存储单元和三个乘法单元——输入、输出和遗忘门,它们为单元提供连续的写、读和重置操作。网络只能通过门与细胞相互作用。— Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, 2005.
1.4.1 LSTM Weights
记忆单元(memory cell)具有用于输入,输出以及通过暴露于输入时间步长而建立的内部状态的权重参数。
- 输入权重。用于对当前时间步长的输入进行加权。
- 输出权值。用于对最后一个时间步的输出进行加权。
- 内部状态(Internal State)。内部状态用于计算此时间步长的输出。
1.4.2 LSTM Gates
记忆单元的关键是门(gate)。这些都是加权函数,进一步控制单元中的信息流。有三个门:
- Forget Gate(遗忘门):决定从单元中丢弃哪些的信息。
- Input Gate(输入门):决定哪些输出的值去更新记忆状态。
- Outut Gate(输出门):根据输入和记忆单元确定输出什么。
遗忘门和输入门用于内部状态的更新。输出门是单元实际输出内容的最终限制器。这些门和被称为constant error carrousel(CEC)的一致的数据流使每个单元保持稳定(既不爆炸也不消失)。
每个存储单元的内部结构保证了恒定的误差,在恒定的误差范围内。这是桥接很长时间滞后的基础。两个门单元学习在每个记忆单元的CEC中打开和关闭对错误流的访问。乘法输入门(multiplicative input gate)提供了对CEC的保护,使其不受无关输入的干扰。同样,乘法输出门保护其他单元不受当前不相关的记忆内容的干扰。— Long Short-Term Memory, 1997.
与传统的MLP神经元不同,LSTM内存单元很难清晰地绘制出来。到处都是线、砝码和门。如果您认为LSTM内部的图片或基于等式的描述将进一步有所帮助,请参阅本章末尾的一些参考资料。我们可以总结出LSTMs的三个主要优点:
- 克服了训练RNN的技术问题,即梯度消失和爆炸。
- 具有记忆,以克服长期时间依赖与输入序列的问题。
- 按时间步长处理输入序列和输出序列,允许可变长度的输入和输出。
1.5 Applications of LSTMs
LSTMs可以为具有挑战性的序列预测问题提供优雅的解决方案。本节将提供3个示例,以便提供LSTMs能够实现的结果的快照。
1.5.1 Automatic Image Caption Generation
自动图像字幕是这样一种任务:给定一幅图像,系统必须生成描述图像内容的字幕。2014年,大量的深度学习算法在这个问题上取得了令人印象深刻的结果,这些算法利用顶级模型的工作来进行对象分类和照片中的对象检测。
一旦您可以在照片中检测对象并为这些对象生成标签,您就可以看到下一步是将这些标签转换为连贯的句子描述。该系统使用非常大的卷积神经网络来检测照片中的目标,然后使用LSTM将标签转换成连贯的句子。

1.5.2 Automatic Translation of Text
自动文本翻译是这样一种任务:给定一种语言的文本句子,把它们翻译成另一种语言的文本。例如,英语句子作为输入,中文句子作为输出。该模型必须学习单词的翻译、修改翻译的上下文,并支持输入和输出序列,这些序列的长度可能在一般情况下和相互之间有所不同。

1.5.3 Automatic Handwriting Generation
这是一个任务,在给定的手写示例库中,为给定的单词或短语生成新的手写。在创建手写样本时,手写作为笔使用的坐标序列提供。从这个语料库中,可以学习笔的运动和字母之间的关系,并生成新的例子。有趣的是,不同的风格可以学习,然后模仿。我很乐意看到这项工作结合一些法医笔迹分析专家。

1.6 Limitations of LSTMs
LSTMs非常令人印象深刻。该网络的设计克服了神经网络的技术挑战,实现了神经网络序列预测的承诺。LSTMs在一系列复杂序列预测问题中的应用取得了良好的效果。但是LSTMs并不适用于所有的序列预测问题。
例如,在时间序列预测中,与预测相关的信息通常在过去观测的一个小窗口内。通常,带有窗口或线性模型的MLP可能是较简单且更适合的模型。
在文献中发现的时间序列基准问题…通常比LSTM已经解决的许多任务在概念上更简单。它们通常根本不需要RNN,因为关于下一个事件的所有相关信息都是通过包含在一个小时间窗口内的几个最近事件来传递的。— Applying LSTM to Time Series Predictable through Time-Window Approaches, 2001
LSTMs的一个重要限制是记忆(memory)。或者更准确地说,记忆是如何被滥用的。有可能迫使LSTM模型在很长的输入时间步长的情况下记住单个观察结果。这是对LSTM的糟糕使用,并且需要LSTM模型来记住多个观察值将会失败。
这可以在将LSTMs应用于时间序列预测时看到,在这种情况下,问题被表述为一个自回归,该自回归要求输出是输入序列中多个距离时间步长的函数。LSTM可能会被迫执行这个问题,但是它的效率通常比精心设计的自回归模型或问题的重新构造要低。
假设任何动态模型都需要t-tau的所有输入…,我们注意到[自回归]-RNN必须存储从t-tau到t的所有输入,并在适当的时间覆盖它们。这需要实现一个循环缓冲区,这是RNN很难模拟的结构。— Applying LSTM to Time Series Predictable through Time-Window Approaches, 2001.
需要注意的是,使用lstm需要仔细考虑你问题得框架。可以将LSTMs的内部状态看作是一个方便的内部变量,以便捕获和提供用于进行预测的上下文。如果问题看起来像一个传统的自回归类型的问题,在一个小窗口中有最相关的滞后观察,那么在考虑LSTM之前,可以使用MLP和滑动窗口开发一个性能基线。
1.7 Further Reading
如果您想更深入地了解算法的技术细节,请阅读以下有关LSTM的必读文章。
1.7.1 Sequence Prediction Problems
-
Sequence on Wikipedia.
https://en.wikipedia.org/wiki/Sequence -
On Prediction Using Variable Order Markov Models, 2004 .
-
Sequence Learning: From Recognition and Prediction to Sequential Decision Making, 2001 .
-
Chapter 14, Discrete Sequence Classification, Data Classification: Algorithms and Applications,2015.
http://amzn.to/2tkM723 -
Generating Sequences With Recurrent Neural Networks, 2013.
https://arxiv.org/abs/1308.0850 -
Show and Tell: A Neural Image Caption Generator, 2015 .
https://arxiv.org/abs/1411.4555 -
Multi-task Sequence to Sequence Learning, 2016 .
https://arxiv.org/abs/1511.06114 -
Sequence to Sequence Learning with Neural Networks, 2014 .
https://arxiv.org/abs/1409.3215 -
Recursive and direct multi-step forecasting: the best of both worlds, 2012.
1.7.2 MLPs for Sequence Prediction
- Neural Networks for Time Series Processing, 1996.
- Sequence to Sequence Learning with Neural Networks, 2014.
https://arxiv.org/abs/1409.3215
1.7.3 Promise of RNNs
-
Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling, 2014 .
-
Applying LSTM to Time Series Predictable through Time-Window Approaches, 2001.
-
Long Short Term Memory Networks for Anomaly Detection in Time Series, 2015.
-
Learning Long-Term Dependencies with Gradient Descent is Difficult, 1994.
-
On the difficulty of training Recurrent Neural Networks, 2013.
https://arxiv.org/abs/1211.5063
1.7.4 LSTMs
- Long Short-Term Memory, 1997.
- Learning to forget: Continual prediction with LSTM, 2000.
- A Novel Connectionist System for Unconstrained Handwriting Recognition, 2009.
- Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, 2005
1.7.5 LSTM Applications
-
Show and Tell: A Neural Image Caption Generator, 2 0 1 4 .
https://arxiv.org/abs/1411.4555 -
Sequence to Sequence Learning with Neural Networks, 2 0 1 4 .
https://arxiv.org/abs/1409.3215 -
Generating Sequences With Recurrent Neural Networks, 2 0 1 4 .
https://arxiv.org/abs/1308.0850
2.How to Train LSTMs
本章节讲解了用于训练LSTMs的时间反向传播算法。完成本课后,你将会知道:
- 什么是时间的反向传播,以及它如何与多层感知器网络使用的反向传播训练算法相关联。
- 导致需要通过时间进行**截断反向传播(Truncated Backpropagation)**的动机,这是LSTMs深度学习中最广泛使用的变体。
- 考虑配置“经过时间截断的反向传播”以及研究和深度学习库中使用的规范配置的概念。
- 关于配置“经过时间截断的反向传播”以及研究和深度学习库中使用的规范配置的一种表示法。
2.1 Backpropagation Training Algorithm
反向传播指的是两件事:
- 导数计算的数学方法及导数链式法则的应用。
- 更新网络权值以最小化误差的训练算法。
本课中使用的正是后一种对反向传播的理解。反向传播训练算法的目标是修改神经网络的权值,使网络输出相对于相应输入的期望输出的误差最小化。它是一种监督学习算法,允许网络根据特定的错误进行纠正。一般算法如下:
- 提供一个训练输入模式,并通过网络传播它以获得输出。
- 将预测输出与预期输出进行比较,并计算误差。
- 计算误差对网络权值的导数。
- 调整权重以使误差最小化。
- 重复。
2.2 Unrolling Recurrent Neural Networks
递归神经网络的一个简单概念是作为一种神经网络,它从先前的时间步中获取输入。 我们可以用一个图表来证明这一点。
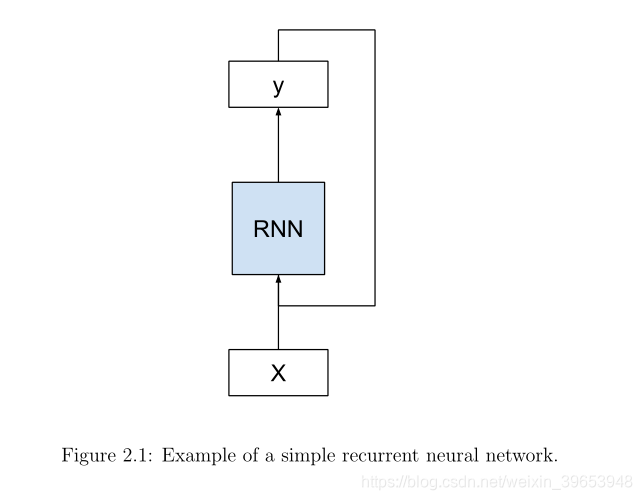
RNNs是适合的,并在许多时间步长的预测。随着时间步长的增加,具有循环连接的简单图开始失去所有意义。我们可以通过在输入序列上展开或展开RNN图来简化模型。
2.2.1 Unfolding the Forward Pass
考虑这样一种情况,我们有多个输入(X(t), X(t+1),…)的时间步长,多个内部状态(u(t), u(t+1),…)的时间步长,以及多个输出(y(t), y(t+1),…)的时间步长。我们可以将网络示意图展开成一个没有任何循环的图,如下图所示。
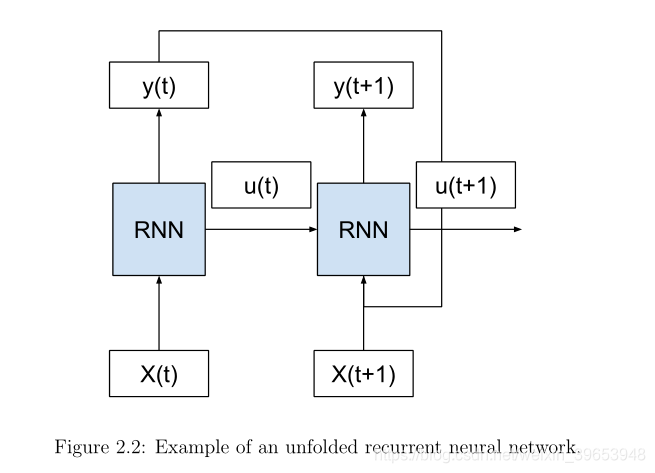
可以看到,我们移动的循环和上一个时间步骤的输出(y(t))和内部状态(u(t))作为处理下一个时间步骤的输入被传递到网络。这个概念的关键是网络(RNN)在展开的时间步之间不发生变化。具体来说,每个时间步使用相同的权值,只有输出和内部状态不同。通过这种方式,整个网络(拓扑结构和权值)在输入序列中的每个时间步都被复制。
我们可以将这一概念进一步推广,将网络的每个副本视为同一前馈神经网络的一个附加层。较深的层作为输入前一层的输出以及一个新的输入时间步长。这些层实际上是同一组权值的所有副本,内部状态从一层更新到另一层,这可能是这个经常使用的类比的延伸。
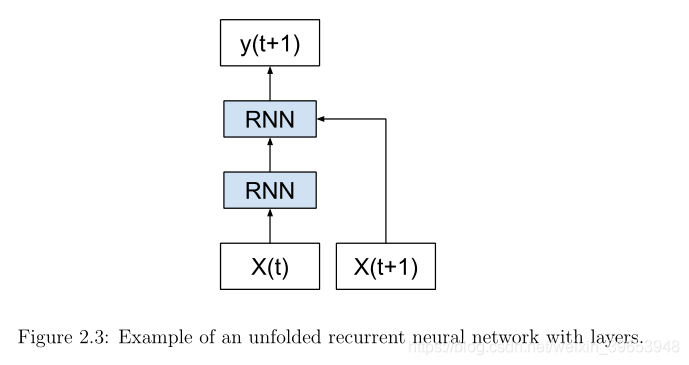
RNNs沿着时间维度展开,就可以被看作是所有层具有相同权值的深度前馈网络。— Deep learning, Nature, 2015.
这是一个有用的概念工具和可视化工具,有助于理解在转发过程中网络中发生的事情。这可能是也可能不是深度学习库实现网络的方式。
2.2.2 Unfolding the Backward Pass
网络展开的思想在递归神经网络实现后向遍历的过程中起着越来越重要的作用。
与[时间反向传播]的标准一样,网络是随时间展开的,因此到达各层的连接被视为来自前一个时间步长。— Framewise phoneme classification with bidirectional LSTM and other neural network architectures, 2005.
重要的是,给定时间步的误差反向传播取决于网络在前一时间步的激活。这样,反向传递需要展开网络的概念化。误差被传播回序列的第一个输入时间步,以便计算误差梯度并更新网络的权值。
和标准的反向传播一样,[时间反向传播]由链规则的重复应用组成。其微妙之处在于,对于递归网络,损失函数不仅依赖于隐藏层对输出层的影响,而且还依赖于它在下一个时间步对隐藏层的影响。— Supervised Sequence Labelling with Recurrent Neural Networks, 2008.
展开递归网络图也会引入其他关注点。每一个时间步都需要一个新的网络副本,而这又需要更多的记忆,特别是对于具有数千或数百万权重的大型网络。训练大型递归网络的记忆需求会随着时间步数上升到数百步而迅速膨胀。
… 需要按输入序列的长度展开RNN。通过展开一个RNN N次,网络中神经元的每一次激活都被复制N次,这会消耗大量的内存,特别是当序列很长的时候。这阻碍了在线学习或适应的小规模实施。此外,这种“完全展开”使得在共享内存模型(如图形处理单元(GPU))上使用多个序列进行并行训练成为可能。— Online Sequence Training of Recurrent Neural Networks with Connectionist Temporal
Classification, 2015.
2.3 Backpropagation Through Time
时间反向传播(BPTT)是反向传播训练算法在递归神经网络中的应用。在最简单的情况下,递归神经网络每一个时间步显示一个输入,并预测一个输出。
从概念上讲,BPTT通过展开所有输入时间步骤来工作。每个时间步都有一个输入时间步、一个网络副本和一个输出。然后计算并累积每个时间步的误差。网络将回滚并更新权重。算法总结如下:
- 向网络显示输入和输出对的时间步序列。
- 展开网络,然后计算并累积每个时间步骤中的错误。
- 卷起(Roll-up)网络并更新权重。
- 重复。
随着时间步数的增加,BPTT的计算开销可能会增加。如果输入序列由数千个时间步组成,则这将是单个权重更新所需的导数数。这可能会导致权重消失或爆炸(归零或溢出),并使缓慢的学习和模型技能变得嘈杂。
BPTT的一个主要问题是单参数更新的代价很高,这使得无法使用大量的迭代。— Training Recurrent Neural Networks, 2013.
一种最小化爆炸和消失梯度问题的方法是在对权重进行更新之前限制多少时间步。
2.4 Truncated Backpropagation Through Time
**截断时间反向传播(TBPTT)**是递归神经网络BPTT训练算法的改进版本,该算法一次处理一个时间步长,并定期对固定数量的时间步长进行更新。
截断的BPTT。。。一次处理一个时间步,每 k1 个时间步,它运行 k2 时间步的BPTT,所以如果k2很小,参数更新就很便宜。因此,它的隐藏状态暴露在许多时间步骤中,因此可能包含有关遥远过去的有用信息,这些信息将被机会主义地利用。— Training Recurrent Neural Networks, 2013.
算法总结如下:
- 向网络呈现输入和输出对的k1时间步序列。
- 展开网络,然后计算并累积k2时间步的错误。
- 卷起网络并更新权重。
- 重复。
TBPTT算法需要考虑两个参数:
- k1:更新之间的前向传递时间步数。通常,考虑到权重更新的频率,这会影响训练的速度或速度。
- k2:应用BPTT的时间步数。一般来说,它应该足够大,能够捕获问题中的时间结构,以便网络学习,值太大会梯度导致渐变消失。
2.5 Configurations for Truncated BPTT
我们可以更进一步,定义一个符号来帮助更好地理解BPTT。Williams和Peng在他们对BPTT的研究中提出了一种有效的基于梯度的递归网络轨迹在线训练算法,他们设计了一种符号来捕获截断和非截断配置的频谱,例如BPTT(h)和BPTT(h;1)。
我们可以修改这个符号并使用Sutskever的k1和k2参数。使用这个符号,我们可以定义一些标准或通用的方法:注意:这里n是指输入序列中的时间步总数:
- TBPTT(n,n):在序列结束时,在序列中的所有时间步执行更新(例如,经典BPTT)。
- TBPTT(1,n):时间步一次处理一个,然后更新,覆盖到目前为止看到的所有时间步(例如威廉斯和彭的经典TBPTT)。
- TBPTT(k1,1):网络可能没有足够的时间上下文来学习,严重依赖于内部状态和输入。
- TBPTT(k1,k2), where k1<k2<n:每个序列执行多个更新,可以加速训练。
- TBPTT(k1,k2),其中k1=k2:一种通用配置,其中固定数量的时间步用于向前和向后通过时间步(例如10s到100s)。
我们可以看到,所有的配置都是TBPTT(n,n)上的一个变体,本质上试图以更快的训练和更稳定的结果来近似相同的效果。文献中提出的典型TBPTT可被认为是TBPTT(k1,k2),w h e r e k1=k2=k和k<=n,其中所选参数很小(几十到几百个时间步)。这里,k是一个必须指定的参数。通常认为输入时间步的序列长度应限制在200-400之间。
2.6 Keras Implementation of TBPTT
Keras深度学习lib库提供了一种TBPTT的训练神经网络的实现方法。实现比上面列出的一般版本受到更多限制。具体来说,k1和k2值彼此相等且固定。
TBPTT(k1, k2), where k1=k2=k.
这是通过训练像LSTM这样的递归神经网络所需的固定大小的三维输入来实现的。LSTM期望输入数据具有以下维度:样本、时间步长和特征。它是这个输入格式的第二个维度,时间步,定义了在序列预测问题上用于向前和向后传递的时间步数。
因此,在为Keras中的序列预测问题准备输入数据时,必须仔细选择指定的时间步数。时间步骤的选择将影响以下两个方面:
- 前进过程中积累的内部状态。
- 用于更新后向通道上权重的梯度估计。
请注意,默认情况下,网络的内部状态在每个批处理之后重置,但是可以通过使用所谓的有状态LSTM并手动调用重置操作来更明确地控制何时重置内部状态。稍后再谈。
该算法的Keras实现本质上是不截断的,要求在训练模型之前直接对输入序列执行任何截断。我们可以认为这是手动截断的BPTT。Sutskever称这是一个幼稚的方法。
… 一种简单的方法,将1000个长序列分成50个序列(比如说,每个序列的长度为20),并将每个序列的长度为20作为一个单独的训练案例。这是一种明智的方法,可以在实践中很好地工作,但它对跨越20多个时间步的时间依赖性是盲目的。— Training Recurrent Neural Networks, 2013
这意味着作为构建问题框架的一部分,您必须将长序列分割成子序列,子序列的长度既足以捕获进行预测的相关上下文,又足以对网络进行有效的训练。
2.7 Further Reading
2.7.1 Books
- Neural Smithing, 1999.
http://amzn.to/2u9yjJh - Deep Learning, 2016 .
http://amzn.to/2sx7oFo - Supervised Sequence Labelling with Recurrent Neural Networks, 2008.
http://amzn.to/2upsSJ9
2.7.2 Research Papers
-
Online Sequence Training of Recurrent Neural Networks with Connectionist Temporal Classification, 2015.
https://arxiv.org/abs/1511.06841 -
Framewise phoneme classification with bidirectional LSTM and other neural network architectures, 2005.
-
Deep learning, Nature, 2015.
-
Training Recurrent Neural Networks, 2013.
-
Learning Representations By Backpropagating Errors, 1986.
-
Backpropagation Through Time: What It Does And How To Do It, 1990.
-
An Efficient Gradient-Based Algorithm for On-Line Training of Recurrent Network Trajectories, 1990.
-
Gradient-Based Learning Algorithms for Recurrent Networks and Their Computational Complexity, 1995.
参考:Jason Brownlee 《long-short-term-memory-networks-with-python》chapter 1-2
