概要
原文链接
Deep Residual Learning for Image Recognition
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Microsoft Research
内容概括

- 证明了模型退化问题:随着网络深度的增加,网络越来越难收敛,不是因为过拟合(56层网络训练集损失比20层的高,如图1)或梯度弥散和梯度爆炸问题(网络使用了BN),而是因为非线性激活函数的加入阻碍了线性变换的能力。
-------------------------------------------------------------------------------------------------------------------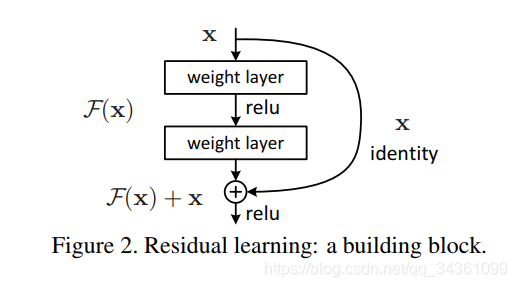
2. 提出残差学习,让深度神经网络学习改变量。解释:设当前层张量为
,理想的下一层的输出目标是
,那么原来的卷积层应该学习
的变换函数,而残差卷积块学习的是
,即残差。换句话说就是普通的神经网络层学习如何从当前层变换到一下层,而残差层学习该如何在当前层的基础上小修小补使其变为下一层。
-------------------------------------------------------------------------------------------------------------------
3. 恒等映射:假设当前层的张量为
,经过一层神经网络,我们希望它的输出还是
,这就称为恒等映射。设当前层对应的映射函数为
,那么对于普通层应该做到对任意
有
,由于非线性激活函数的存在,这比较难做到,而对于残差层只需要
即可达到恒等映射,因此残差层提高了网络层的线性变换能力。图7证明了残差网络每层的激活响应标准差小于普通网络。
-------------------------------------------------------------------------------------------------------------------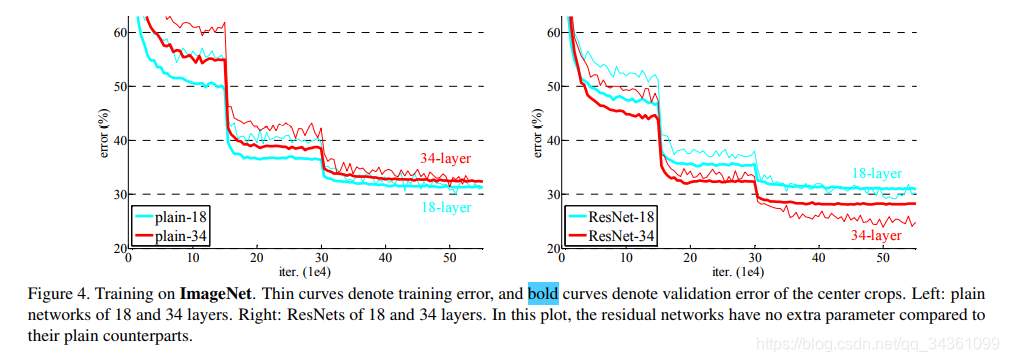
4. 图4显示了残差连接的效果,论证了以上观点。
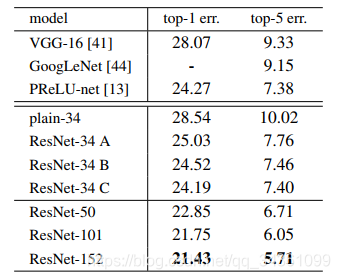
5. 对于如何残差连接,作者给出了3套方案:A. 快捷连接时直接加上输入
,如果下一层的维度比上一层的多,那么对于多余的部分用0代替。 B. 如果上下层维度一致直接加上
,否则加上线性变换后的
,使得线性变换后的X的维度与下一层的一致。 C. 全部都加上线性变换后的
。上图为实验结果,可见 C > B > A 作者认为加上在这里加上线性变换后的
的效果比直接加上
的仅仅有微弱的提升,这很有可能是增加的线性变换层提供了更多的可训练参数导致的,没有实际意义而且增大了单个残差块的计算量,因此直接选择B方案即可。
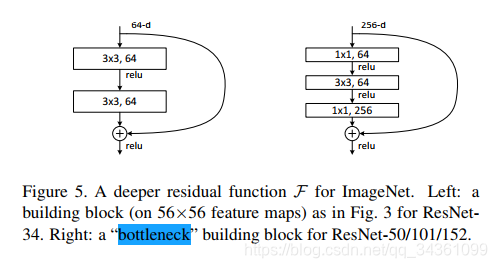
6. 作者提出了3层的残差块结构“bottleneck”,比原本俩层的更省计算资源。假设输入的张量是
的,输出张量为
的,那么第一种的参数量(忽略偏置项)为
,第二种为
,不仅节省了单个残差层的参数量还多引入了一次非线性变换,提升抽象能力。在这里1*1的卷积层实际上是做了降维的工作。但值得注意的是一层第一种残差块的感受野相当于两层第二种的。
生疏词汇
词都不会还想看论文?? 〒▽〒 ?
| 词汇 | 意义 |
|---|---|
| substantially | adv. 实质上;大体上;充分地 |
| explicitly | adv. 明确地;明白地 |
| reformulate | vt. 再用形式表示 |
| empirical | adj. 经验主义的,完全根据经验的;实证的 |
| solely | adv. 单独地,唯一地 |
| foundations | n. [建] 基础(foundation的复数);房基 |
| reveals | vt. 揭示(reveal第三人称单数) |
| crucial | adj. 重要的;决定性的;定局的;决断的 |
| exploit | vt. 开发,开拓;剥削;开采 |
| nontrivial | adj. 非平凡的 |
| notorious | adj. 声名狼藉的,臭名昭著的 |
| vanishing | adj. 消没的 |
| exploding | n. 爆炸,爆发;水热炸裂 |
| hamper | vt. 妨碍;束缚;使困累 |
| intermediate | n. [化学] 中间物;媒介 |
| stochastic | adj. [数] 随机的;猜测的 |
| degradation | n. 退化;降格,降级;堕落 |
| saturated | v. 使渗透,使饱和(saturate的过去式) |
| shallower | 肤浅的(shallow的比较级) |
| counterpart | n. 副本;配对物;极相似的人或物 |
| construction | n. 建设;建筑物;解释;造句 |
| feasible | adj. 可行的;可能的;可实行的 |
| underlying | adj. 潜在的;根本的;在下面的;优先的 |
| recast | vt. 重铸;彻底改动 |
| hypothesize | vt. 假设,假定 |
| phenomena | n. 现象(phenomenon 的复数 ) |
| generic | adj. 类的;一般的;属的;非商标的 |
| applicable | adj. 可适用的;可应用的;合适的 |
| probabilistic | adj. 概率性的;或然说的,盖然论的 |
| quantization | n. [量子] 量子化;分层;数字化 |
| coarser | adj. 粗糙的;粗俗的;下等的 (coarse的变形) |
| auxiliary | adj. 辅助的;副的;附加的 |
| concurrent | adj. adj. 并发的;一致的;同时发生的;并存的 |
| demonstrated | 演示 |
| asymptotically | adv. 渐近地 |
| complicated | adj. 难懂的,复杂的 |
| counterintuitive | adj. 违反直觉的 |
| perturbations | n. [流] 扰动;不安(perturbation的复数形式) |
| omitted | adj. 省略了的;省去的 |
| comparisons | n. 比较;类似(comparison的复数形式);处于对比状态 |
| negligible | adj. 微不足道的,可以忽略的 |
| economical | adj. 经济的;节约的;合算的 |
| inspired | v. 激发(inspire的过去分词);鼓舞 |
| philosophy | n. 哲学;哲理;人生观 |
| preserve | vt. 保存;保护;维持;腌;禁猎 |
| solid | n. 固体;立方体 |
| dotted | v. 点缀(dot的过去分词);布满;打点于 |
| projection | n. 投射;规划;突出;发射;推测 |
| horizontal | adj. 水平的;地平线的;同一阶层的 |
| flip | n. 弹;筋斗 |
| plateaus | n. 高原;[地理] 台地;停滞时期 |
| bold | adj. 大胆的,英勇的;黑体的;厚颜无耻的;险峻的 |
| procedures | n. 程序;规程(procedure的复数) |
| throughout | adv. 自始至终,到处;全部 |
| extent | n. 程度;范围;长度 |
| conjecture | n. 推测;猜想 |
| exponentially | adv. 以指数方式 |
| impact | vt. 挤入,压紧;撞击;对…产生影响 |
| observations | n. 观察,观察值;观察结果;(观察后发表的)言论(observation的复数形式) |
| feasibly | 可行地 |
| effectiveness | n. 效力 |
| bottleneck | n. 瓶颈;障碍物 |
| marginally | adv. 少量地;最低限度地;在栏外;在页边 |
| witnessed | n. 证人;目击者;证据 |
| metrics | n. 度量;作诗法;韵律学 |
| outperforms | vt. 胜过;做得比……好 |
| conducted | v. 管理(conduct的过去分词);引导;指挥 |
| intentionally | adv. 故意地,有意地 |
| deviations | n. 差异,偏差(deviation复数) |
| magnitudes | n. 大小;量级;[地震] 震级;重要;光度 |
| aggressively | adv. 侵略地;攻击地;有闯劲地 |
| regularization | n. 规则化;调整;合法化 |
| distracting | v. 使分心(distract的ing形式);转移注意力 |
| attributed | v. 归于(attribute的过去式,过去分词);属性化 |
| remarkably | adv. 显著地;非常地;引人注目地 |
| solely | adv. 单独地,唯一地 |
| analogous | adj. 类似的;[昆] 同功的;可比拟的 |
| constant | adj. 不变的;恒定的;经常的 |
| offsets | n. 抵消交易;船线坐标 |
| statistics | n. 统计;统计学;[统计] 统计资料 |
| completeness | n. 完整;完全;完成;圆满;结束 |
| proposal | n. 提议,建议;求婚 |
| inference | n. 推理;推论;推断 |
| suppression | n. 抑制;镇压;[植] 压抑 |
| subsequent | adj. 后来的,随后的 |
| revisit | vt. 重游;再访;重临 |
| refinement | n. 精制;文雅;[化工][油气][冶] 提纯 |
| surpassing | v. 胜过(surpass的ing形式) |
| strategy | n. 战略,策略 |
| agnostic | adj. 不可知论的 |
| oracle | n. 神谕;预言;神谕处;圣人 |
| warped | adj. 弯曲的;反常的 |
笔记
重点句子
- Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization [23, 9, 37, 13] and intermediate normalization layers[16], which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22].
学习更好的网络就像叠加更多的层一样简单吗?回答这个问题的一个障碍是众所周知的渐变消失/爆炸问题[1,9],它从一开始就阻碍了收敛。然而,这个问题主要通过规范化初始化[23、9、37、13]和中间规范化层[16]来解决,这使得具有数十层的网络能够开始收敛,使用反向传播[22]进行随机梯度下降(SGD)。 - With the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error.
随着网络深度的增加,准确度逐渐饱和(这可能并不令人惊讶),然后迅速下降。出乎意料的是,这种退化并不是由过度拟合造成的,在一个合适的深度模型中添加更多的层会导致更高的训练误差。 - Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping.
我们不希望每个堆叠的层都能直接匹配所需的底层映射,而是显式地让这些层匹配残差映射。 - It would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
将残差推到零要比通过一堆非线性层来匹配一个恒等映射容易得多。 - The degradation problem suggests that the solvers might have difficulties in approximating identity mappings by multiple nonlinear layers.
退化问题表明,求解者可能难以用多个非线性层逼近身份映射。 - The dimensions of x and F must be equal in Eqn.(1). If this is not the case (e.g., when changing the input/output channels), we can perform a linear projection Ws by the shortcut connections to match the dimensions:
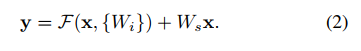

- These plain networks are trained with BN [16], which ensures forward propagated signals to have non-zero variances.
这些普通网络使用BN[16]进行训练,这确保了正向传播的信号具有非零方差。 - C is marginally better than B, and we attribute this to the extra parameters introduced by many (thirteen) projection shortcuts.
C略好于B,我们将此归因于许多(十三)个投影快捷方式引入的额外参数。
下载链接
注:生疏词汇(蓝色) 重点(黄色) 次重点(绿色) 疑问(红色) 可以使用Edge浏览器打开后修改笔记
