目录
@
0. 论文链接
1. 概述
从AlexNet出现后,后面的模型包括VGG,GoogLe-Net等都是想办法让网络边更宽更深,因为大量的实验证明网络更深更宽它的性能会更好。比较容易想到的是一味的增加深度会使得梯度爆炸/消失,但这问题在很大程度上使用标准化初始赋值跟中间层(BN)解决。但经过实验发现,如果一味的堆叠层数,性能反而会更差(无论在训练集还是测试集上)。
在上述背景下,作者提出了一种残差网络,即当前layer不只从上一层获取输入,也从前面某一层获取输入,这种“捷径”不会增加额外的参数或者计算量,同时可以现有的库进行构建而不用做改进。如下图:
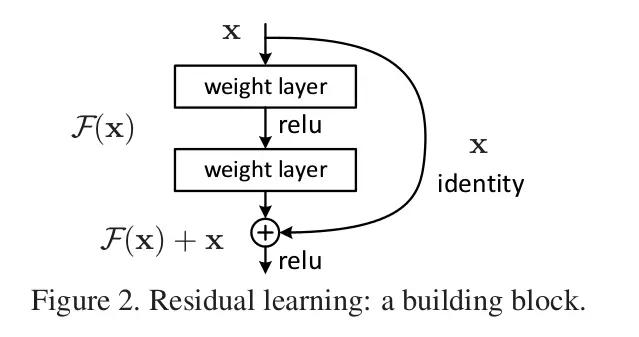
作者在ImageNet使用了152层的残差网络,最终获得了 3.57%的top-5 error,然后获得了各种第一。之前的工作也有与“Residual Representation” 与 “Shortcut Connections”相关的,他们的研究也证明了在不同尺度上进行残差学习有助于模型的收敛与性能, Shortcut Connections有助于防止梯度消失/爆炸(Google-Net直接连接辅助分类器)
2. 残差学习
读了好一会才理解文章中构建残差块的动机与想法是什么,主要还是读的文章少了,对了“underlying mapping”,“identity mapping”等的理解产生了奇异,导致久久不能理解文中的表达的意思。下面详细的说一下残差学习这方面。
首先,按照正常的想法, 在一个浅层模型加一些其他的layer他的训练错误率最高不能高过原来的浅层网络,因为如果浅层网络已经是最优的了, 那么我完全可以后面添加的layer自身映射(identity mapping),前面的layer相当于直接从最优浅层网络复制过来,这样即使是深层网络其实相当于原来的浅层网络,中间某些层来学习前面网络的某一层,学习的输入feature map本身,可是经过大量实验发现网络层增加后错误率会高不少,如下图:

恺明大神从这种反常的线性中得到了启发,是不是对于通过几层非线性layer去学习“自身映射”有一定的困难,因此他提出了一种残差学习的方式:
假设通过几个非线性层可以拟合任意复杂函数(这也是神经网络一直讨论与争议的一个点,不过好像今年的ICML有一篇文章证明了在网络足够宽的情况下,确实可以拟合任意复杂函数),用\(H(X)\)表示一些堆叠网络层要拟合的最优映射,\(X\)表示这几层layer中第一层的输入,那么假设那一些堆叠网络层可以拟合\(H(X)\)的话,当然也可以拟合残差函数\(F(X) := H(X)-X\)(假设输入与输出的维数相同),因此原来要拟合函数也就是\(F(X) + X\),极端一点,如果自身映射是最优的,那么相对用几个堆叠的非线性网络去拟合一个identity mapping,把残差(\(F(X)\))逼近于0更容易一点。
3. Identity Mapping by shortcuts
可以把一个残差块表示成如下所示:
\[ y = F(x, \{W_i\}) + W_sx \]
其中x跟y是残差块中间堆叠layer的输入与输出, \(F(x, \{W_i\})\)代表要学习的残差函数。因为这里必须保证x与 \(F(x, \{W_i\})\)输出的维度相同,因此如果维度不同可以通过\(W_s\)来调节相同的维度,残差块通常包含2,3或者更多的layers,一层相当于一个线性映射,效果不好。对于卷积层,其实就是将对应的两个feature map相加,channel by channel。
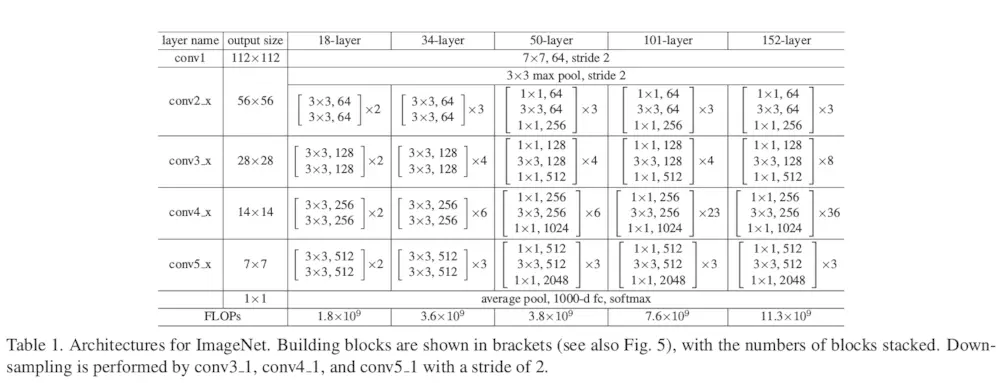
4. Network Architectures
对于网络结构,文章中的结构图十分清晰:

网络参数图:
普通网络
遵循两个设计规则:(关于第二条看不太懂)
- 对于相同的尺寸的输出feature map,每层必须含有相同数量的过滤器。
- 如果feature map的尺寸减半,则过滤器的数量必须翻倍,以保持每层的时间复杂度。
通过观察可以看到,网络直接通过卷积层(stride=2)进行下采样,网络末端以全局的均值池化层结束,有1000路的全连接层(Softmax激活)。含有权重的网络层的总计为34层
另外,当输入输出尺寸发生增加时(图3中的虚线的快捷连接),我们考虑两个策略:
(a)快捷连接仍然使用自身映射,对于维度的增加用零来填补空缺。此策略不会引入额外的参数;
(b)\(W_s\)(之前公式介绍过的)被用来匹配尺寸(靠1×1的卷积完成)。
对于这两种选项,当快捷连接在两个不同大小的特征图谱上出现时,用stride=2来处理。
5. 训练细节
ImageNet中我们的实现遵循[21,40]的实践。调整图像大小,其较短的边在[256,480]之间进行随机采样,用于尺度增强[40]。224×224裁剪是从图像或其水平翻转中随机采样,并逐像素减去均值[21]。使用了[21]中的标准颜色增强。在每个卷积之后和激活之前,我们采用批量归一化(BN)[16]。我们按照[12]的方法初始化权重,从零开始训练所有的简单/残差网络。我们使用批大小为256的SGD方法。学习速度从0.1开始,当误差稳定时学习率除以10,并且模型训练高达\(60×10^4\)次迭代。我们使用的权重衰减为0.0001,动量为0.9。根据[16]的实践,我们不使用丢弃[13]。
在测试阶段,为了比较学习我们采用标准的10-crop测试[21]。对于最好的结果,我们采用如[40, 12]中的全卷积形式,并在多尺度上对分数进行平均(图像归一化,短边位于\(\{224, 256, 384, 480, 640\}\)中)。
PS: 因为要复现Resnet,所以这一段直接找了网上的翻译