Introduction
(1)Motivation:
当前提出的GAN方法存在生成器和reid判别模型分离,reid模块直接用生成的图像进行训练,效果受到局限。
(2)Contribution:
作者提出了一个联合判别、生成学习的网络:DG-Net。该策略引入了生成模块,将每个行人图像编码到两个空间:样貌空间编码行人的外貌和其它相关的语义信息;结构空间编码行人的几何、位置结构等信息,如下表所示:

每个行人图像在保持样貌空间不变的情况下,结合其它行人的结构空间,生成其它姿态、背景的行人图像,如下图的行所示;与之相反,每个行人图像保持结构空间不变,结合其它行人的样貌特征,如下图的列所示。通过这种策略,生成了高质量的行人图像。

Method
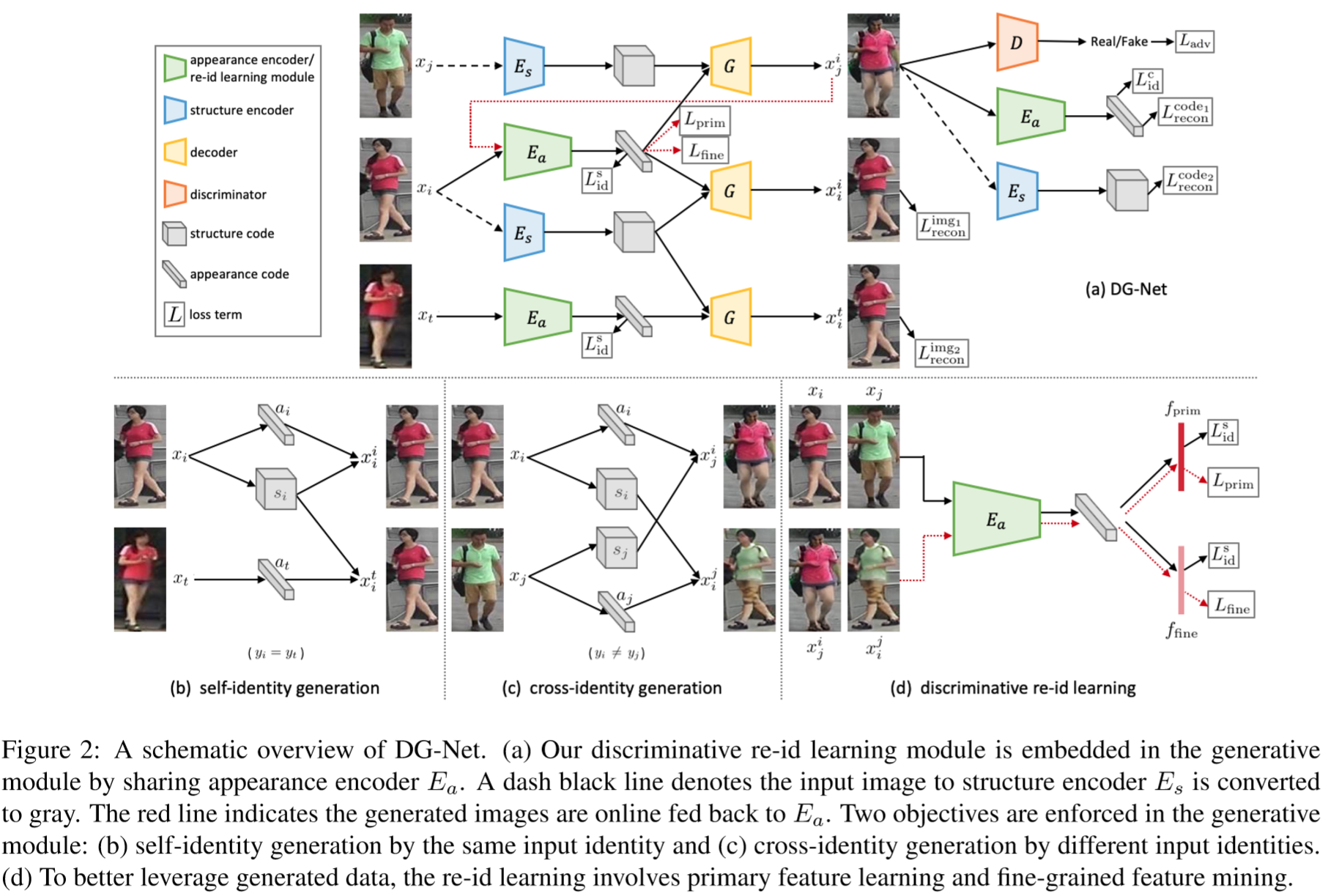
(1)生成模块:
假设真实图像和标签为:![]() 和
和![]() ,其中 N 为图像的数量,
,其中 N 为图像的数量,![]() ,K为数据包含的行人ID数量。给定两个真实图像
,K为数据包含的行人ID数量。给定两个真实图像![]() 和
和![]() ,生成模块通过对换样貌编码和结构编码,生成另外两幅图像,包括样貌编码器
,生成模块通过对换样貌编码和结构编码,生成另外两幅图像,包括样貌编码器![]() 和结构编码器
和结构编码器![]() ,再通过解码器还原出生成的图像
,再通过解码器还原出生成的图像![]() ,判别器 D 用于判断图像是生成的还是真实的。当 i = j 时,生成器可以被视为自编码器,即
,判别器 D 用于判断图像是生成的还是真实的。当 i = j 时,生成器可以被视为自编码器,即![]() 。为了减少样貌编码对于提取结构编码的影响,在输入
。为了减少样貌编码对于提取结构编码的影响,在输入![]()
之前对图片进行灰度化处理。
生成模块采用如下两种处理:
① Self-identity generation:
给出一张图片![]() ,生成模块首先学习如何重构自身图片,采用了像素损失:
,生成模块首先学习如何重构自身图片,采用了像素损失:
![]()
将图片![]() 的结构放入同一个行人的图片
的结构放入同一个行人的图片![]() 上,损失函数为:
上,损失函数为:
![]()
判别器的ID损失为:
![]()
② Cross-identity generation:
对于两个不同ID的图片,损失函数为:
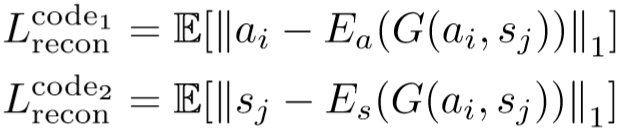
生成图像的ID损失函数为:
![]()
引入生成对抗损失函数,使得生成的数据更符合真实数据分布:
![]()
(2)判别模块:
① 初级特征学习:
将原始数据训练的模型作为教师模型,其预测结果为![]() ,提供软标签。提出的优化模型作为学生模型预测的结果为
,提供软标签。提出的优化模型作为学生模型预测的结果为![]() 。损失函数为:
。损失函数为:
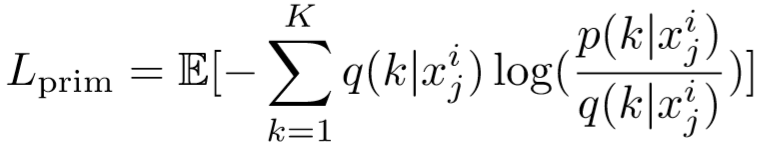
其中 K 为ID的数量。
读到这段的时候我产生了一个困惑:A穿着B的衣服,Label算是A还是B呢?
我的理解是,这里采用了教师模型作为软标签,不再确切给出是A还是B,而是从样貌上直观评估像A的概率和像B的概率。
② 细粒度特征挖掘:
将穿着不同,但结构相同的图片作为同一类,从而提取更细粒度的特征。损失函数为:
![]()
(3)优化算法:
总损失函数:
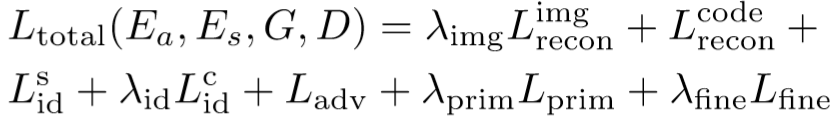
Experiment
(1)实验设置:
① 数据集设置:Market-1501、DukeMTMC-reID、MSMT17;
② 实验细节:采用ResNet50作为骨干网络;初级特征和细粒度特征均为512维向量;编码器输出的编码为128*64*32,包含4个卷积层和4个残差块;解码器为4个残差块接4个卷积层;判别器采用多尺度PatchGAN,采用三种输入图像的尺寸:64*32,128*64,256*128;测试仅采用样貌编码器作为特征提取,得到两个512维的向量进行concat;
③ 参数设置:![]() 的训练参数:学习率 = 0.002,momentum = 0.9;
的训练参数:学习率 = 0.002,momentum = 0.9;![]() 的训练:优化器采用Adam,学习率 = 0.0001,
的训练:优化器采用Adam,学习率 = 0.0001,![]() 。
。
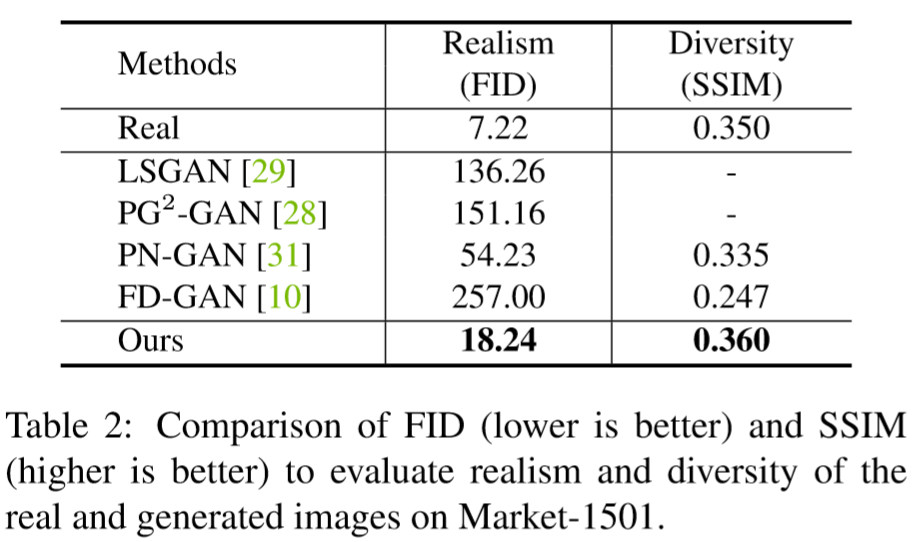
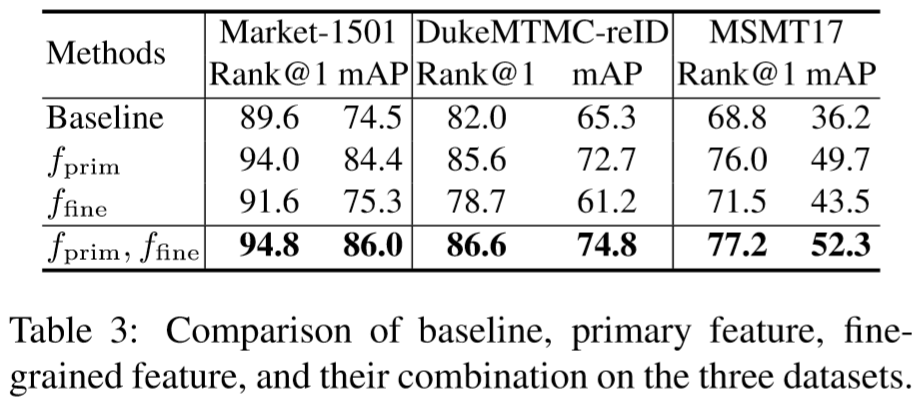
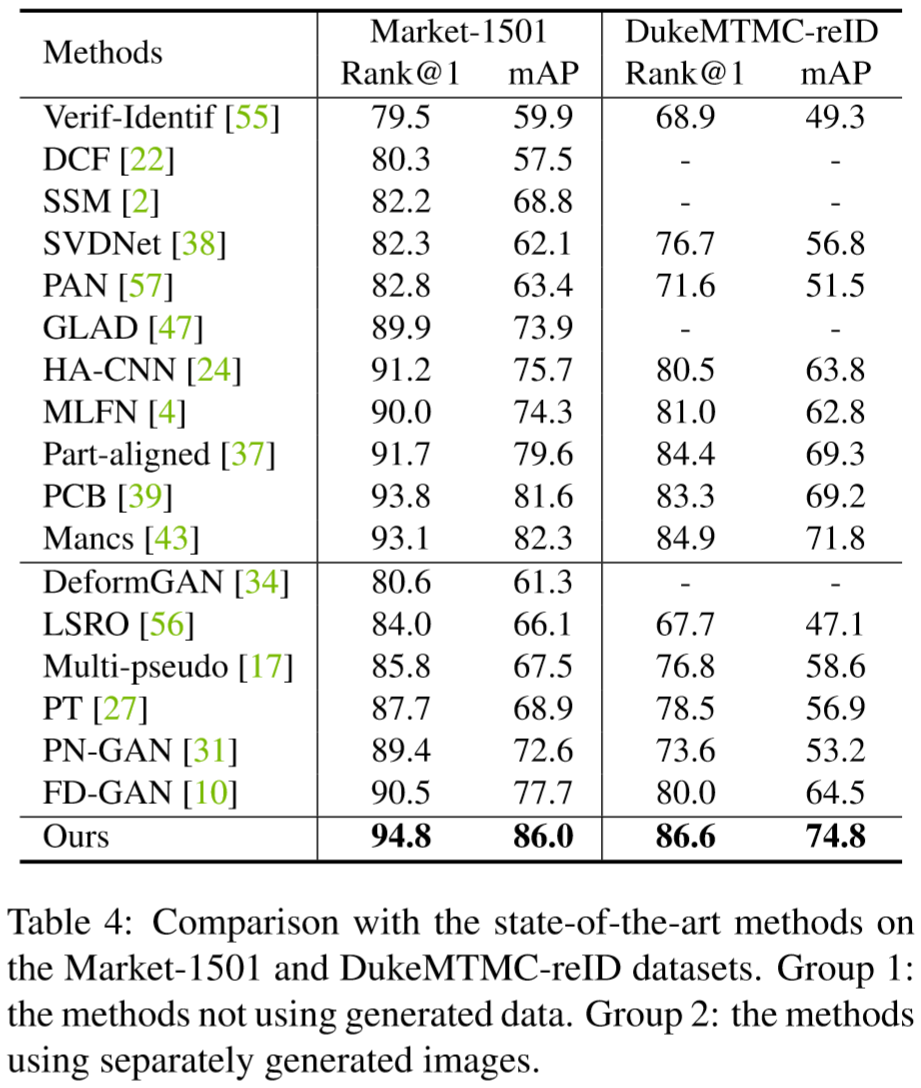
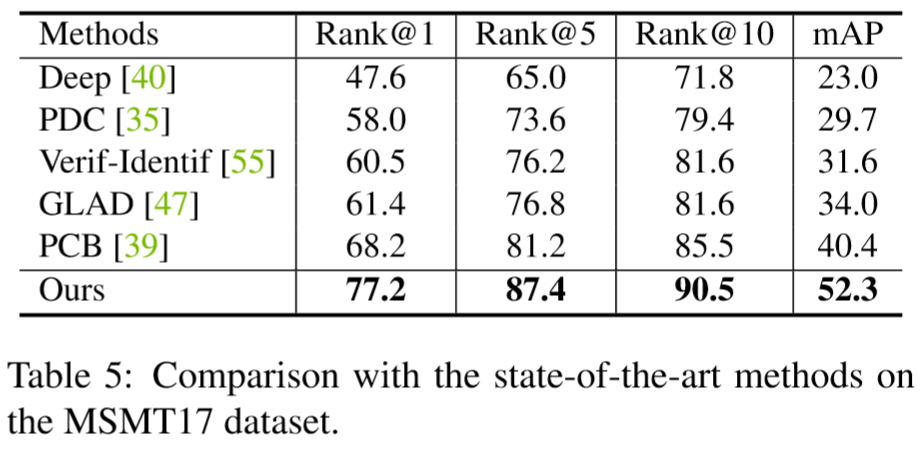
(2)实验结果: