胶囊网络是Hinton老爷子近几年提出的一种新型的神经网络,他认为胶囊网络的设计更加符合人类神经元的原理,是未来可以替代传统神经网络的一种新的神经网络。
提出背景
提出背景其实就是现有某种算法出现了一些比较大的缺陷。这个算法就是卷积神经网络。卷积神经网络(CNN)可以说是风靡一时,但是其还是有不少问题的。
问题1:无法很好判断空间关系
我们知道,卷积神经网络是利用卷积运算的神经网络。卷积运算(如下图),通俗理解就是将一小片数据通过加权变成以个新的数字。
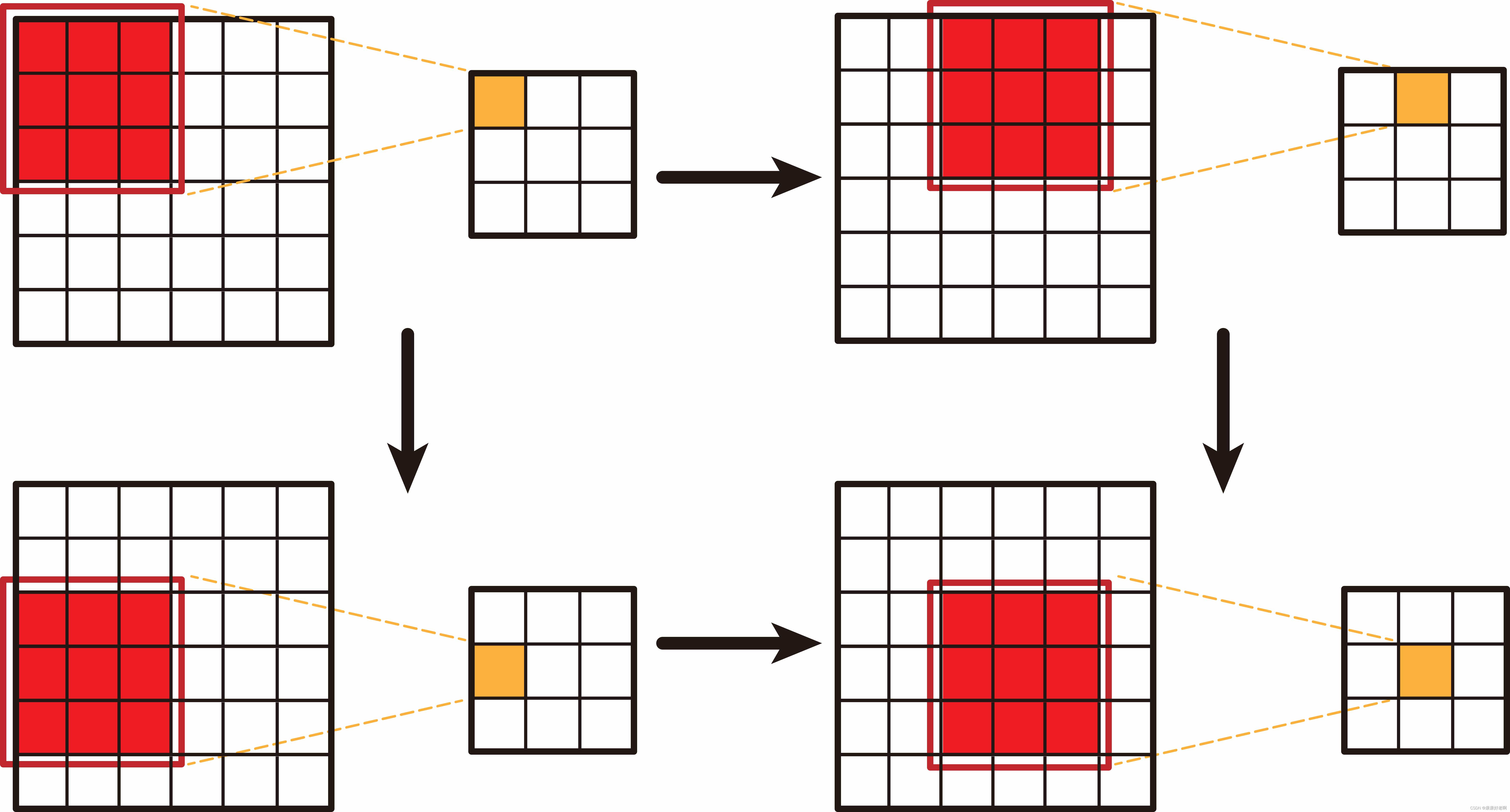
通过上图不难发现,卷积运算会将原有的数据空间位置给破坏。因为被卷积的数据可能因为卷积被分配到很多不同新的位置,从而将空间关系进行破坏。
网上也时常流传一张梗图:
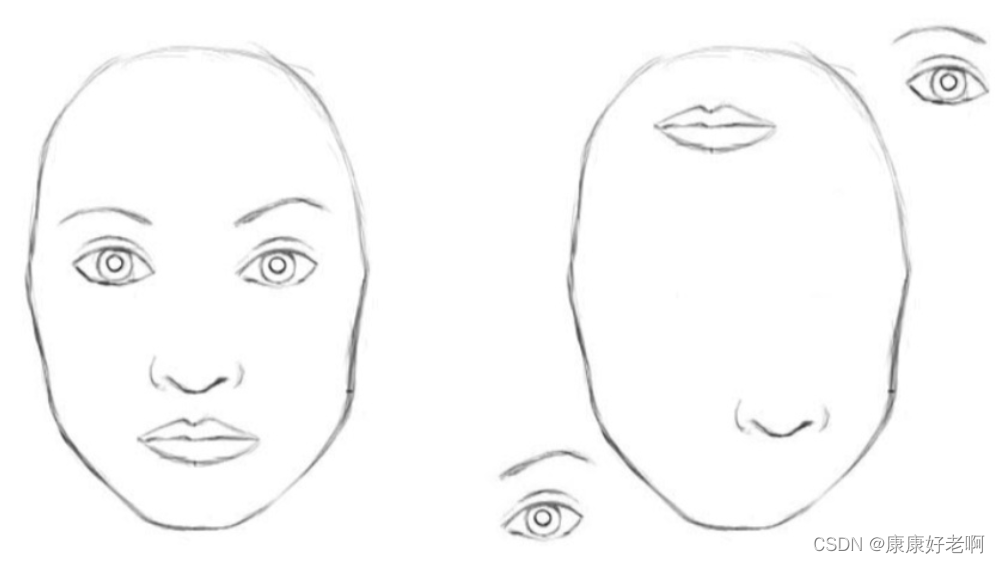
就是说卷积神经网络无法分辨左右两张图,都会认为左右都是一张人脸。
那为什么卷积神经网络还这么好用呢,因为现实中确实没有长右边那张图的人…
问题2:池化损失信息
卷积神经网络有很重要的一步就是池化操作。常见的池化有平均池化和最大池化。
平均池化就是将一块区域内所有数据取平均值,作为新的输出;最大池化就是将一块区域内所有数据的最大值作为新的输出。
关于池化可以参考[博客][https://zhuanlan.zhihu.com/p/78760534]
目前来看,最大池化可能应用更广一些,因为平均池化会导致重要的特征值被不重要的特征值给“拖累”,但是最大池化又会更多地丢失空间信息(因为将不重要的信息忽略了)。池化操作主要的目的是降低参数量,降低的过程带来了空间位置的损失。
胶囊网络
核心思想
胶囊网络的核心思想就是通过反推将图形的空间位置信息等推导出来。现在理解这些有些困难,当下面详细内容介绍过后,应该对此有一个更为深刻的理解。
下面我们来介绍一下胶囊网络的具体内容
具体内容——单个胶囊网络思路
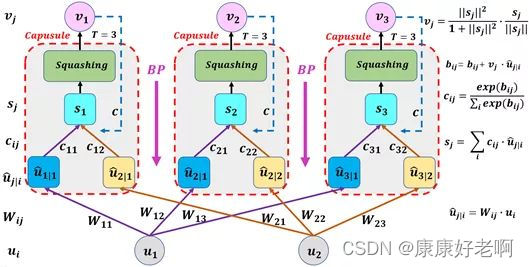
我们根据这张图从下到上进行分析。
1、 u i → u j ∣ i u_i\to u_{j|i} ui→uj∣i部分
这一步是通过权重矩阵 W i j W_{ij} Wij,将 u i u_i ui所在空间映射 u j ∣ i u_{j|i} uj∣i到所在空间,进行了一次空间变换。值得注意的是,这一步在传统的神经网络里是并没有的。
2、 u j ∣ i → s j u_{j|i}\to s_j uj∣i→sj部分
这一步是通过矩阵 c i j c_{ij} cij实现的。其实这一步才对应的是传统神经网络的权重输入,但是抛弃了常数项。通过下面这个图可能看得会更加清晰:
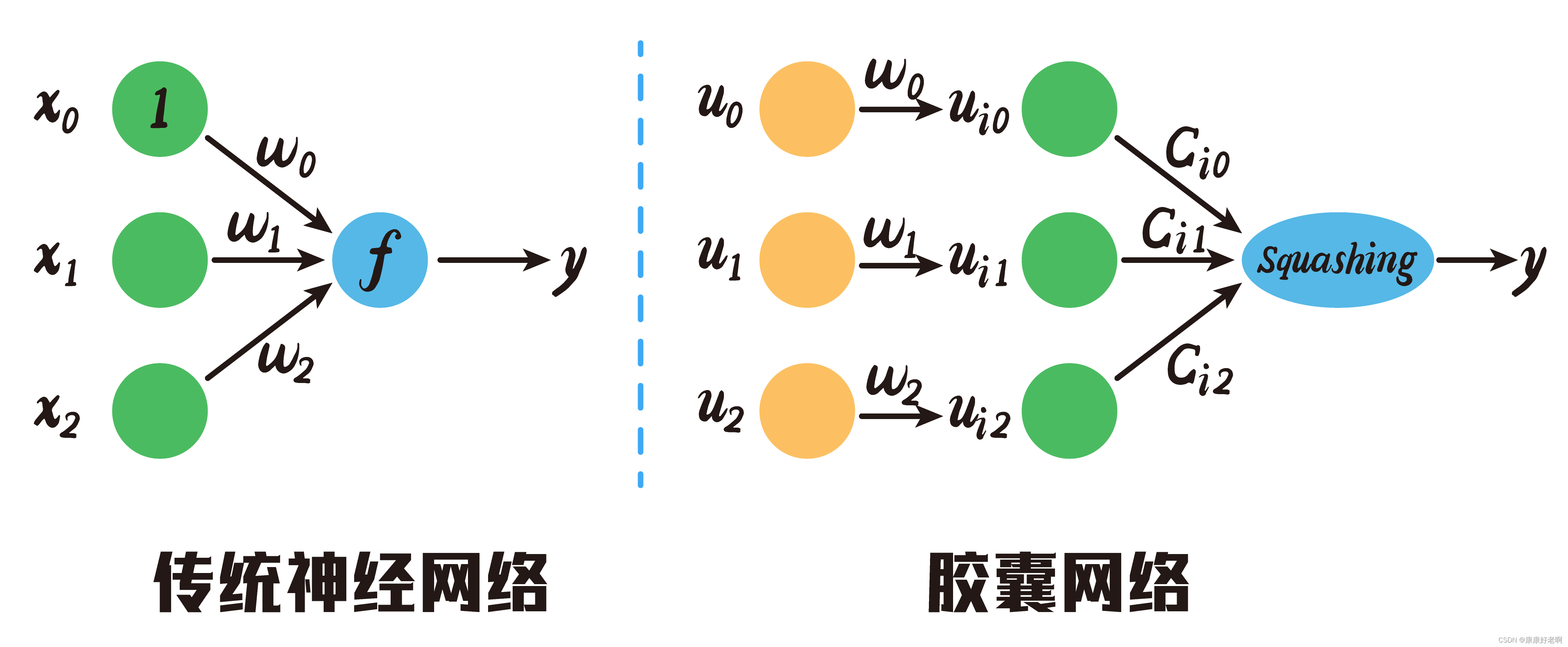
那么可能有人会有疑问,相对于传统的神经网络,为什么需要这两步操作呢?原因如下:
其实第一步乘以 W i j W_{ij} Wij,实现的是一个低层特征到高层特征的转换,比如将低层特征翅膀转化到高层特征老鹰,低层特征翅膀转化到高层特征鱼,只不过翅膀转化到老鹰的权重更高,翅膀转化到鱼的权重更低。这样就完成了低层信息到高层信息的转换。如下图:
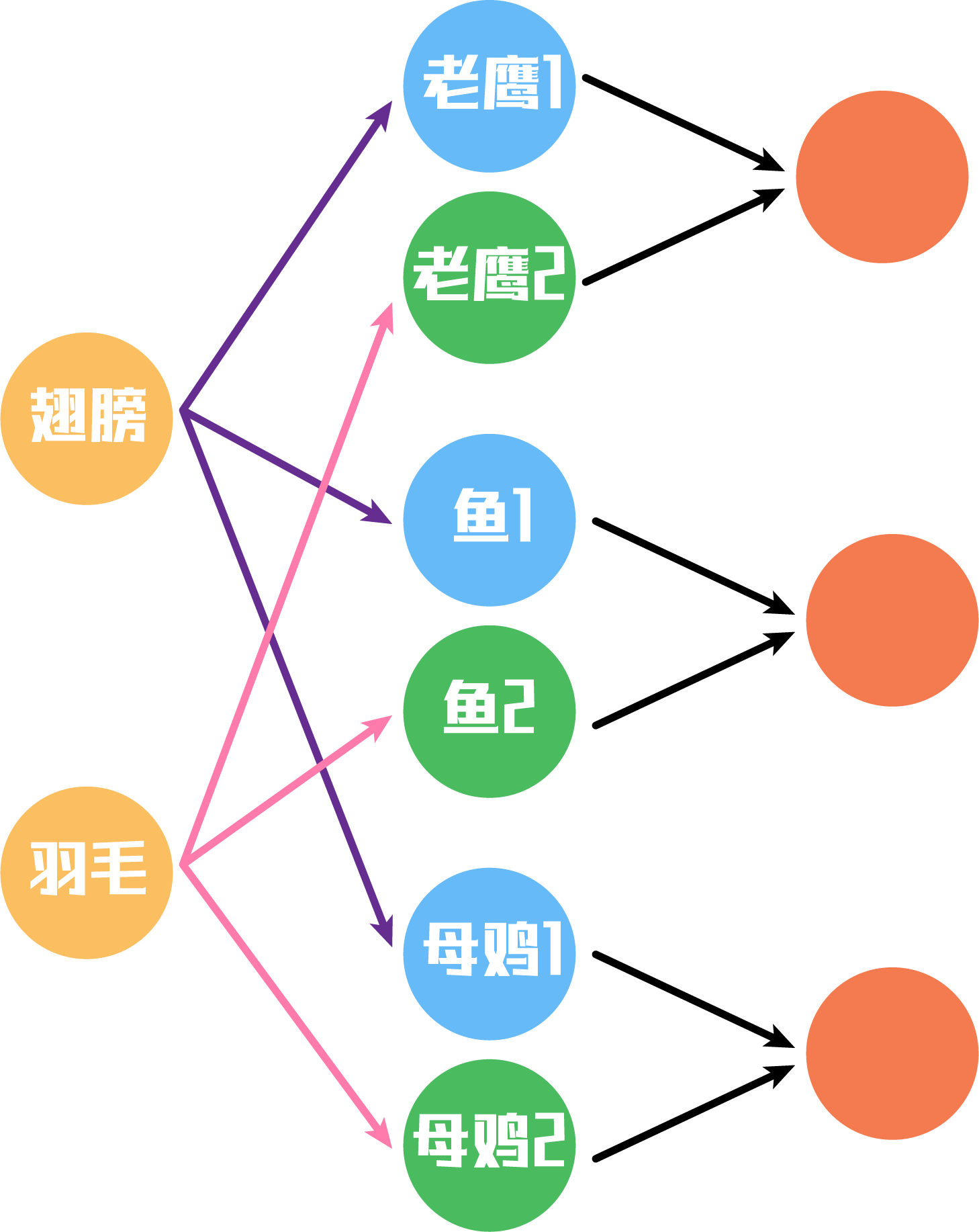
现在我们有了高层特征,我们对高层特征分别进行加权求和(通过 c 11 , c 12 c_{11},c_{12} c11,c12),就可以得到更有用的特征信息。这里与传统的神经网络不相同的是,其保留了所有的特征信息。我们知道羽毛这一特征对鱼贡献很小很小,那么在胶囊网络中我们依然选择保留,但是其权重就会非常的低。而在卷积神经网络中,这些权重低的部分就会被池化层给过滤掉。
换一种角度去理解:在传统的神经网络中每个神经结点处我们要得到的是一个值,这个值是加权求和的结果,如 0.2 ∗ 3 + 0.4 ∗ 2 + 0.4 ∗ 6 = 3.8 0.2*3+0.4*2+0.4*6=3.8 0.2∗3+0.4∗2+0.4∗6=3.8。但是胶囊网络不一样了,他在神经结点处想要得到的是一个向量,如 ( 0.2 ∗ 3 , 0.4 ∗ 2 , 0.4 ∗ 6 ) = ( 0.6 , 0.8 , 2.4 ) (0.2*3, 0.4*2, 0.4*6)=(0.6,0.8,2.4) (0.2∗3,0.4∗2,0.4∗6)=(0.6,0.8,2.4)。然后再让这个向量与 c i j c_{ij} cij加权求和。通过向量能保留更多的特征信息,所做出的预测理论上也应该更加准确。
有人可能会有疑问,这里的 c i j c_{ij} cij是从哪里来的。事实上, c i j c_{ij} cij满足下面这一个式子:
c i j = s o f t m a x ( b i j ) = e x p ( b i j ) ∑ i , j = 1 n e x p ( b i j ) c_{ij}=softmax(b_{ij})=\frac{exp(b_{ij})}{\sum_{i,j=1}^{n}{exp(b_{ij})}} cij=softmax(bij)=∑i,j=1nexp(bij)exp(bij)
这里的 b i j b_{ij} bij可以暂时看成一个输入的数,后面会介绍它的作用。通过softmax分类函数可以得到的 c i j c_{ij} cij,其实是maxpooling最大池化的一个增强版。我们之前说道过,由于最大池化会导致部分信息损失,所以最大池化会破坏原有的空间信息,需要进行改进。而上述方法得到的 c i j c_{ij} cij,能够起到将作用大与作用小的权重分化开的同时,还不至于使较小权重直接丢失。此外,softmax也起到了归一化的作用,使所有的输入概率和为1。我们称这一部分为**“动态路由算法”**
3、 s j → v j s_{j}\to v_j sj→vj部分
这一部分需要通过一个squashing函数:
s q u a s h ( s j ) = ∣ ∣ s j ∣ ∣ 2 1 + ∣ ∣ s j ∣ ∣ 2 ⋅ s j ∣ ∣ s j ∣ ∣ squash(s_j) = \frac{||s_j||^2}{1+||s_j||^2}·\frac{s_j}{||s_j||} squash(sj)=1+∣∣sj∣∣2∣∣sj∣∣2⋅∣∣sj∣∣sj
这个函数在胶囊网络里面的地位比较类似于激活函数在传统神经网络里的作用。
首先是 ∣ ∣ s j ∣ ∣ 2 1 + ∣ ∣ s j ∣ ∣ 2 \frac{||s_j||^2}{1+||s_j||^2} 1+∣∣sj∣∣2∣∣sj∣∣2这一部分,这一部分是控制向量的长度。如果之前的向量长度 ∣ ∣ s j ∣ ∣ ||s_j|| ∣∣sj∣∣比较大,那么这一部分就会更趋近于1,如果向量长度 ∣ ∣ s j ∣ ∣ ||s_j|| ∣∣sj∣∣比较小,那么这一部分会更趋近于0。我们可以看一下函数:
y = x 2 1 + x 2 y=\frac{x^2}{1+x^2} y=1+x2x2
的图像:
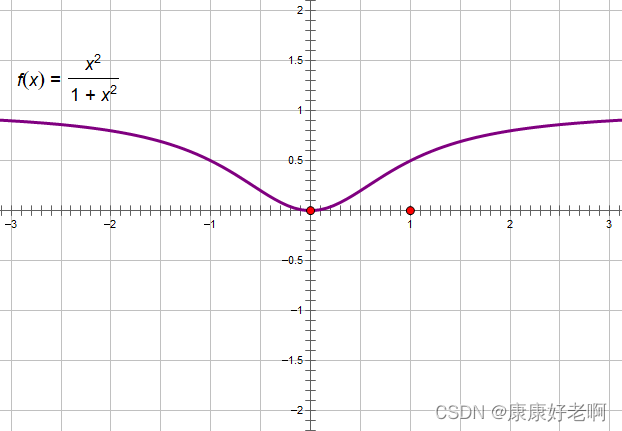
这样就会很好理解了。
其次是 s j ∣ ∣ s j ∣ ∣ \frac{s_j}{||s_j||} ∣∣sj∣∣sj这一部分。这一部分其实就是对向量 s j s_j sj进行归一化,主要目的是对特征向量进行压缩。
4、 b i j b_{ij} bij更新部分
胶囊网络也需要利用参数更新完成参数的训练。下面主要介绍下胶囊网络是如何进行参数更新的。
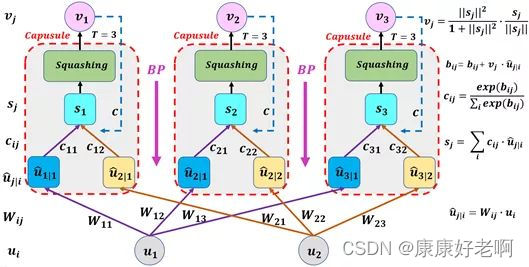
再把这张图拉出来方便对照查看。
前文我们在动态路由的部分提到了 b i j b_{ij} bij,下面我们来理解一下其作用。
相比于传统神经网络直接利用梯度下降更新权重,胶囊网络本质上在过程中多增加了softmax这一步,也就是将 b i j b_{ij} bij作为权重更新的中间变量,通过对 b i j b_{ij} bij的更新以完成对 c i j c_{ij} cij的更新。 b i j b_{ij} bij更新如下:
b i j = b i j + v j ⋅ u ^ j ∣ i b_{ij}=b_{ij}+v_j·\hat{u}_{j|i} bij=bij+vj⋅u^j∣i
其中 v j ⋅ u ^ j ∣ i v_j·\hat{u}_{j|i} vj⋅u^j∣i是 v j 和 u ^ j ∣ i v_j和\hat{u}_{j|i} vj和u^j∣i的点积。这里其实我比较好奇,为什么要用这两个向量的点积进行更新。这个问题其实可以拆分成两个问题:
(1)为什么这两个向量点积得到结果就是相似性?
在深度学习领域,进行点积的一个和常见的作用就是计算两个向量的相似性。
从数学推导的层面来说,由于: u ⋅ v = ∣ ∣ u ∣ ∣ ⋅ ∣ ∣ v ∣ ∣ c o s θ u·v=||u||·||v||cos\theta u⋅v=∣∣u∣∣⋅∣∣v∣∣cosθ,所以如果两者夹角越大,那么他们差异肯定也会越来越大,得到的结果就是点积越小。但是这里其实是有前提条件的,即在 ∣ ∣ u ∣ ∣ 、 ∣ ∣ v ∣ ∣ ||u||、||v|| ∣∣u∣∣、∣∣v∣∣都为定值的前提下。我们举个栗子:
比如现在我有向量 [ 2 , 3 ] [2,3] [2,3]和 [ 2 , 4 ] [2,4] [2,4],两者点积之和为16;现在我有向量 [ 2 , 4 ] [2,4] [2,4]和 [ 2 , 4 ] [2,4] [2,4],两者点积之和为20;现在我有向量 [ 2 , 3 ] [2,3] [2,3]和 [ 2 , 5 ] [2,5] [2,5],两者点积之和为19。
不难发现,上面的例子其实并不满足向量越相似、点积的值越大。这是因为 ∣ ∣ u ∣ ∣ 、 ∣ ∣ v ∣ ∣ ||u||、||v|| ∣∣u∣∣、∣∣v∣∣并没有统一。而如果我们对向量进行归一化(也就是将每个向量的模转化成1),这个其实是满足的。但是如果没有进行归一化,就不能绝对的说比较的就是相似性,但是在某些特殊条件下,比如对相似性要求不严格只要求达到定性效果,或者这些向量的模都接近于1或者某个特定值,点积是可以近似看成相似度的。
我目前对胶囊网络这部分的理解是,这里的相似度只要达到一个定性层面即可,不需要严格的定性(这会不会是改进点?)
(2)为什么权重更新需要跟相似度牵扯上关系?
这一点需要理清胶囊网络的算法思路。
最初, b b b的值是0,所有 c c c值的大小都相同, v v v与哪个 u u u相似度更高,那么对应的 b b b更新权重后的值就越大, b b b的值越大,那么 c c c的值越大,这就意味着该向量相关性更高,也就意味着该特征的贡献更大。利用相似度其实就是为了更加有效的提取特征。
继续举个例子。假设有一个留长发的男生叫李华(纯虚构),我们在男生宿舍一眼认出来李华大概率是因为他的长头发,而他的手臂相对来说就不具有很高的辨识度。再假设李华特别喜欢穿裙子,还是类似婚纱的那种(抽象能有更深的印象),那么我们认出他还有可能是因为他的裙子,而他的脸声音可能相对来说也不那么具有辨识度(这是一个假定)。那么通过胶囊网络训练,穿裙子和长头发这两个特征就会逐渐赋予更高的权重,从别的特征中脱颖而出。比如你在卫生间看到了一个长头发、穿裙子的人,我敢保证第一反应你绝对不会以为他是李华,而是你走错了卫生间。第二反应肯定是这原来是李华。为什么?长头发+裙子+(你旁边还有好几个男的应该说明没走错)。这两个特征某种意义上构成了一个聚类,从别的特征中脱颖而出。
你认出李华是靠“长头发+裙子”,那么这个特征肯定与“长头发”特征更相似,而与“手臂”特征就不那么相似,因此,“长头发”特征给予的权重会更高,而“手臂”特征给予的权重会挺低。
嘿嘿。
5、 W i j W_{ij} Wij部分
这一部分与传统的神经网络相似,也是需要进行反向传播梯度下降。
具体内容——整体胶囊网络思路
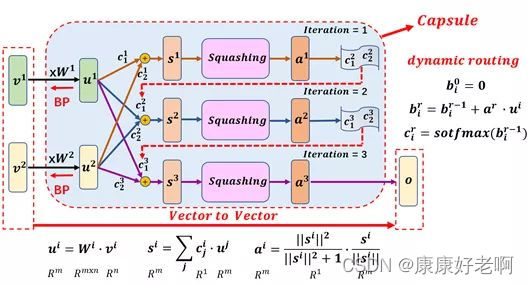
上面一部分内容我们对一个“胶囊”的流程进行了介绍,但一般来说,一个胶囊会拥有多个“子胶囊”。
如上图,第一行经过Squashing输出后,我们得到了 v 1 v_1 v1,之后就会进行权重更新得到新的 c c c,这些值将传入下一行网络中,再传入下一行网络中,最终将得到的 v 3 v_3 v3作为这一整个胶囊的最终的输出结果。
这个整体的胶囊相当于传统的神经网络中的那个含有激活函数的神经元。
算法表述

经过上面的表述,相信这部分算法应该不难看懂了