1.FPN在MASK R-CNN中
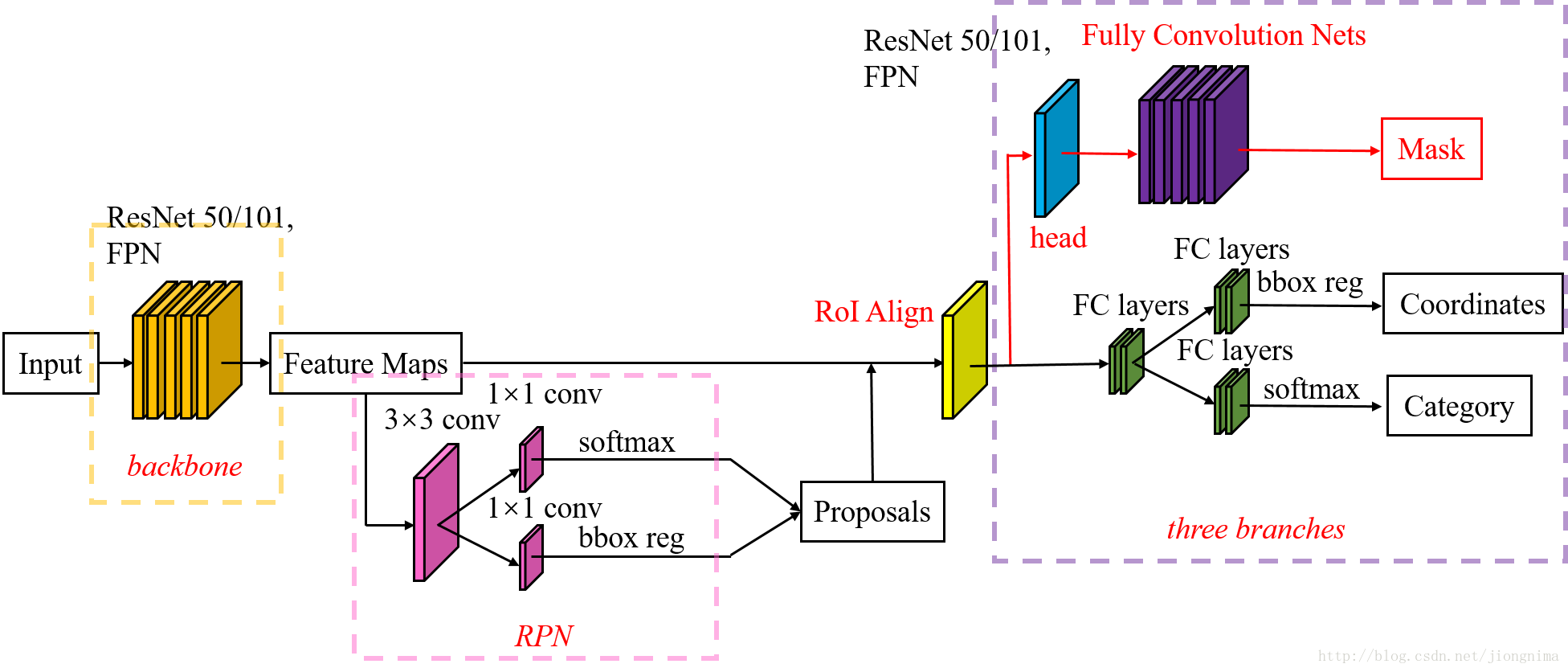
从上图可以看到,FPN在MASK R-CNN中主要是应用于Featue Maps的输出。但是FPN却不是MASK R-CNN所独有的。FPN是一个独立的网络。即有无FPN都可以输出Feature Maps,但是采用FPN之后,大幅度提升了小物体检测的性能。
2.图像金字塔(image pyramid)
图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。

两种类型的金字塔:
- 高斯金字塔:用于下采样,主要的图像金字塔;
- 拉普拉斯金字塔:用于重建图像,也就是预测残差(我的理解是,因为小图像放大,必须插入一些像素值,那这些像素值是什么才合适呢,那就得进行根据周围像素进行预测),对图像进行最大程度的还原。比如一幅小图像重建为一幅大图像。多用于图像融合。
图像金字塔有两个高频出现的名词:上采样和下采样。
- 上采样:就是图片放大
- 下采样:就是图片缩小
下采样(图像压缩,会丢失图像信息)步骤:
- 对图像进行高斯内核卷积
- 将所有偶数行和列去除。
3.FPN
原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法(SSD)采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
底层特征:图像本身的客观统计特性的的表示。(图像纹理特征,颜色特征,形状特征,空间位置特征)
高层语义特征:人们对图像本身内容的定义与理解。
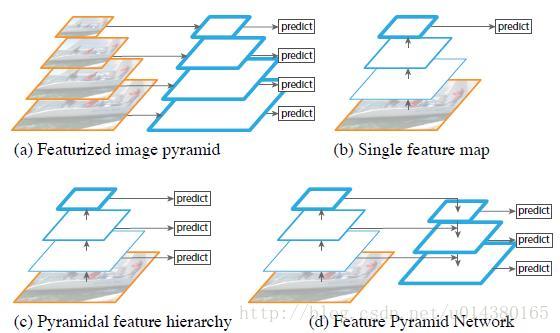
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
(b)像SPP net,Fast RCNN,Faster RCNN是采用对图像进行CNN处理,featureMap尺度不断变小,在最后一个featureMap上进行predict。
(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。这种方式有其合理性,一幅图像中可能具有多个不同大小的目标,区分不同的目标可能需要不同的特征,对于简单的目标我们仅仅需要浅层的特征就可以检测到它,对于复杂的目标我们就需要利用复杂的特征来检测它。整个过程就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d)本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。除了在多个featureMap上进行predict之位,每一个进行预测的featureMap还加入了高层的信息(高层的信息可以帮助我们准确检测目标);
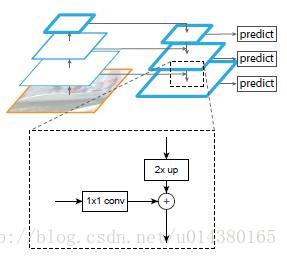
FPN的主网络采用ResNet
1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature maps的个数,并不改变feature map的尺寸大小。
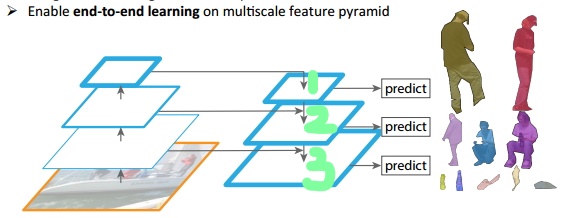
如上图所示,我们可以看到我们的图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来;这样我们就需要这样的一个特征金字塔来完成这件事。图中我们在第1层(请看绿色标注)输出较大目标的实例分割结果,在第2层输出次大目标的实例检测结果,在第3层输出较小目标的实例分割结果。检测也是一样,我们会在第1层输出简单的目标,第2层输出较复杂的目标,第3层输出复杂的目标。
自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
1*1 卷积核:降维,减少卷积核的个数,也就是减少了feature map的个数
自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)(像素之间会出现重叠)。
4.FPN用于MASK R-CNN
原来的RPN网络是以主网络的某个卷积层输出的feature map作为输入,简单讲就是只用这一个尺度的feature map。但是现在要将FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于P2,P3,P4,P5,P6这些层,定义anchor的大小为32^2,64^2,128^2,256^2,512^2,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor。
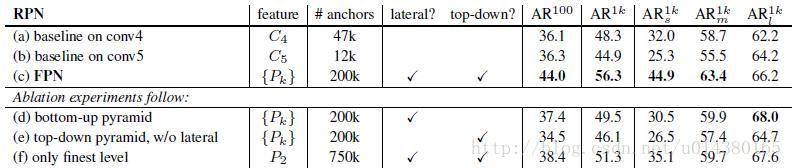
(d)的结果并不好的原因在于在自底向上的不同层之间的semantic gaps比较大。
(e)这样效果也不好的原因在于目标的location特征在经过多次降采样和上采样过程后变得更加不准确。
