Parallel Processors: From Client to Cloud
Task-level parallelism or process-level parallelism: using multiple processors by running multiple independent programs simultaneously
Parallel Processor: A single program running on multiple processors simultaneously
By adding hardware, instruction fetching and instruction decoding are implemented in parallel. Multiple instructions are fetched at one time, and then distributed to multiple parallel instruction decoders for decoding, and then handed over to different functional units for processing. . In this way, more than one instruction can be completed in one clock cycle. This kind of CPU design is called multi-issue (Mulitple Issue) and superscalar (Superscalar).
Multi-issue refers to issuing multiple instructions to different decoders or subsequent processing pipelines at the same time.
There are many parallel pipelines in a superscalar CPU, not just one .
vectors and scalars
Important properties of vector instructions:
- A single vector instruction specifies a large amount of work - equivalent to executing a complete loop. Because of this, instruction fetch and decoding bandwidth are greatly reduced
- By using vector instructions, the compiler or programmer confirms that each result in the vector is independent, so the hardware no longer has to check for data hazards within the vector instructions.
- When data-level parallelism exists in a program, it is easier to write efficient applications using a combination of vector architecture and compiler than using MMD multiprocessors.
- The hardware only needs to check for data hazards between vector operands between two vector instructions without checking every data element in the vector. Reducing the number of checks can save energy consumption and time.
- Vector instructions that access memory have a defined access pattern. If the data element locations in a vector are all contiguous, the vector can be quickly retrieved by interleaving data blocks from a set of memories. Therefore, the main memory latency overhead appears only once for the entire vector, rather than once for each word in the vector.
- Because the entire loop is replaced by a vector instruction with known behavior, the control hazards usually caused by loops no longer exist
- Compared with scalar architectures, the savings in instruction bandwidth and hazard checks, as well as the efficient use of memory bandwidth, make vector architectures more advantageous in terms of power and energy consumption.
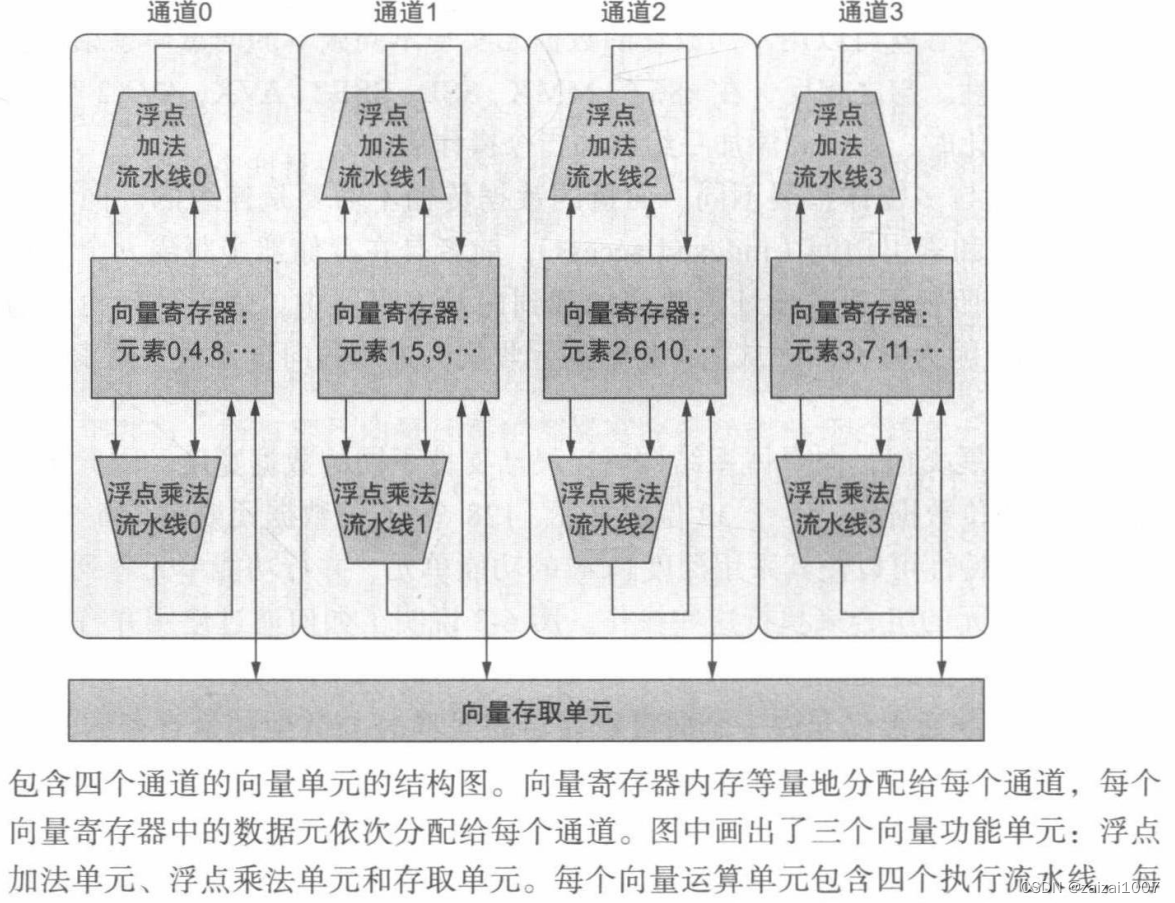
Vector arithmetic instructions typically allow elements N of one vector register to interact with elements N of other vector registers. This greatly simplifies the construction of highly parallel vector units - which can be constructed as multiple parallel vector channels
Vector channel: one or more vector functional units and a portion of the vector register file

Hardware multi-threading
Thread: includes program counter, register status and stack. A thread is a lightweight process. Threads usually share an address space, while processes do not.
Process: includes one or more threads, complete address space and operating system state. Therefore, process switching usually requires calling the operating system, but thread switching does not.
Hardware multithreading: Improves processor utilization by switching to another thread when one thread stalls
Hardware multithreading allows multiple threads to share functional units of a single processor in an overlapping manner to efficiently utilize hardware resources
Fine-grained multithreading: A version of hardware multithreading that switches threads after each instruction
Thread switching is performed after each instruction is executed, resulting in cross-execution of multiple threads. This interleaved execution is usually done in a round-robin fashion, skipping any threads stalled on that clock cycle. One advantage of fine-grained multithreading is that it can hide the throughput loss caused by short-term and long-term pauses. The main disadvantage is that it will slow down the execution speed of a single thread, because already ready threads will be delayed by executing instructions from other threads.
Coarse-grained threading: Another version of hardware multithreading that switches threads only after significant events (such as last-level cache misses)
There is virtually no slowing down of a single thread's execution because instructions from other threads are only emitted when a thread encounters an expensive stall. But there is a serious disadvantage: the ability to reduce throughput loss is limited, especially for short pauses
Simultaneous multithreading: A version of multithreading that reduces the cost of multithreading by leveraging multi-issue, dynamically scheduled microarchitecture resources
Because SMT relies on existing dynamic mechanisms, it does not switch resources every clock cycle. Instead, SMT always executes instructions from multiple threads, leaving resource allocation to the hardware. These resources are instruction slots and renaming. register
Simultaneous multithreading: A version of multithreading that reduces the cost of multithreading by leveraging multi-issue, dynamically scheduled microarchitecture resources


Shared Memory Multiprocessor (SMP): Provides a unified physical address space for all processors
Processors communicate through shared variables in memory, and all processors are able to access arbitrary memory locations through load and store instructions
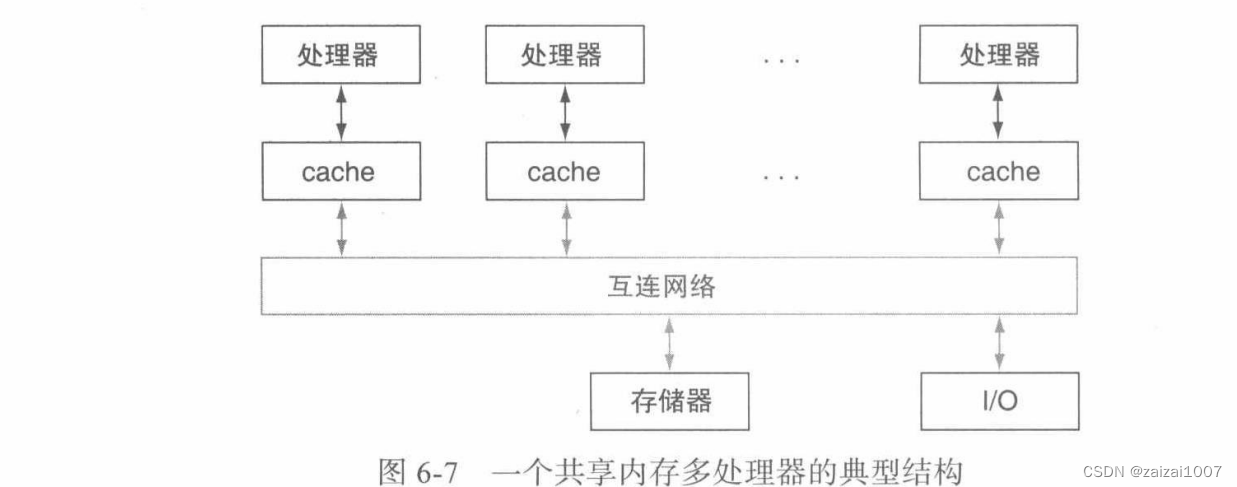
Unified memory access: A multiprocessor in which memory access latency is approximately the same regardless of which processor accesses the memory.
Non-uniform memory access: A single address space multi-processor with different memory access latencies, depending on which processor accesses which storage
Synchronization: The process of coordinating the behavior of two or more processes, which may be running on different processors
Introduction to GPU--Graphics Processing Unit
Key features that distinguish GPU from CPU:

GPUs rely on hardware multithreading in a single multithreaded SIMD processor to hide memory latency
The GPU contains a collection of multi-threaded SIMD (Single Instruction, Multiple Threads) processors. That is to say, the GPU is a MIMD (Multiple Instruction, Multiple Threads) composed of multi-threaded SIMD processors.

Recommended good articles: Principles of Computer Composition - Tag - Pang Ren - Blog Park (cnblogs.com)