Table of contents
0. Learning objectives of this section
Fourth, master the conversion operator
(2) Filter operator - filter()
(3) Flat map operator - flatMap()
1. Flat mapping operator function
2. Case of flat mapping operator
(4) Key reduction operator - reduceByKey()
1. Button reduction operator function
2. Key reduction operator case
(6) Sorting operator - sortBy()
(7) Key sorting operator - sortByKey()
2. Case of key sorting operator
1. Inner connection operator - join()
2. Left outer join operator - leftOuterJoin()
3. Right outer join operator - rightOuterJoin()
4. Full outer join operator - fullOuterJoin()
(9) Intersection operator - intersection()
1. Intersection operator function
2. Case of intersection operator
(10) Deduplication operator - distinct()
1. Deduplication operator function
2. Deduplication operator case
(11) Combined grouping operator - cogroup()
1. Combination grouping operator function
2. Combined grouping operator case
(1) Reduction operator - reduce()
1. Reduction operator function
(3) Key count operator - countByKey()
1. Button counting operator function
2. Case of button counting operator
(4) Front intercept operator - take(n)
1. Front intercept operator function
2. Pre-interception operator case
(5) Traversal operator - foreach()
2. Cases of traversal operators
(6) File save operator - saveAsFile()
1. Save file operator function
2. Case of file storage operator
0. Learning objectives of this section
- Understand the process of RDD processing
- Master the use of conversion operators
- Master the use of action counters
1. RDD processing process
- Spark implements the API of RDD in Scala language, and program developers can operate and process RDD by calling the API. RDD undergoes a series of " conversion " operations, and each conversion will generate a different RDD for the next " conversion " operation, until the last RDD undergoes " action " operations before it will be actually calculated and processed, and output to external data In the source, if the intermediate data results need to be reused, cache processing can be performed to cache the data in memory.
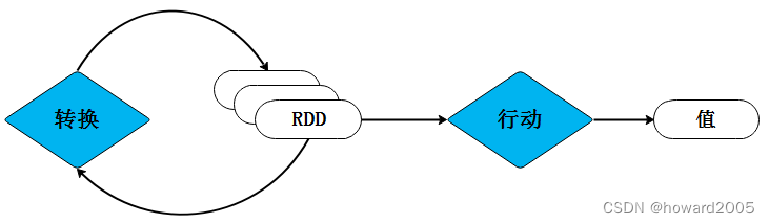
2. RDD operator
- After RDD is created, it is read-only and cannot be modified. Spark provides a wealth of methods for manipulating RDDs, which are called operators . A created RDD only supports two types of operators:
转换(Transformation)operator and行动(Action)operator.
(1) Conversion operator
- The "conversion" operation in the RDD processing process is mainly used to create a new RDD based on the existing RDD. After each calculation through the Transformation operator, a new RDD will be returned for use by the next transformation operator.
- API for common conversion operator operations
| conversion operator | Relevant instructions |
|---|---|
| filter(func) | Filter out the elements that satisfy the function func and return a new dataset |
| map(func) | Pass each element into the function func, and the returned result is a new dataset |
| flatMap(func) | Similar to map(), but each input element can be mapped to zero or more output results |
| groupByKey() | When applied to a dataset of (Key, Value) key-value pairs, returns a new dataset of the form (Key, Iterable<Value>) |
| reduceByKey(func) | When applied to a dataset of (Key, Value) key-value pairs, returns a new dataset of the form (Key, Value). Among them, each Value value is the result of passing each Key key to the function func for aggregation |
(2) Action operator
- The action operator is mainly to return the value after running the calculation on the data set to the driver program, thereby triggering the real calculation.
- APIs for common action operator operations
| action counter | Relevant instructions |
|---|---|
| count() | Returns the number of elements in the dataset |
| first() | returns the first element of the array |
| take(n) | Returns the first n elements in the array set as an array |
| reduce(func) | Aggregate elements in a dataset by a function func (takes two arguments and returns a value) |
| collect() | Returns all elements in the dataset as an array |
| foreach(func) | Pass each element in the dataset to the function func to run |
3. Preparation
(1) Prepare documents
1. Prepare local system files
- create in
/homedirectorywords.txt
2. Upload the file to HDFS
- Will be
words.txtuploaded to/parkthe directory of the HDFS system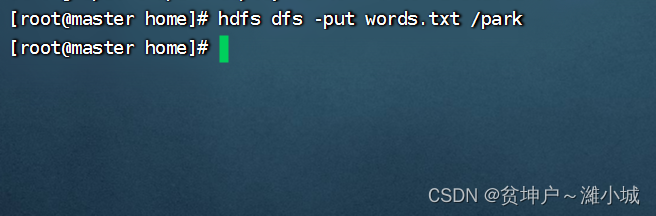
- Description:
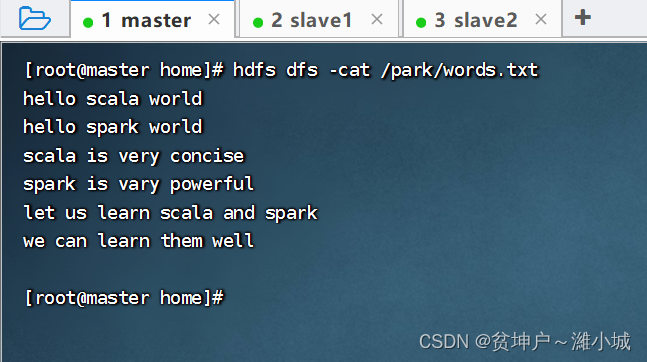
/parkIt is the directory we created in the previous lecture - view file content
(2) Start Spark Shell
1. Start the HDFS service
- Excuting an order:
start-dfs.sh
2. Start the Spark service
- Excuting an order:
start-all.sh
3. Start Spark Shell
- Execute the name command:
spark-shell --master spark://master:7077
hdfs://master:9000The Spark Shell started in cluster mode cannot access local files, but can only access HDFS files. The effect is the same with or without the prefix.
Fourth, master the conversion operator
- The conversion operator is responsible for calculating the data in the RDD and converting it into a new RDD. All conversion operators in Spark are
惰性unique, because they do not immediately calculate the result, but only a记住specific operation process on a certain RDD, and will not be executed together with the action operator until it encounters the action operator.
(1) Mapping operator - map()
1. Mapping operator function
- map() is a conversion operator that takes a function as an argument , applies this function to
每个the elements of the RDD, and finally uses the result of the function as the value of the corresponding element in the resulting RDD.
2. Mapping operator case
- Preliminary work: Create an RDD -
rdd1 - Excuting an order:
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6))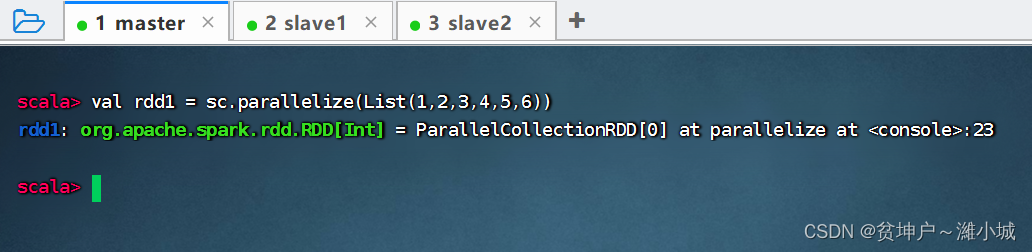
Task 1. Double each element of rdd1 to get rdd2
-
Applies
rdd1the map() operator to the pair,rdd1squares each element in and returns ardd2new RDD named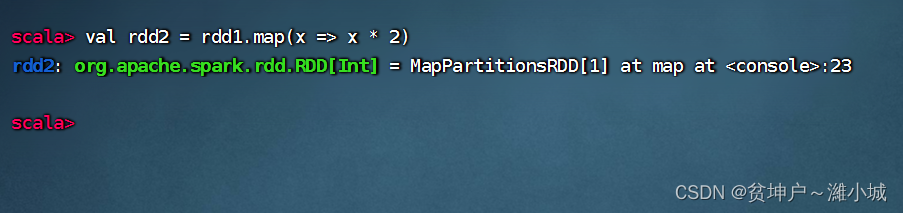
-
In the above code, a function is passed to the operator map()
x = > x * 2. Among them,xis the parameter name of the function, and other characters can also be used, for examplea => a * 2. Spark will pass each element in the RDD as an argument to this function. -
In fact, using magic placeholders
_can be written more concisely
-
rdd1rdd2There is actually no data in the sum, because the sum is a conversion operator,parallelize()and calling the conversion operator will not immediately calculate the result.map()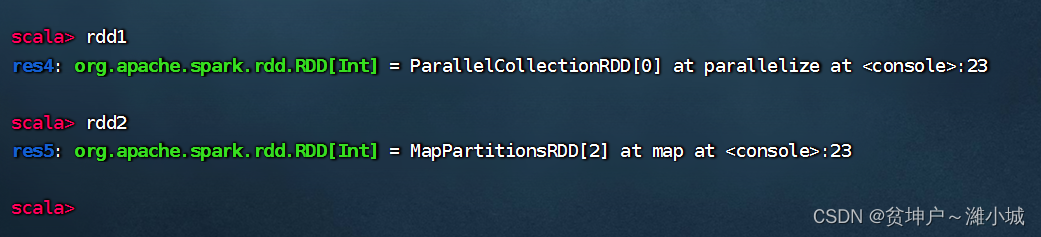
-
If you need to view the calculation results, you can use the action counter
collect(). (collect means collection or collection) -
Execution
rdd2.collectperforms the computation and数组collects the result into the current asDriver. Because the elements of RDD are distributed, data may be distributed on different nodes.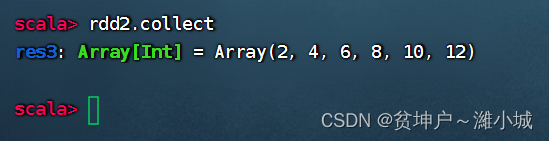
-
take action: take action. The heart is not as good as the action.
-
map()The operation process of the above operator is shown in the figure below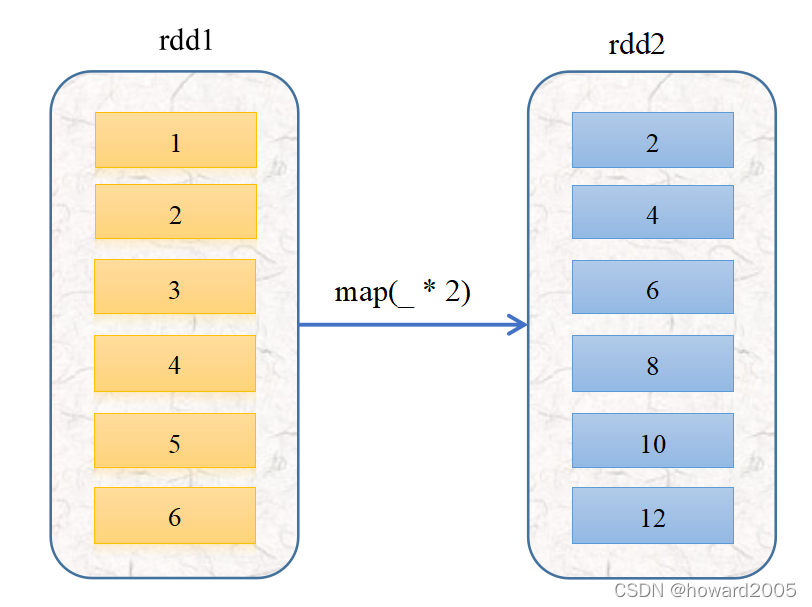
-
A function is essentially a special kind of mapping. The above mapping is written as a function: f ( x ) = 2 x , x ∈ R f(x)=2x,x\in \Bbb Rf(x)=2x,x∈R
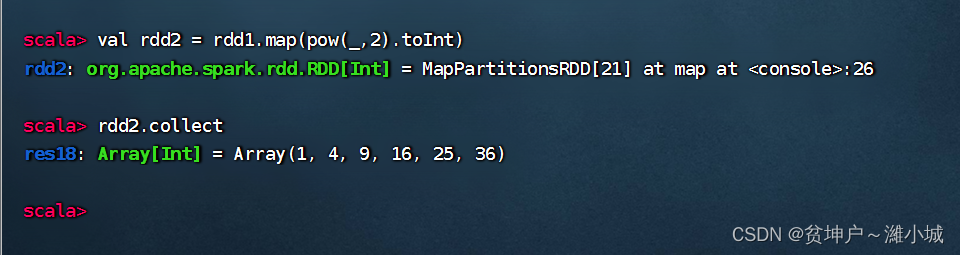
Task 2. Square each element of rdd1 to get rdd2
-
Method 1: Use ordinary functions as parameters to the map() operator
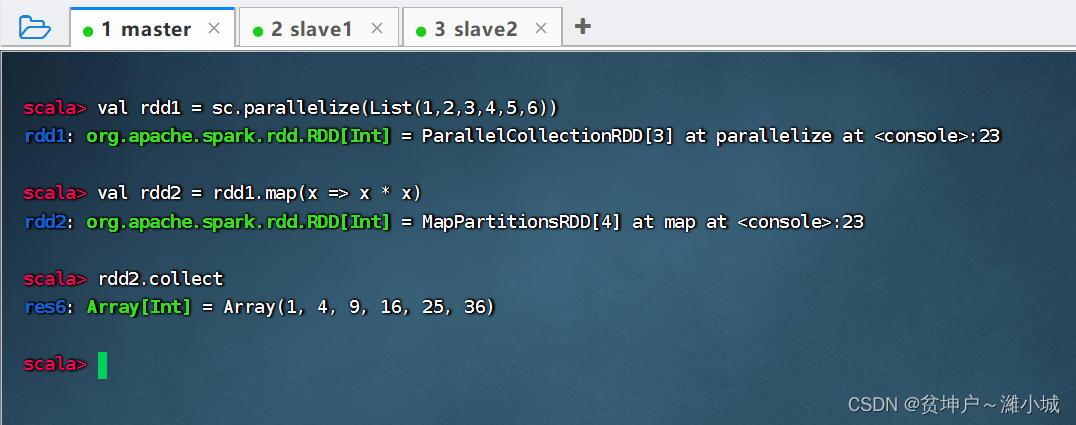
-
Method 2: Use the underscore expression as a parameter to the map() operator
-
Just now doubling is used
map(_ * 2), it is natural to think that the square should bemap(_ * _)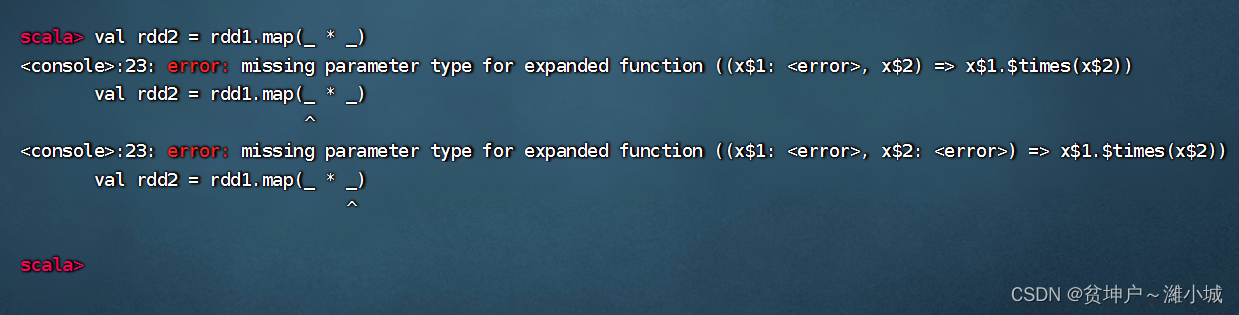
-
Reporting an error,
(_ * _)aftereta-expansionturning into an ordinary function, it is not what we expectedx => x * x, but(x$1, x$2) => (x$1 * x$2)a binary function instead of a one-variable function. The system is immediately forced, and I don’t know how to take two parameters to perform multiplication. -
Can't you use underscore parameters? Of course you can, but you must ensure that the underscore appears only
1once in the underscore expression. Bring in the math packagescala.math._and you're done.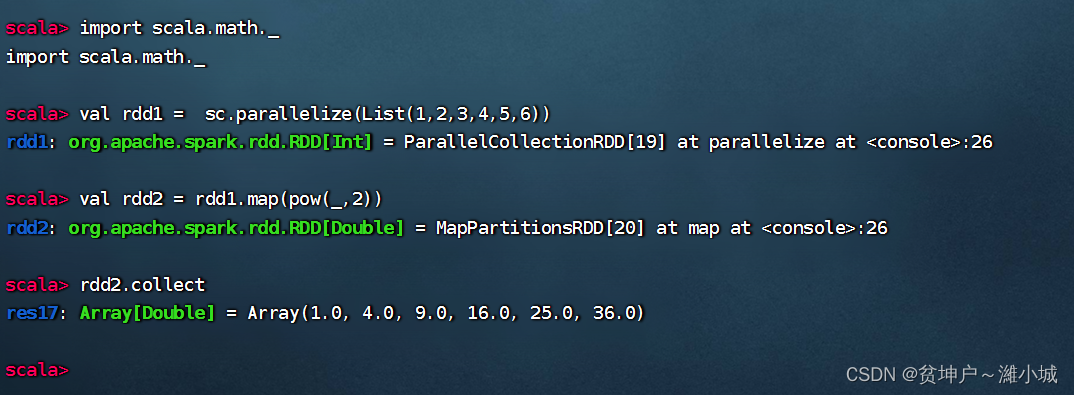
-
But there is a fly in the ointment, the elements of rdd2 become double-precision real numbers, which have to be converted into integers
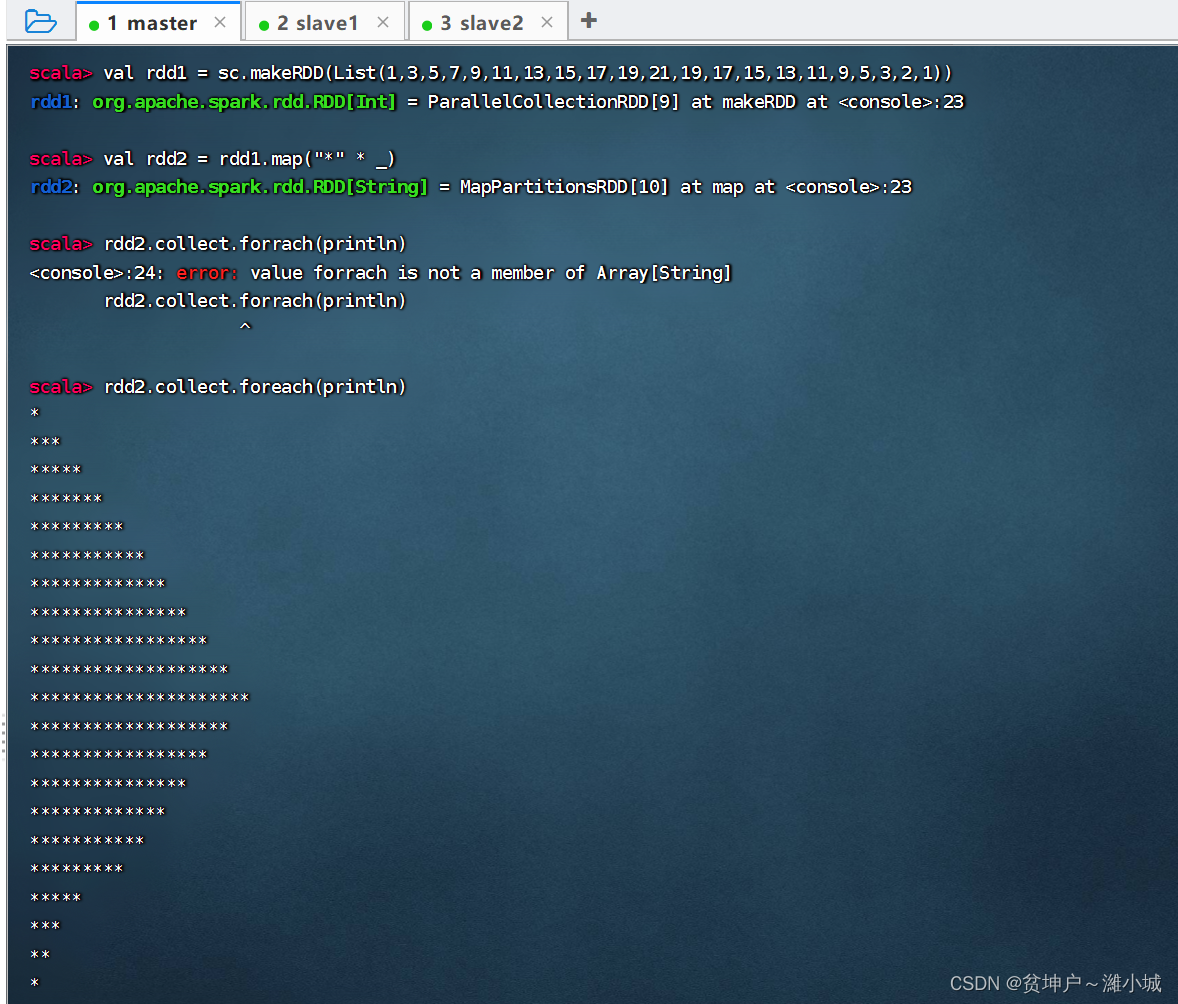
Task 3. Use the mapping operator to print a rhombus
(1) Implementation in Spark Shell
- A combination of a rhombus, an upright isosceles triangle and an inverted isosceles triangle

- half rhombus
- Add a leading space to display a diamond
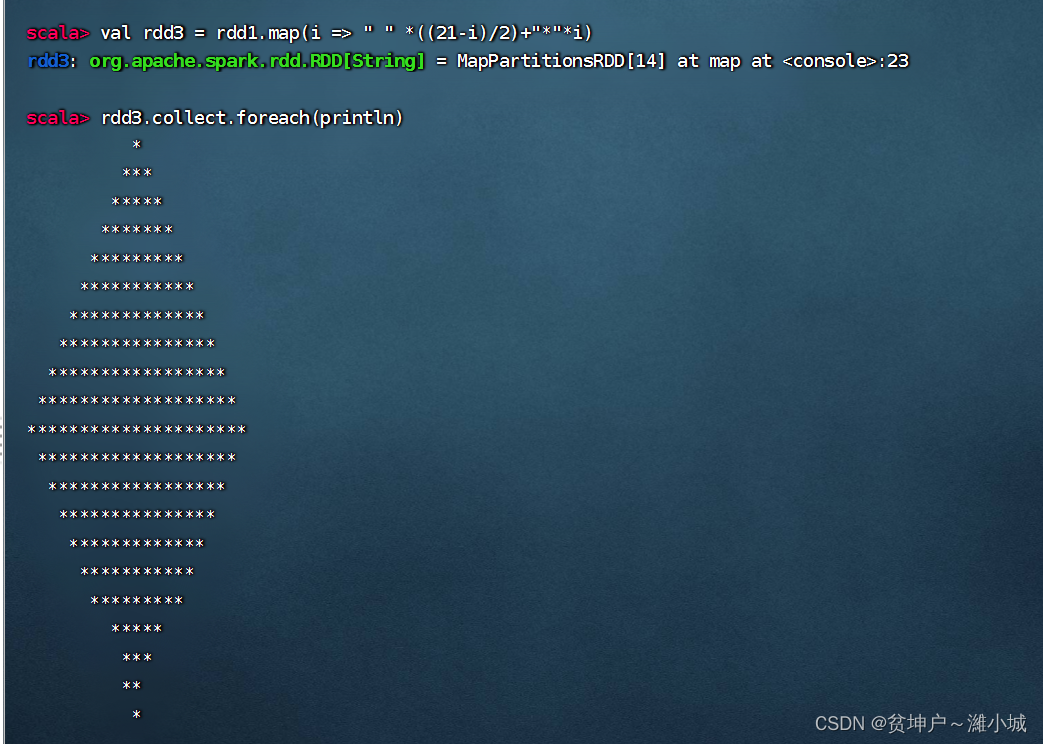
- Reference code (with versatility in mind)
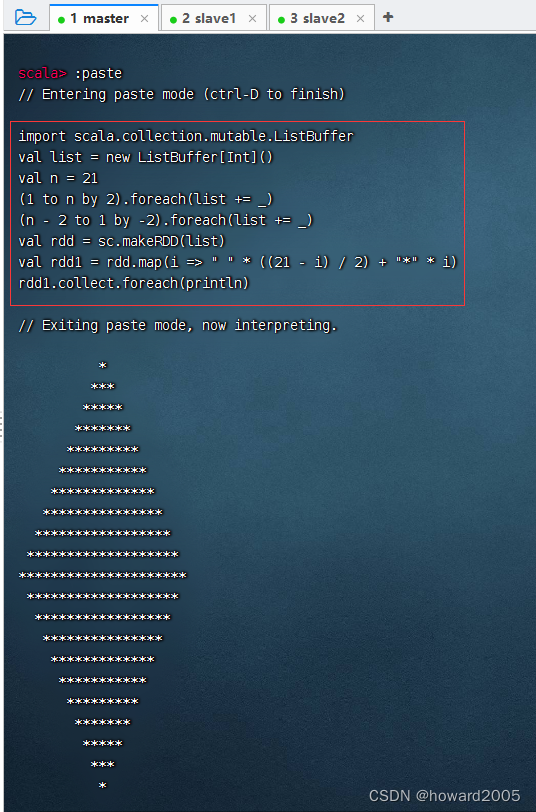
import scala.collection.mutable.ListBuffer
val list = new ListBuffer[Int]()
val n = 21
(1 to n by 2).foreach(list += _)
(n - 2 to 1 by -2).foreach(list += _)
val rdd = sc.makeRDD(list)
val rdd1 = rdd.map(i => " " * ((n - i) / 2) + "*" * i)
rdd1.collect.foreach(println)
(2) Create a project implementation in IDEA
- Refer to lecture notes 2.4 to create a Maven project-
SparkRDDDemo
- Click the [Finish] button
- change
javadirectory toscaladirectory 
pom.xmlAdd relevant dependencies and set the source program directory in the file
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.huawei.rdd</groupId>
<artifactId>SparkRDDDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.15</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
</build>
</project>
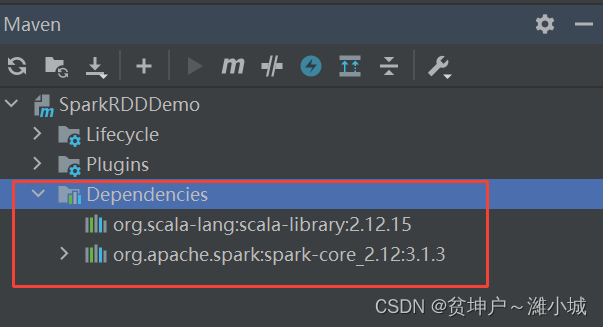
- Refresh project dependencies
- Add log properties file
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/rdd.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- Create
hdfs-site.xmla file that allows clients to access cluster data nodes
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<description>only config in clients</description>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
</configuration>
- create
net.huawei.rdd.day01package
net.huawei.rdd.day01CreateExample01a singleton object in the package
package net.huawei.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
import scala.io.StdIn
object Example01 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 输入一个奇数
print("输入一个奇数:")
val n = StdIn.readInt()
// 创建一个可变列表
val list = new ListBuffer[Int]()
// 给列表赋值
(1 to n by 2).foreach(list += _)
(n - 2 to 1 by -2).foreach(list += _)
// 基于列表创建rdd
val rdd = sc.makeRDD(list)
// 对rdd进行映射操作
val rdd1 = rdd.map(i => " " * ((n - i) / 2) + "*" * i)
// 输出rdd1结果
rdd1.collect.foreach(println)
}
}
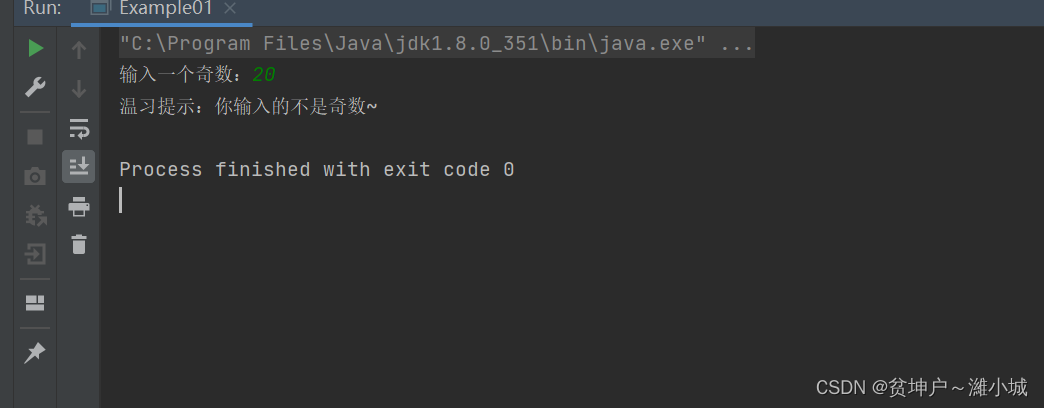
- Run the program to see the result
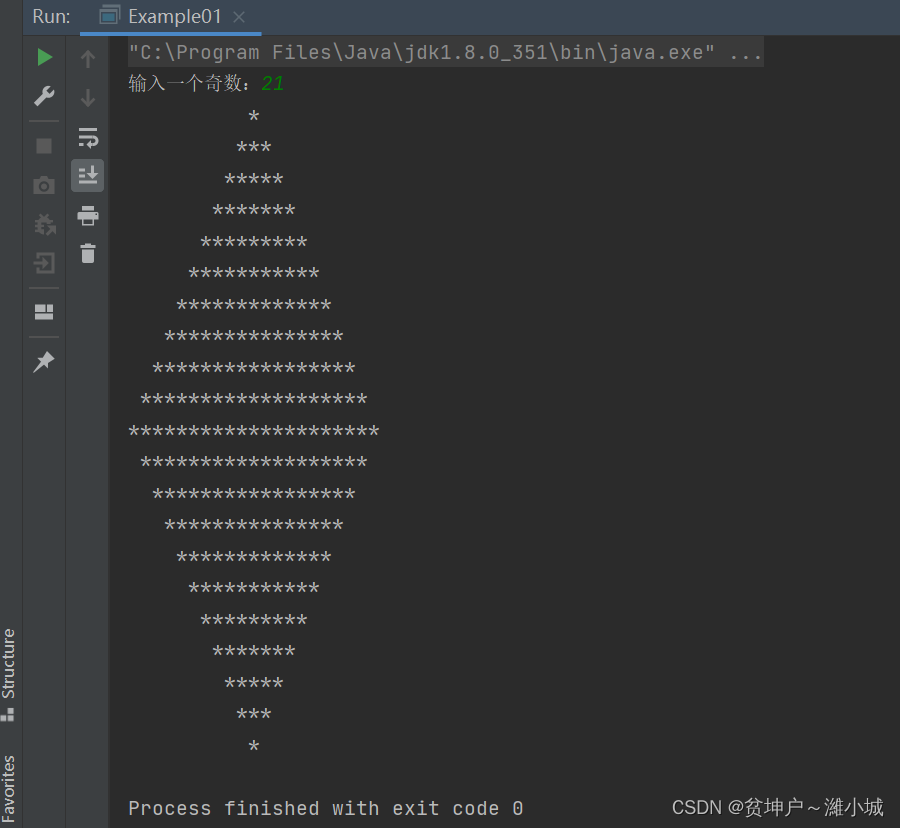
- What happens if the user enters an even number?
- Modify the code to avoid this problem
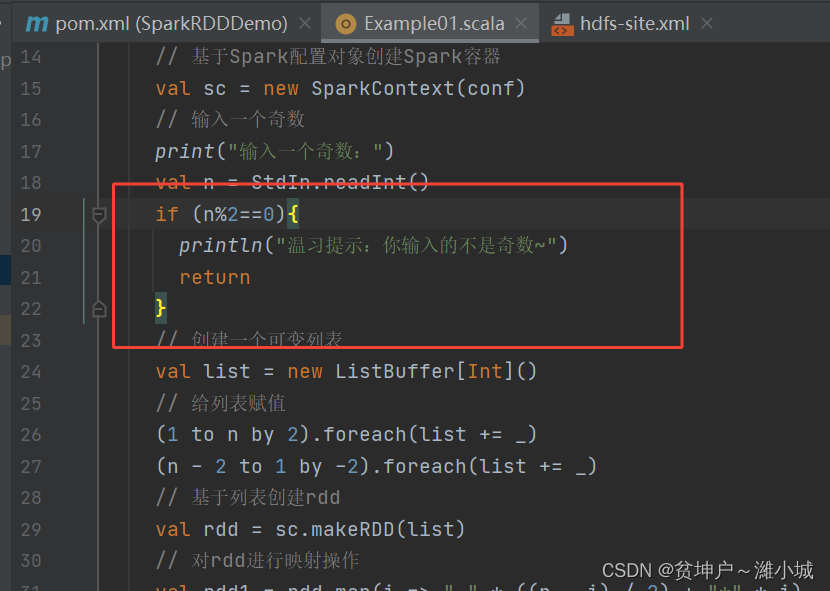
- Run the program, enter an even number
(2) Filter operator - filter()
1. Filter operator function
filter(func): Use a functionfuncto filter each element of the source RDD and return a new RDD. Generally speaking, the number of elements in the new RDD will be less than that of the original RDD.
2. Filter operator case
Task 1. Filter out the even numbers in the list
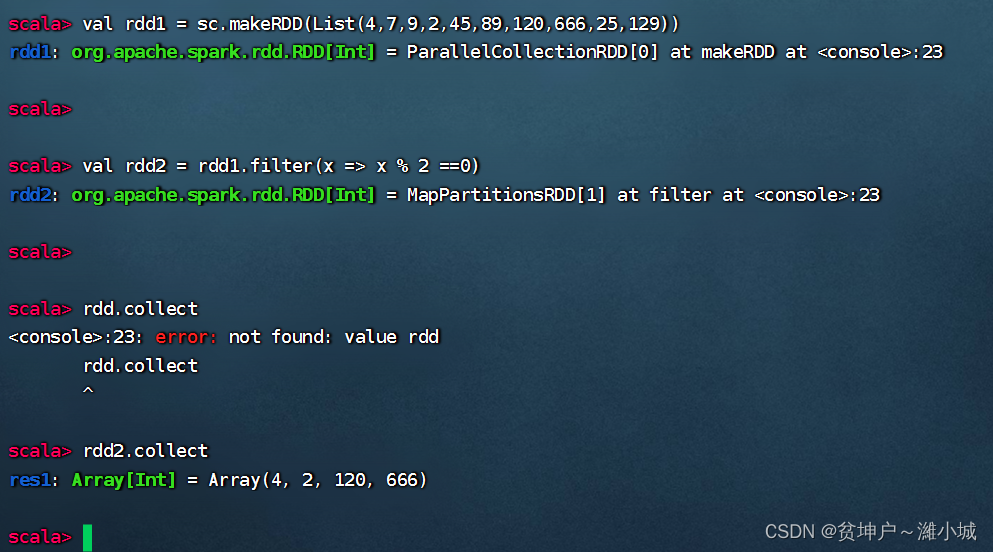
-
Create an RDD based on the list, and then use the filter operator to get a new RDD composed of even numbers
-
Method 1. Pass the anonymous function to the filter operator
-
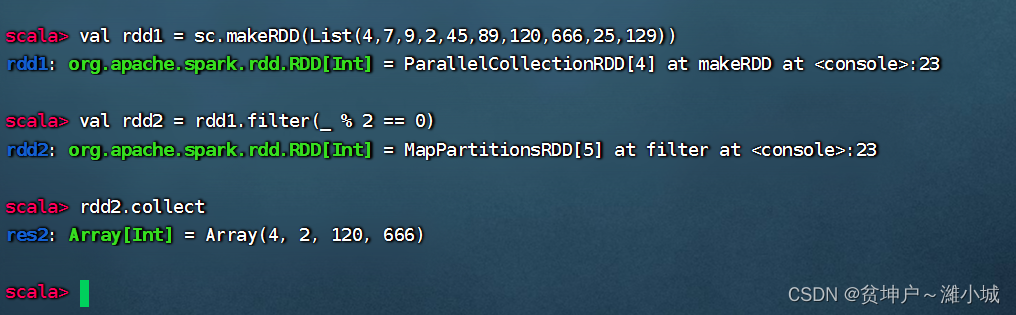
Method 2: Use a magic placeholder to rewrite the anonymous function passed in to the filter operator
-
Take
rdd1each elementxin the calculationx % 2 == 0, if the result of the relational expression is true, then the element will be thrown into the new RDD -rdd2, otherwise it will be filtered out.
Task 2. Filter out sparkthe lines contained in the file
-
View source file
/park/words.txtcontent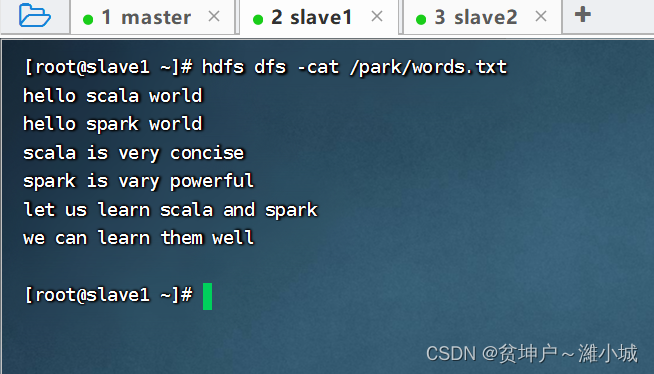
-
Execute the command:
val lines= sc.textFile("/park/words.txt"), read the file/park/words.txtto generate RDD -lines
-
Execute the command:
val sparkLines = lines.filter(_.contains("spark")), filtersparkthe rows included to generate RDD -sparkLines
-
Execute the command:
sparkLines.collect, to viewsparkLinesthe content, you can use the traversal operator to output the content by line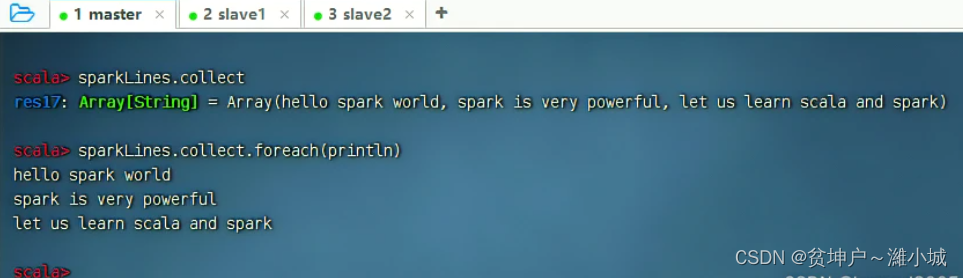
classroom exercises
Task 1. Use the filter operator to output all leap years between [2000, 2500]
-
The traditional approach is to use the nested selection structure of the loop structure to achieve
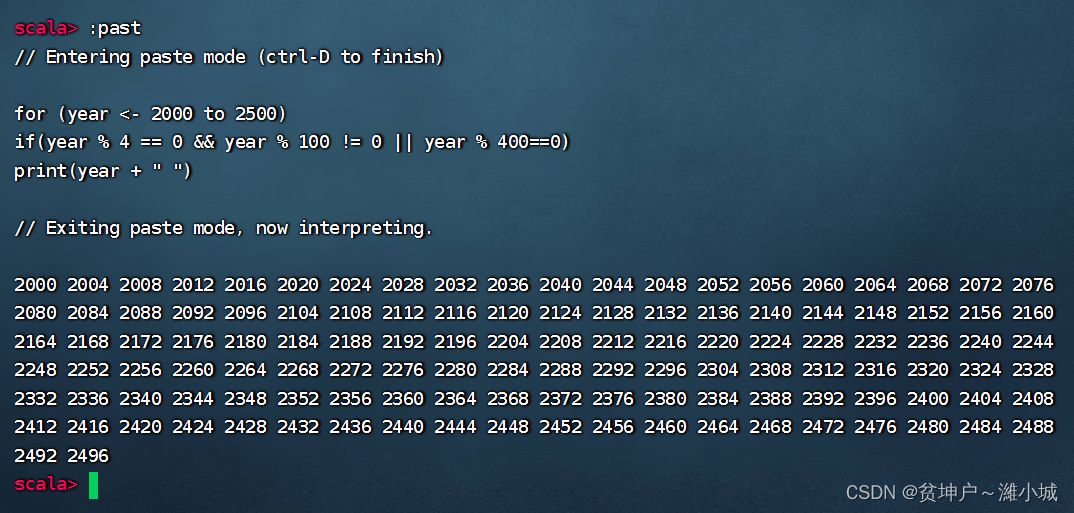
-
It is required to output 10 numbers per line
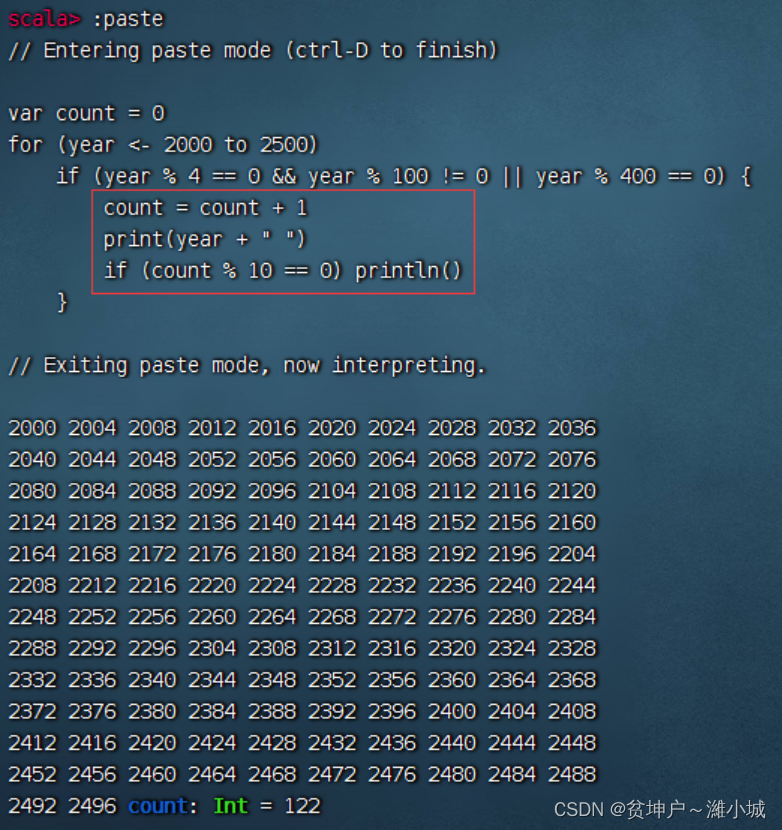
-
Use filter operator to realize
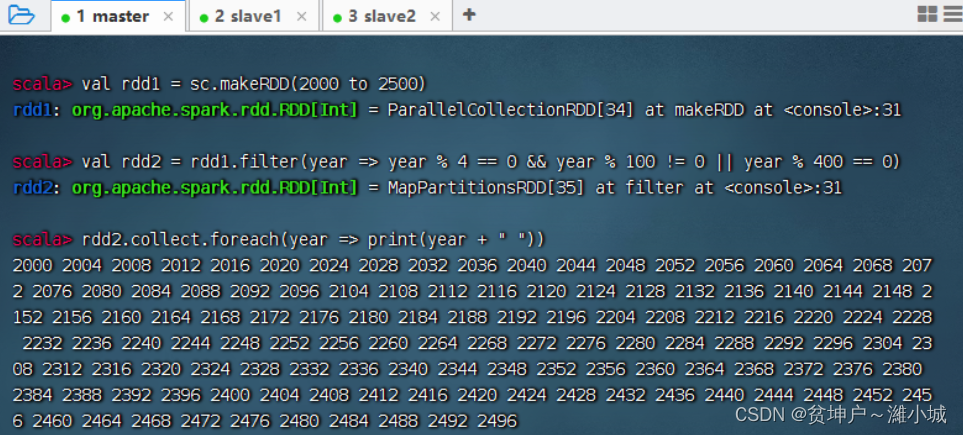
-
It is required to output 10 numbers per line
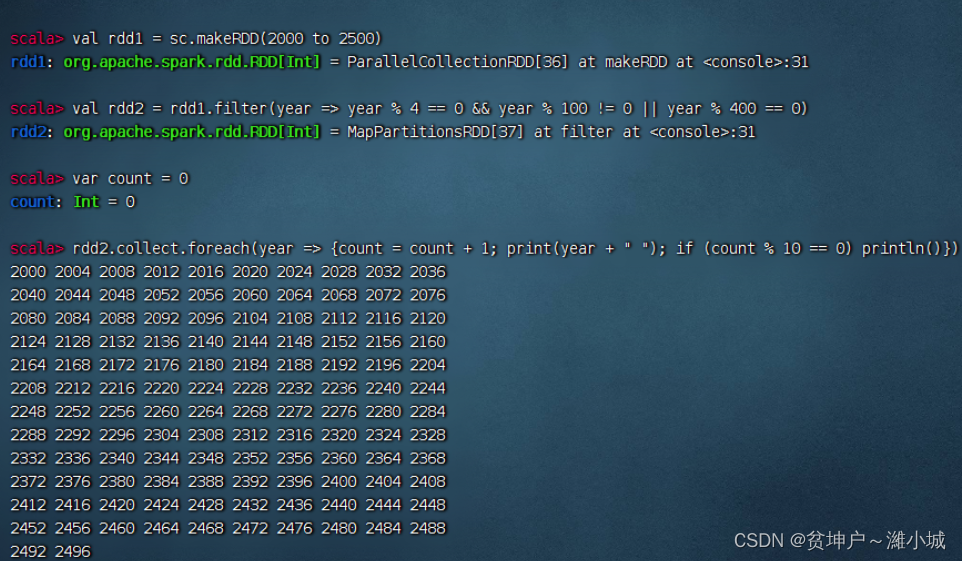
Task 2. Use the filter operator to output all prime numbers between [10, 100]
- Filter operator:
filter(n => !(n % 2 == 0 || n % 3 == 0 || n % 5 == 0 || n % 7 == 0))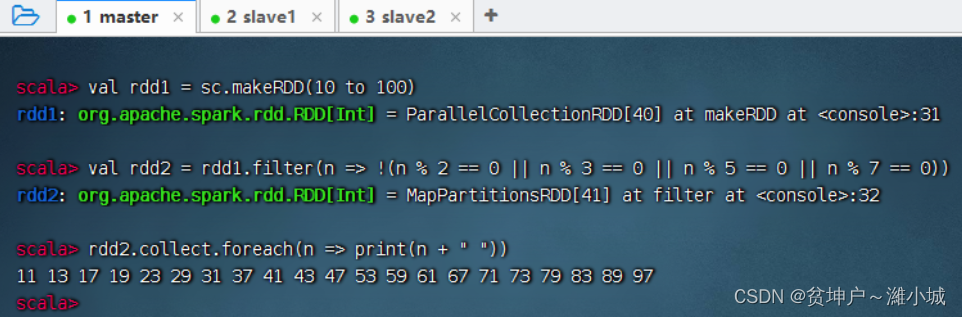
(3) Flat map operator - flatMap()
1. Flat mapping operator function
- The flatMap() operator is similar to the map() operator, but each RDD element passed to the function func will return 0 to more elements, and finally all the returned elements will be merged into one RDD.
2. Case of flat mapping operator
Task 1. Count the number of words in the file
-
Read the file, generate RDD -
rdd1, view its content and the number of elements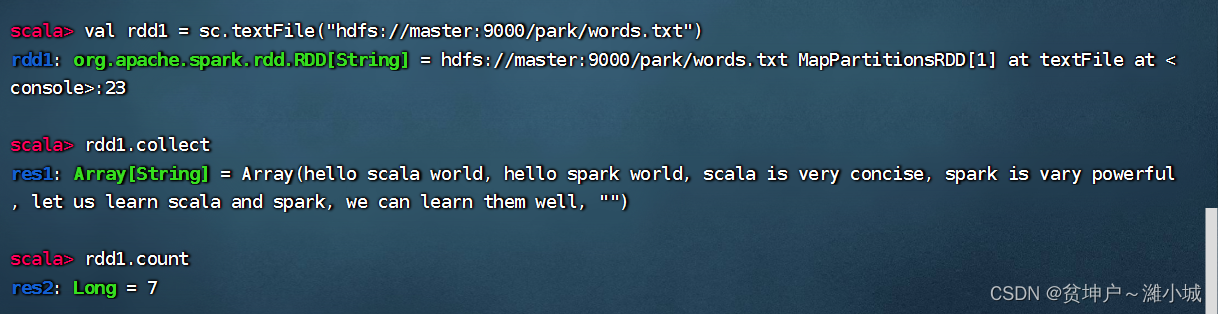
-
For
rdd1split by whitespace, do the map, generate new RDD -rdd2
-
For
rdd1splitting by spaces, do flat mapping, and generate new RDD -rdd3, there is a dimensionality reduction effect
-
Statistical results: There are 25 words in the file
Description: The operation process diagram of the flat mapping operator
- The elements of rdd1
5become20the elements of rdd2 after flat mapping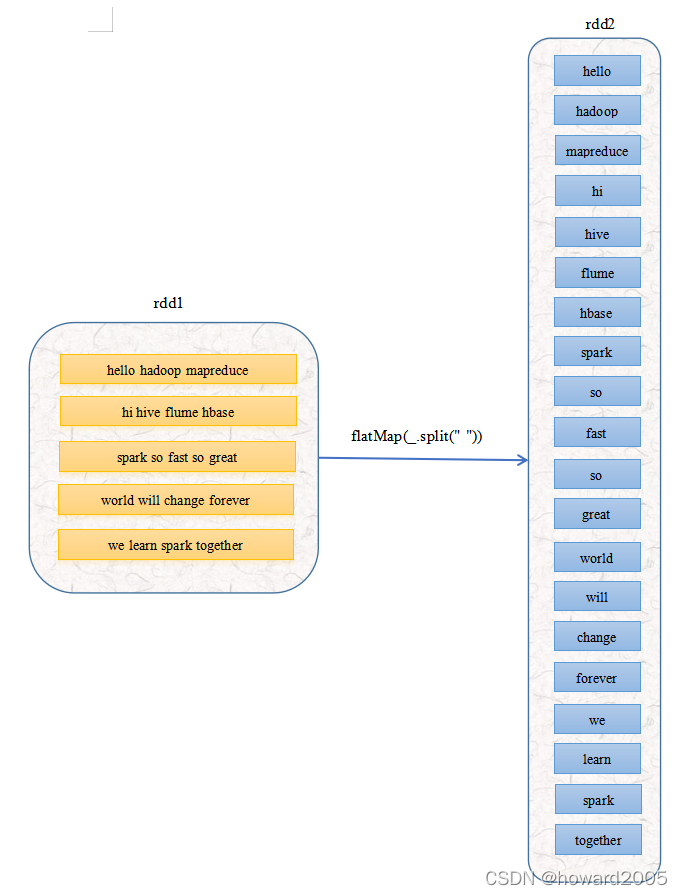
Task 2. Count the number of irregular two-dimensional list elements
[ 7 8 1 5 10 4 9 7 2 8 1 4 21 4 7 − 4 ] \left[ \right]7107218424198751−44
Method 1, using Scala to achieve
flattenfunctions using listsnet.huawei.rdd.day01CreateExample02a singleton object in the package
package net.hyw.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
object Example02 {
def main(args: Array[String]): Unit = {
// 创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
// 输出二维列表
println(mat)
// 将二维列表扁平化为一维列表
val arr = mat.flatten
// 输出一维列表
println(arr)
// 输出元素个数
println("元素个数:" + arr.size)
}
}
- Run the program to see the result

Method 2: Use Spark RDD to implement
- Using the flatMap operator
net.huawei.rdd.day01CreateExample03a singleton object in the package
package net.huawei.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
object Example03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
// 基于二维列表创建rdd1
val rdd1 = sc.makeRDD(mat)
// 输出rdd1
rdd1.collect.foreach(x => print(x + " "))
println()
// 进行扁平化映射
val rdd2 = rdd1.flatMap(x => x.toString.substring(5, x.toString.length - 1).split(", "))
// 输出rdd2
rdd2.collect.foreach(x => print(x + " "))
println()
// 输出元素个数
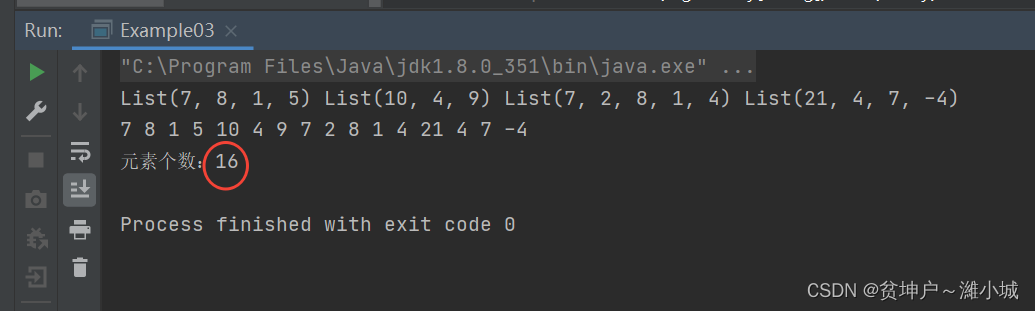
println("元素个数:" + rdd2.count)
}
}
- Run the program to see the result
- Flattening maps can simplify

(4) Key reduction operator - reduceByKey()
1. Button reduction operator function
- The reduceByKey() operator acts on an RDD whose elements are in the form of (key, value) (Scala tuples). Using this operator, elements with the same key can be gathered together, and finally all elements with the same key can be merged into one element. The key of the element remains unchanged, and the value can be aggregated into a list or summed and other operations. The element type of the finally returned RDD is consistent with the original type.
2. Key reduction operator case
Task 1. Calculate the student's total score in Spark Shell
- The grade table contains four fields (name, Chinese, mathematics, English), and only three records
| Name | language | math | English |
|---|---|---|---|
| Zhang Qinlin | 78 | 90 | 76 |
| Chen Yanwen | 95 | 88 | 98 |
| Lu Zhigang | 78 | 80 | 60 |
- Create a score list
scores, create it based on the score listrdd1,rdd1get it by reducing the keyrdd2, and then viewrdd2the content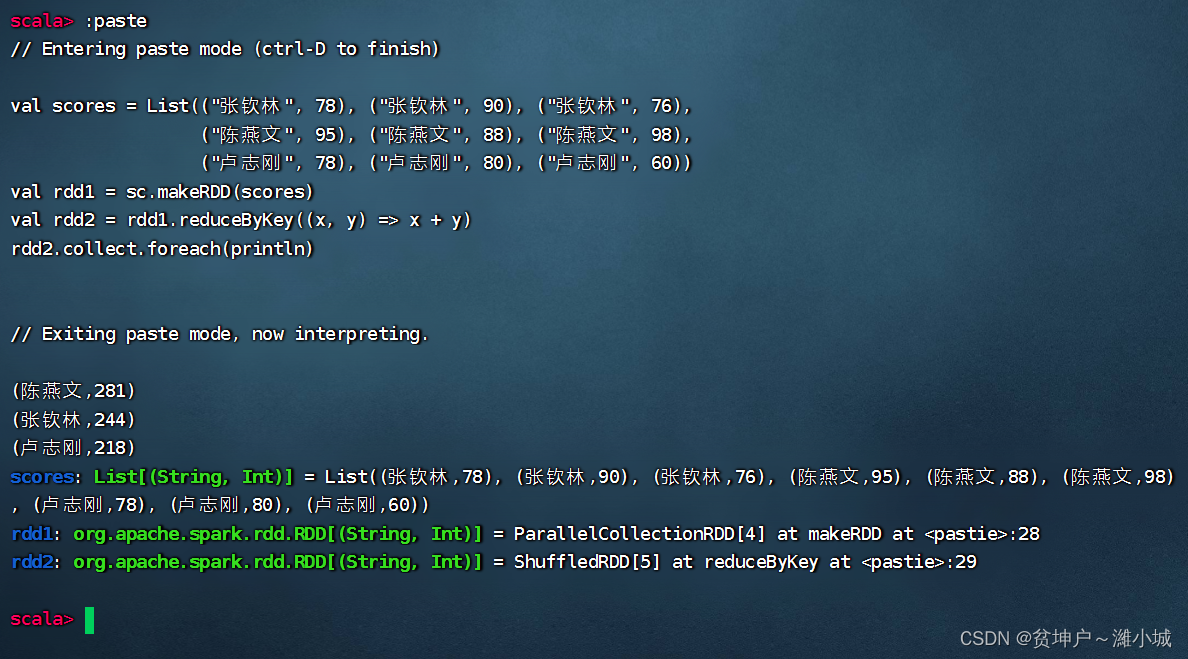
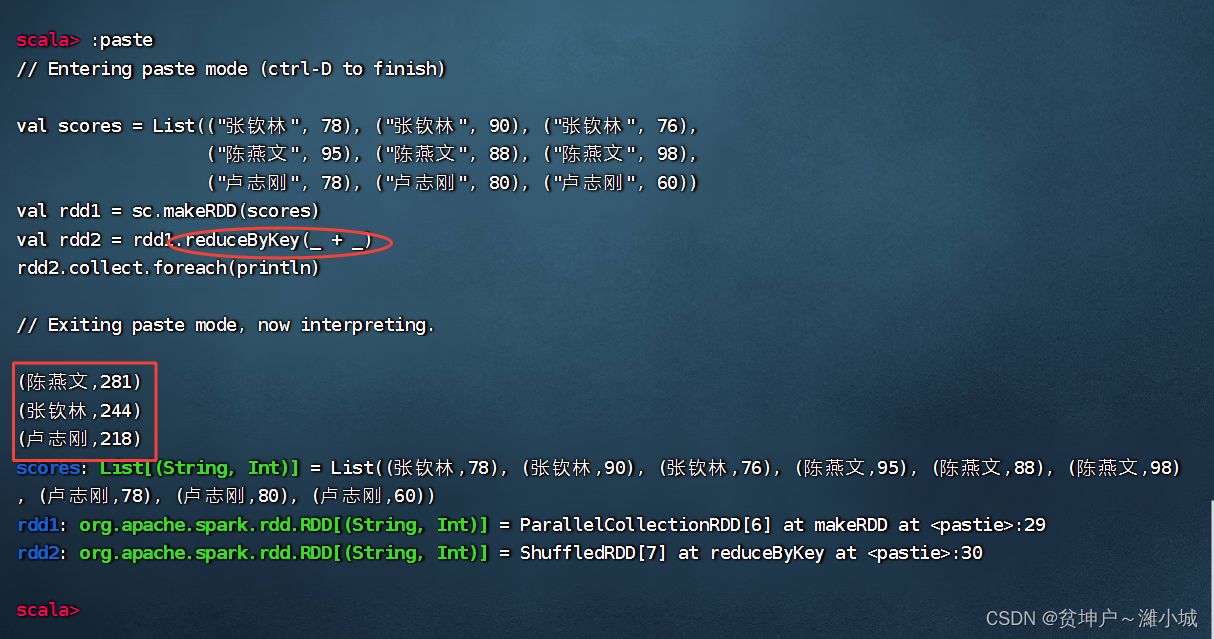
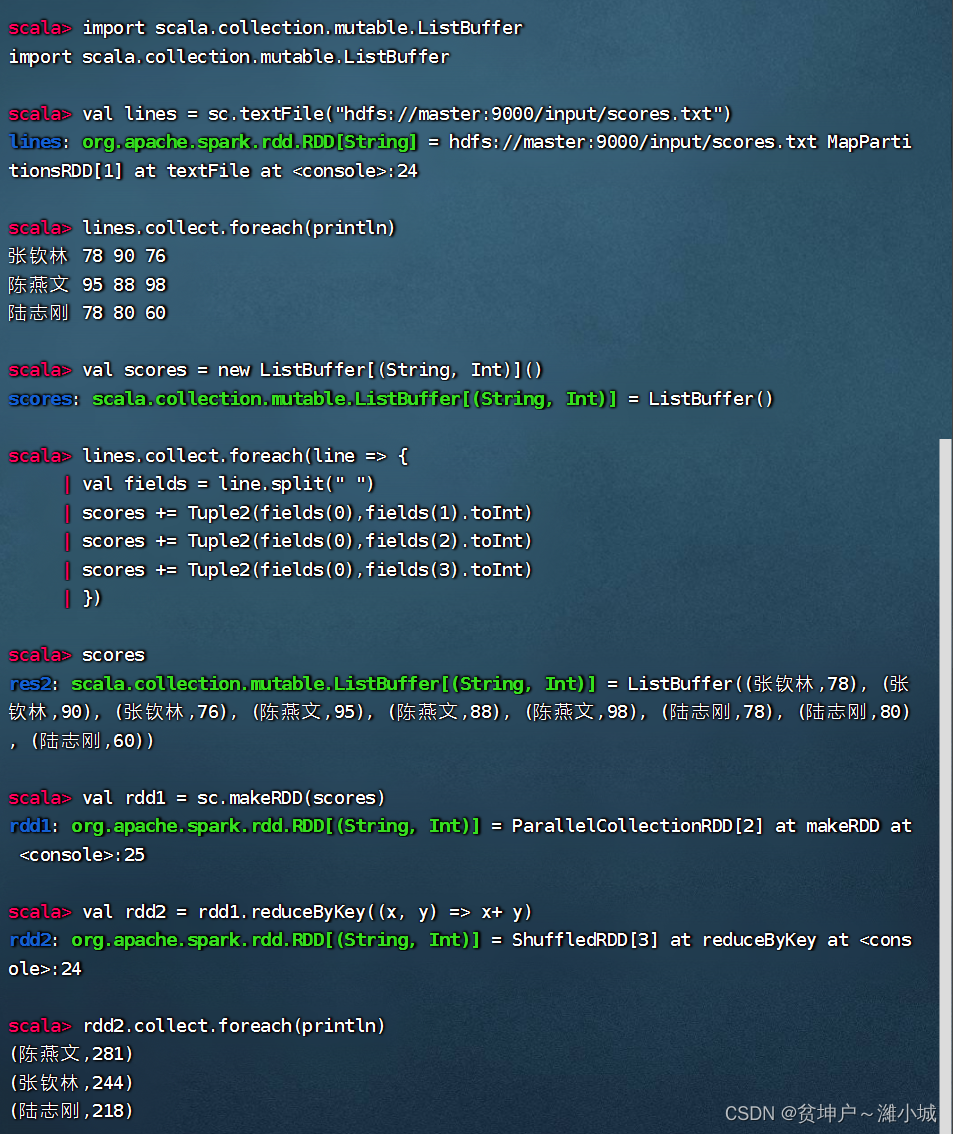
val scores = List(("张钦林", 78), ("张钦林", 90), ("张钦林", 76),
("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),
("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
rdd2.collect.foreach(println)
- Not only can tasks be completed in the Spark Shell, but also Scala programs can be written to generate jars and submitted to the Spark server for running. Interested students may wish to refer to " Spark Case: Two ways to calculate the total score of students "
Task 2. Calculate the student's total score in IDEA
- The grade table contains four fields (name, Chinese, mathematics, English), and only three records
| Name | language | math | English |
|---|---|---|---|
| Zhang Qinlin | 78 | 90 | 76 |
| Chen Yanwen | 95 | 88 | 98 |
| Lu Zhigang | 78 | 80 | 60 |
net.hyw.rdd.day02CreateCalculateScoreSuma singleton object in the package
package net.hyw.rdd.day02
import org.apache.spark.{SparkConf, SparkContext}
object CalculateScoreSum {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateScoreSum")
.setMaster("local[*]")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 创建成绩列表
val scores = List(
("张钦林", 78), ("张钦林", 90), ("张钦林", 76),
("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),
("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60)
)
// 基于成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
- Run the program to see the result
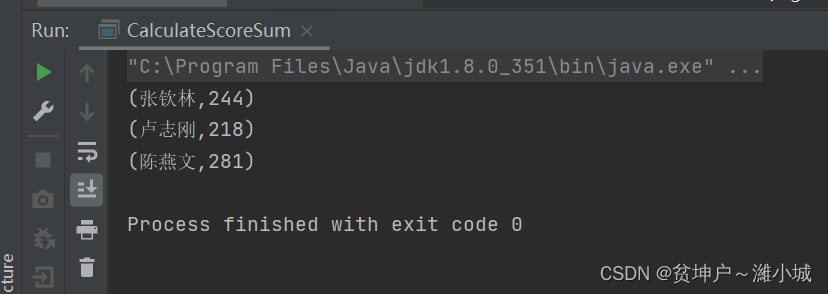
The second way: read the list of quadruple grades
net.hyw.rdd.day02CreateCalculateScoreSum02a singleton object in the package
package net.hyw.rdd.day02
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object CalculateScoreSum02 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateScoreSum")
.setMaster("local[*]")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 创建四元组成绩列表
val scores = List(
("张钦林", 78, 90, 76),
("陈燕文", 95, 88, 98),
("卢志刚", 78, 80, 60)
)
// 将四元组成绩列表转化成二元组成绩列表
val newScores = new ListBuffer[(String, Int)]();
// 通过遍历算子遍历四元组成绩列表
scores.foreach(score => {
newScores += Tuple2(score._1, score._2)
newScores += Tuple2(score._1, score._3)
newScores += Tuple2(score._1, score._4)}
)
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(newScores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
- A cyclic structure can be used to convert the list of quadruple grades into a list of binary grades
for (score <- scores) {
newScores += Tuple2(score._1, score._2)
newScores += Tuple2(score._1, score._3)
newScores += Tuple2(score._1, score._4)
}
- Run the program to see the result
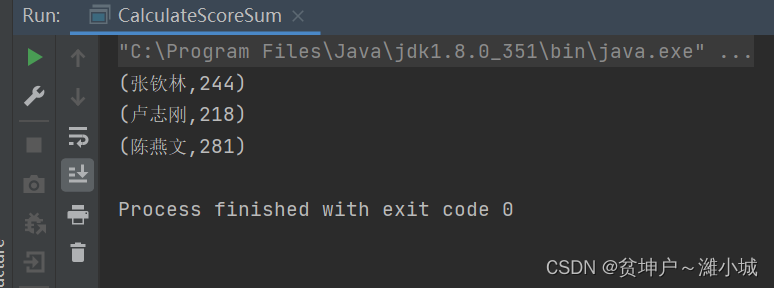
The third case: read the grade file on HDFS
- Create a grade file in the directory of the master virtual machine
/home-scores.txt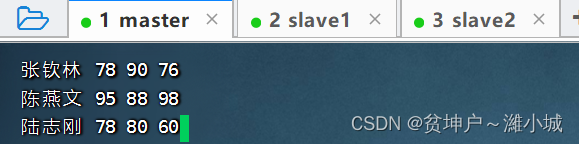
- Upload grade files to HDFS
/inputdirectory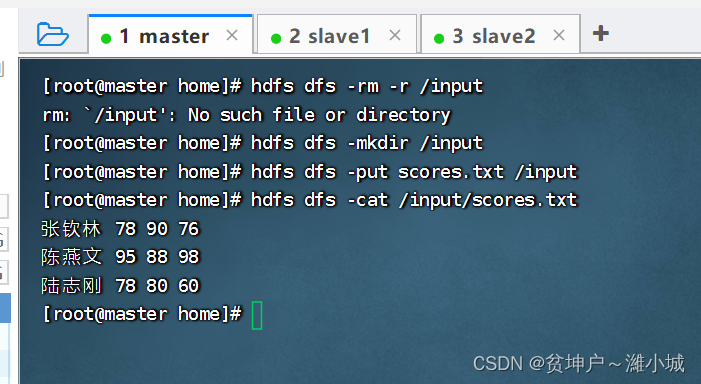
net.hw.rddCreateCalculateScoreSum03a singleton object in the package
package net.hyw.rdd.day02
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object CalculateScoreSum03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateScoreSum")
.setMaster("local[*]")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 读取成绩文件,生成RDD
val lines = sc.textFile("hdfs://master:9000/input/scores.txt")
// 定义二元组成绩列表
val scores = new ListBuffer[(String, Int)]()
// 遍历lines,填充二元组成绩列表
lines.collect.foreach(line => {
val fields = line.split(" ")
scores += Tuple2(fields(0), fields(1).toInt)
scores += Tuple2(fields(0), fields(2).toInt)
scores += Tuple2(fields(0), fields(3).toInt)
})
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
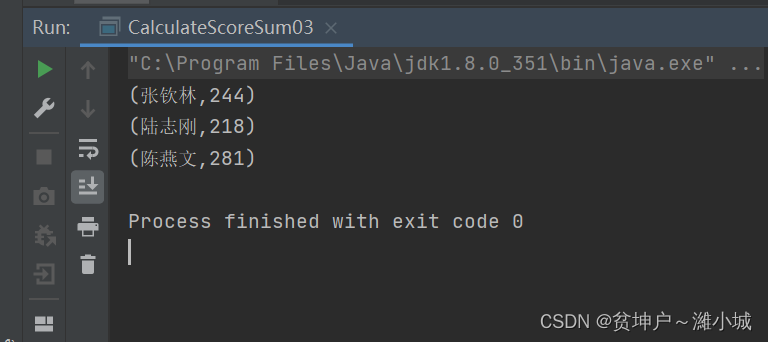
- Run the program to see the result
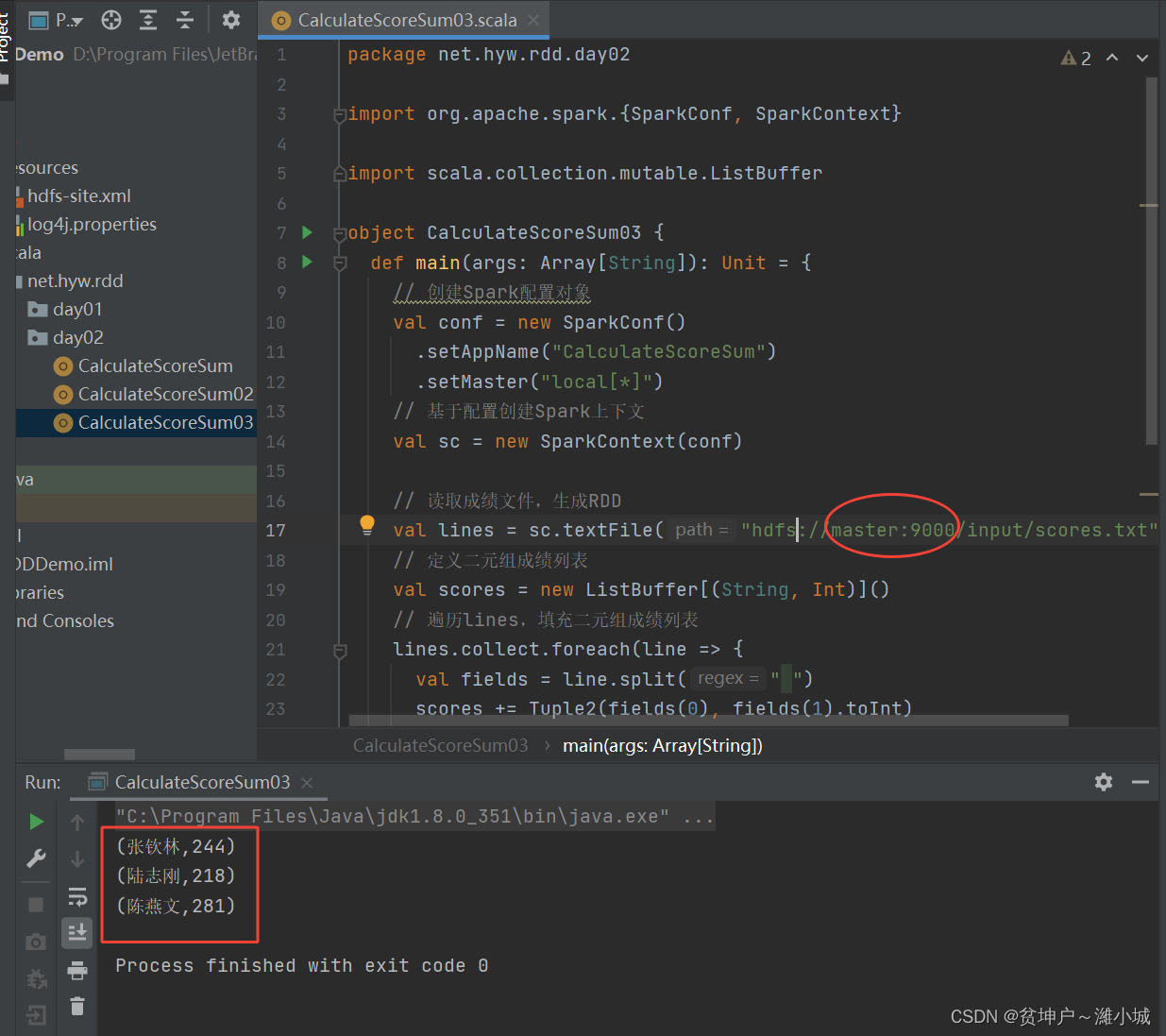
- Do the same in Spark Shell
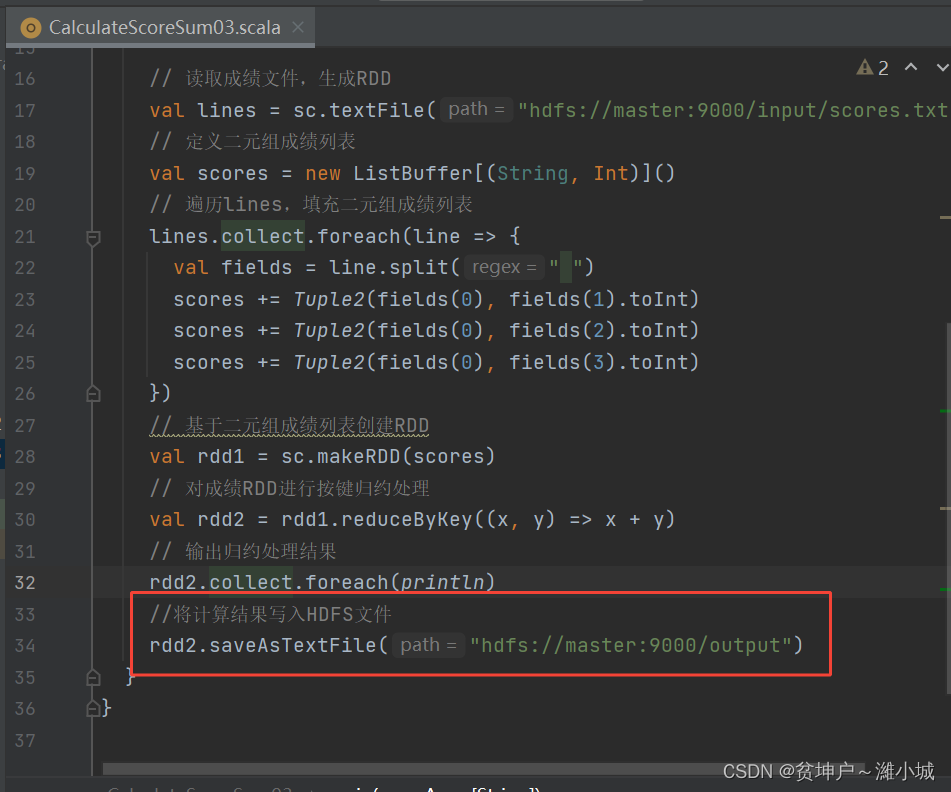
- Modify the program to write the calculation result to the HDFS file
- Run the program to see the result
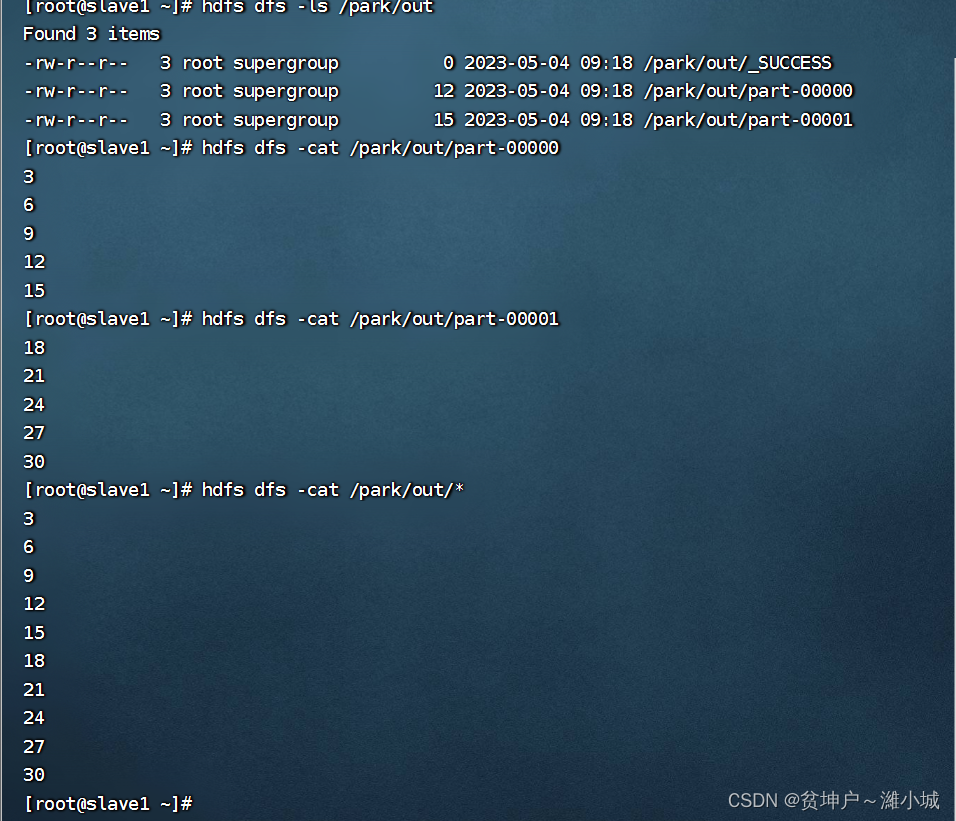
- View the result files generated on HDFS
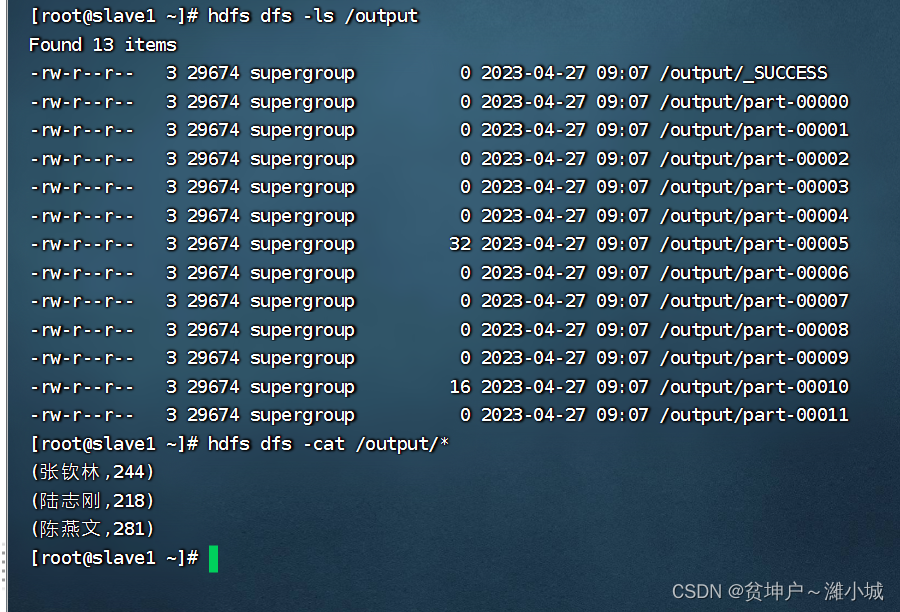
derived content



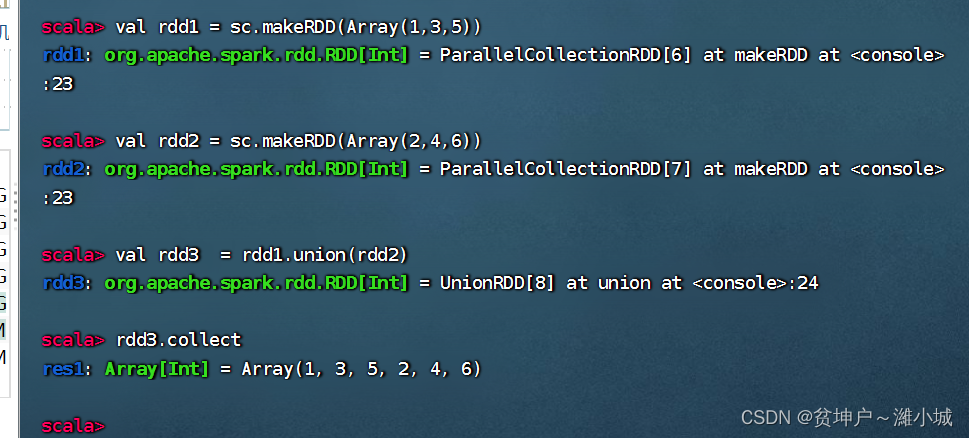
(5) Merge operator - union()
1. Merge operator function
- The union() operator merges two RDDs into a new RDD, which is mainly used to merge different data sources, and the data types in the two RDDs must be consistent.
2. Merge operator case
- Create two RDDs and merge them into a new RDD
(6) Sorting operator - sortBy()
1. Sorting operator function
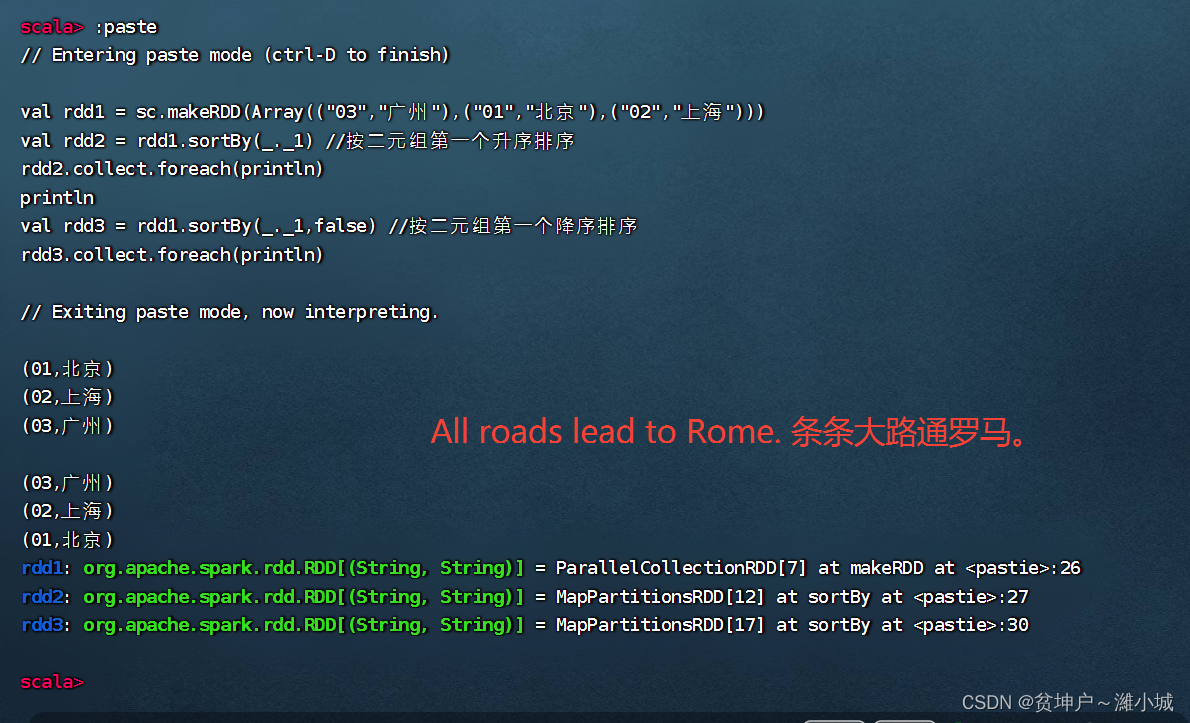
- The sortBy() operator sorts the elements in the RDD according to a certain rule. The first parameter of this operator is a sorting function, and the second parameter is a Boolean value specifying ascending (default) or descending. If descending order is required, the second parameter needs to be set to false.
2. Sorting operator case
- Three tuples are stored in an array, and the array is converted into an RDD collection, and then the RDD is sorted in descending order according to the second value in each element.
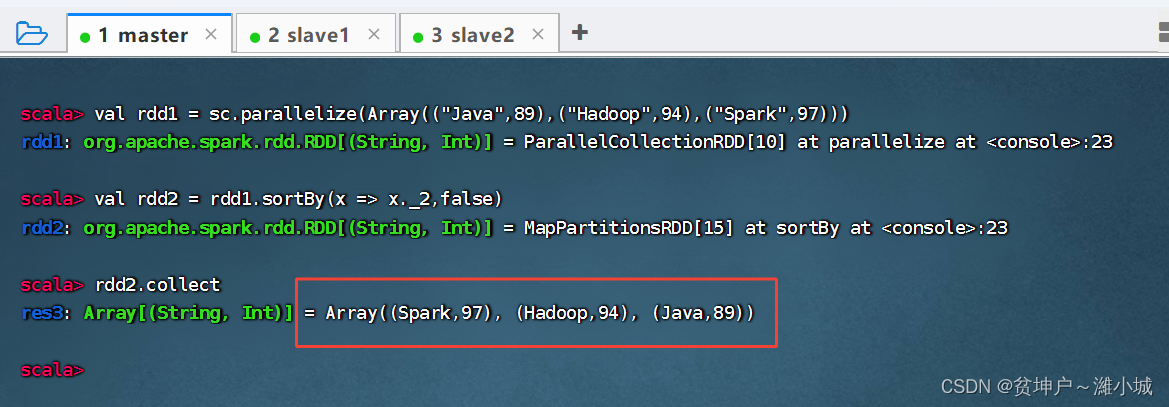
sortBy(x=>x._2,false)The x in represents each element in rdd1. Since each element of rdd1 is a tuple, usex._2to get the second value of each element. Of course,sortBy(x=>x._2,false)it can also be simplified directly tosortBy(_._2,false).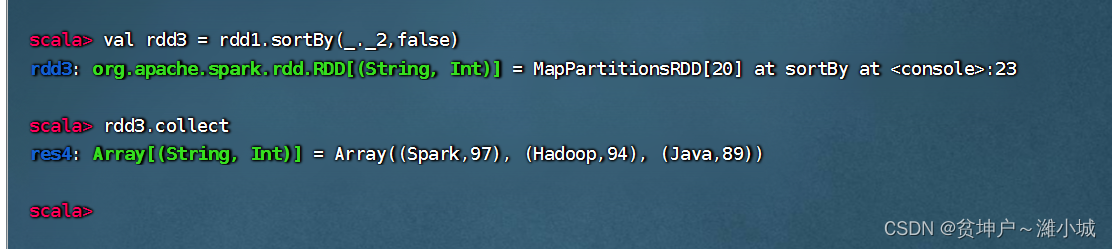
(7) Key sorting operator - sortByKey()
1. Key sort operator function
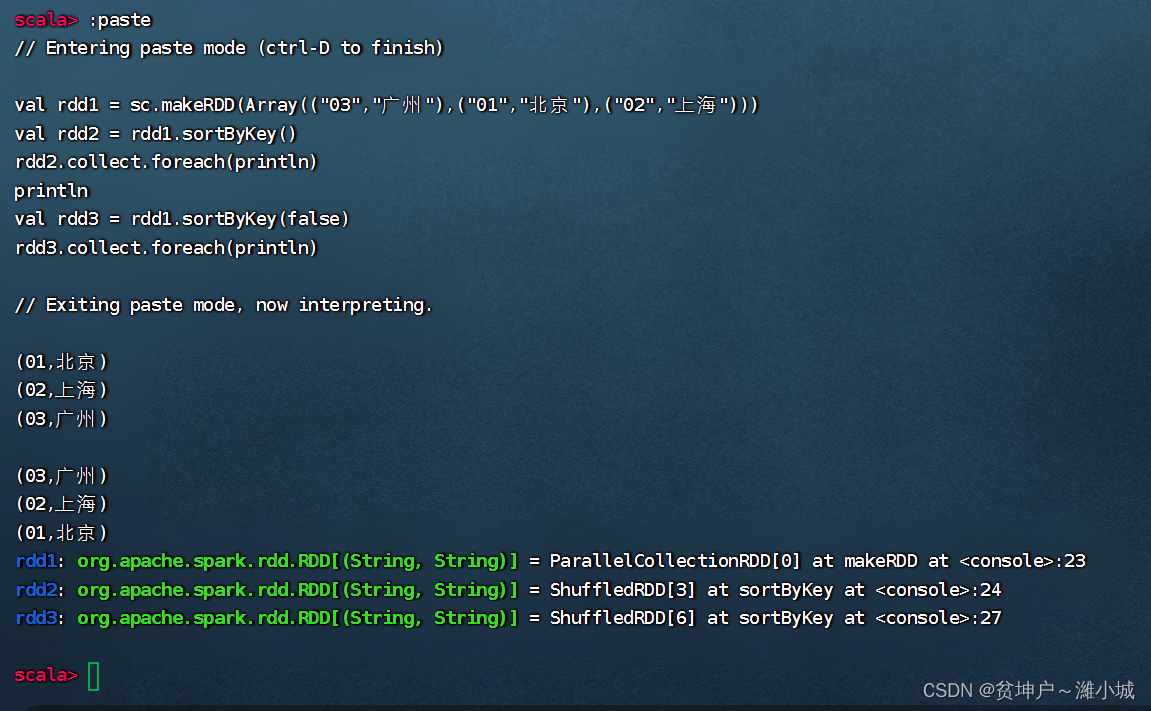
- The sortByKey() operator sorts the RDD in the form of (key, value) according to the key. The default is ascending order. If descending order is required, the parameter false can be passed in.
2. Case of key sorting operator
- Arrange the RDD composed of three binary groups in descending order first, and then in ascending order
(8) Connection operator
1. Inner connection operator - join()
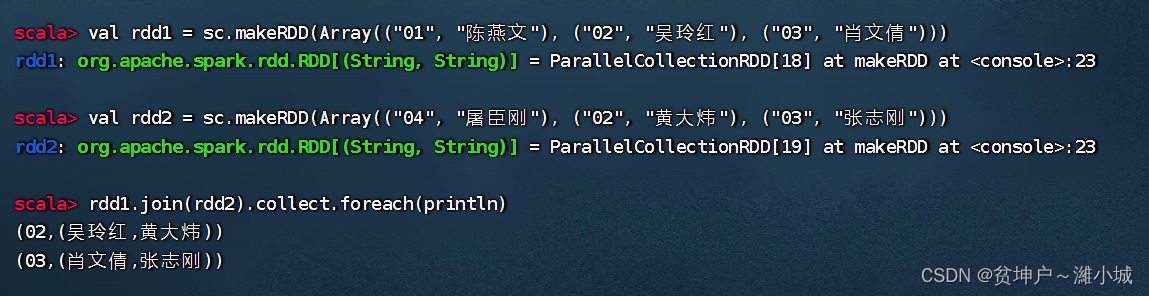
(1) Inner join operator function
- The join() operator connects two RDDs in the form of (key, value) according to the key, which is equivalent to the inner join (Inner Join) of the database, and only returns the content that both RDDs match.
(2) Inner join operator case
- Inner join rdd1 with rdd2
2. Left outer join operator - leftOuterJoin()
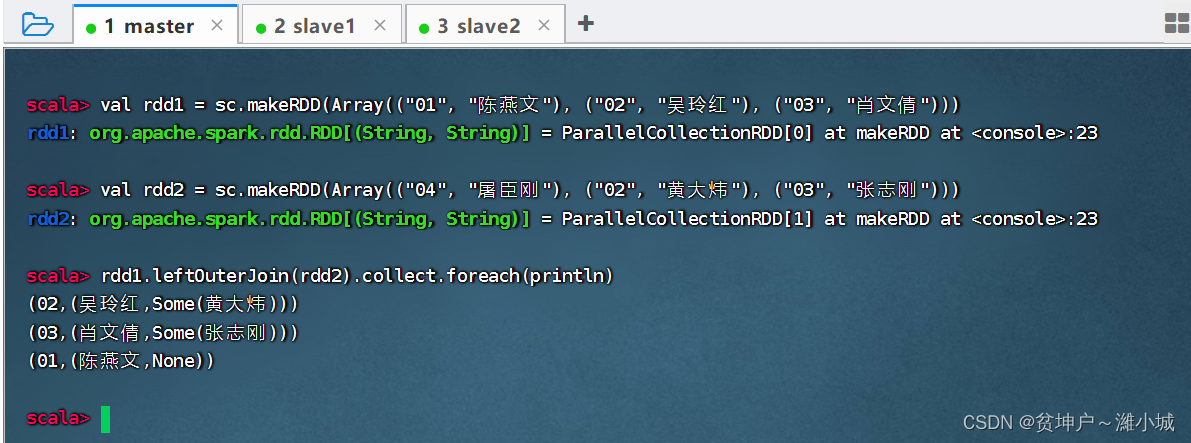
(1) Left outer join operator function
- The leftOuterJoin() operator is similar to the left outer join of the database. Based on the RDD on the left (for example, rdd1.leftOuterJoin(rdd2), based on rdd1), the records in the RDD on the left must exist. For example, the elements of rdd1 are represented by (k, v), and the elements of rdd2 are represented by (k, w). The left outer connection will be based on rdd1, and the elements with the same k in rdd2 and k in rdd1 will be connected together. , the generated result form is (k, (v, Some(w)). The remaining elements in rdd1 are still part of the result, and the element form is (k, (v, None). Both Some and None belong to the Option type, Option Type is used to indicate that a value is optional (with or without value). If it is determined that there is a value, use Some (value) to represent the value; if it is determined to have no value, use None to represent the value.
(2) Left outer join operator case
- rdd1 performs left outer join with rdd2
3. Right outer join operator - rightOuterJoin()
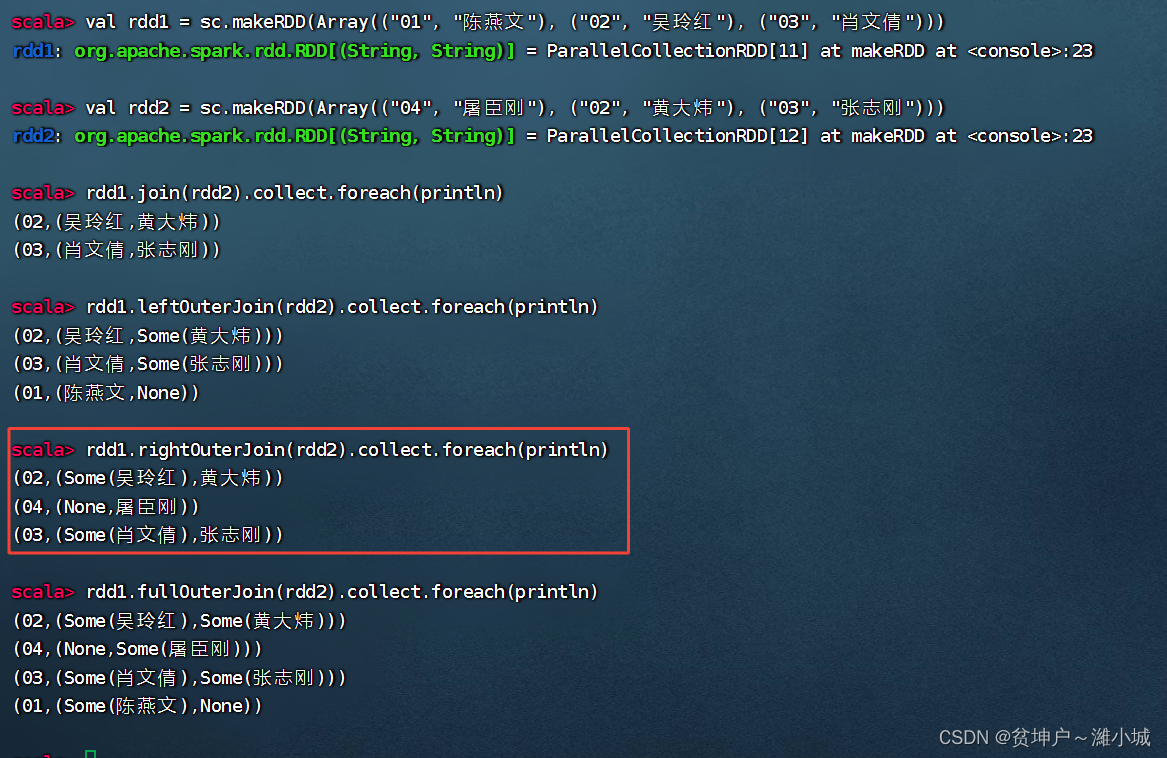
(1) Right outer join operator function
- The use of the rightOuterJoin() operator is opposite to that of the leftOuterJoin() operator. It is similar to the right outer join of the database, based on the RDD on the right (for example, rdd1.rightOuterJoin(rdd2), based on rdd2), the records of the RDD on the right There must be.
(2) Right outer join operator case
- Right outer join of rdd1 and rdd2
4. Full outer join operator - fullOuterJoin()
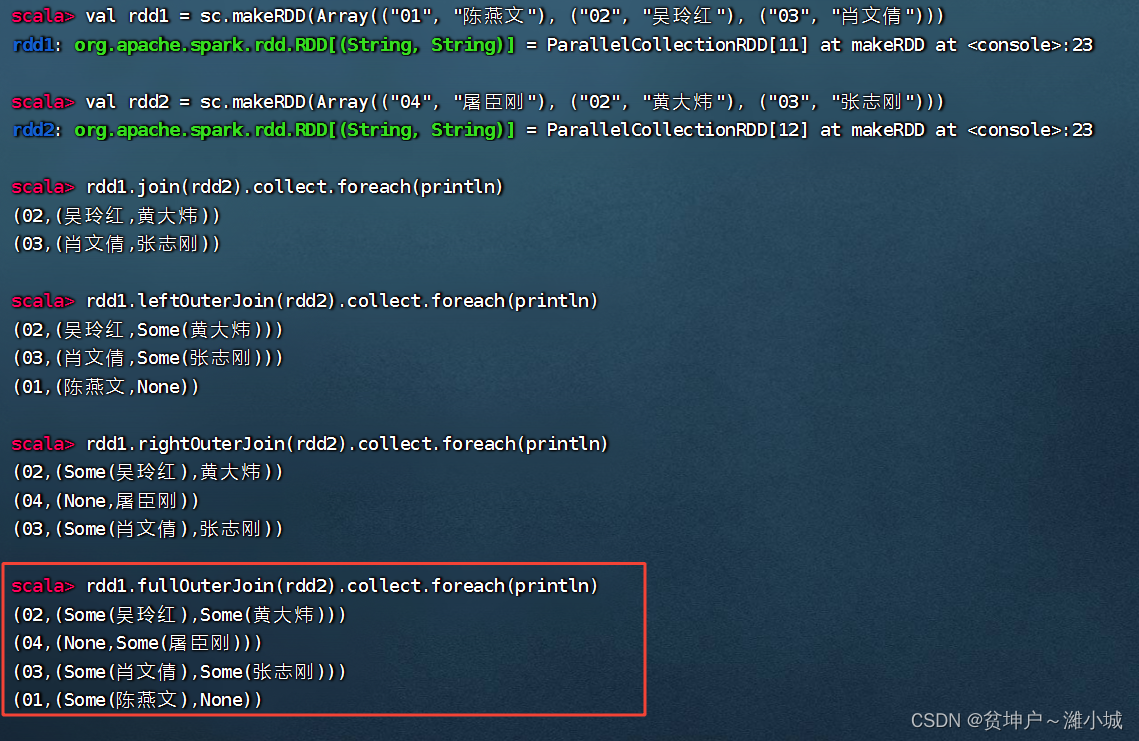
(1) Full outer join operator function
- The fullOuterJoin() operator is similar to the full outer join of the database, which is equivalent to taking the union of two RDDs, and the records of both RDDs will exist. Take None if the value does not exist.
(2) Full outer join operator case
- rdd1 and rdd2 perform a full outer join
(9) Intersection operator - intersection()
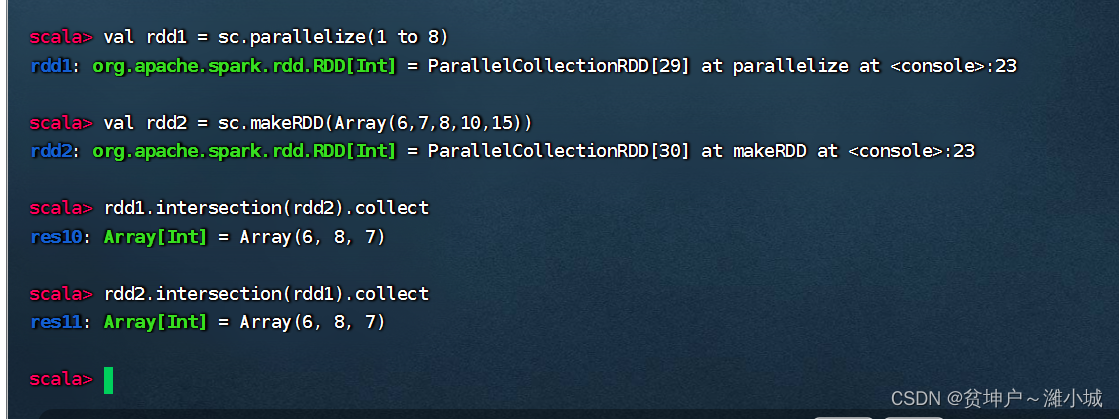
1. Intersection operator function
- The intersection() operator performs an intersection operation on two RDDs and returns a new RDD. The two operator types are required to be consistent.
2. Case of intersection operator
- Intersection operation between rdd1 and rdd2
(10) Deduplication operator - distinct()
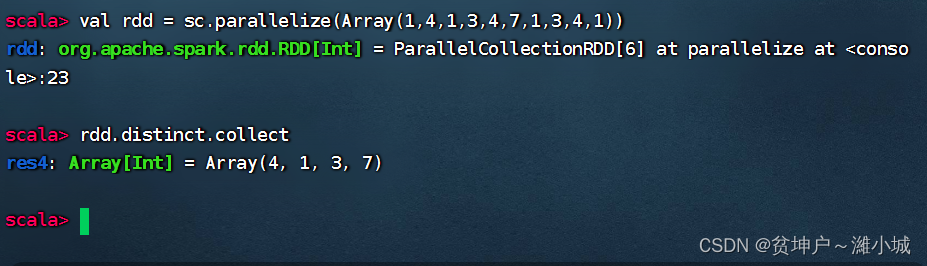
1. Deduplication operator function
- The distinct() operator deduplicates the data in the RDD and returns a new RDD. It's a bit like a collection that doesn't allow duplicate elements.
2. Deduplication operator case
- Remove duplicate elements in rdd
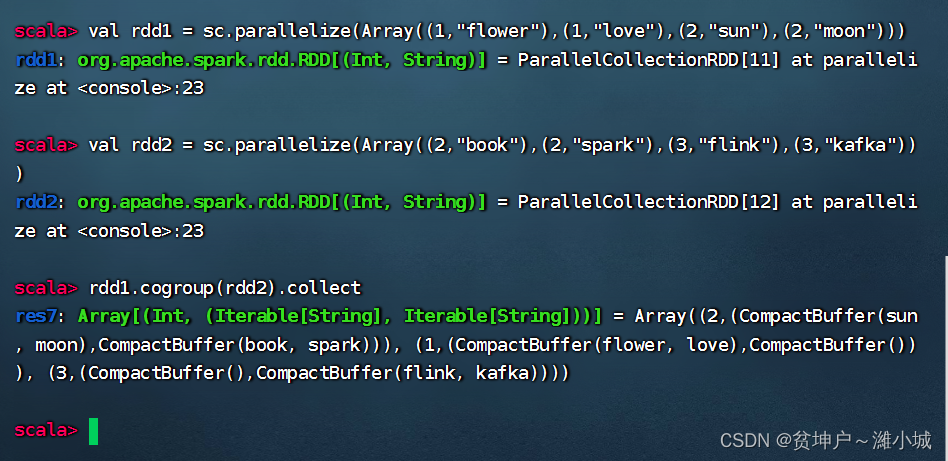
(11) Combined grouping operator - cogroup()
1. Combination grouping operator function
- The cogroup() operator combines two RDDs in the form of (key, value) according to the key, which is equivalent to performing a union operation according to the key. For example, the elements of rdd1 are represented by (k, v), the elements of rdd2 are represented by (k, w), and the result generated by executing rdd1.cogroup(rdd2) is in the form of (k, (Iterable, Iterable)).
2. Combined grouping operator case
- rdd1 and rdd2 perform combined grouping operations
5. Master the action operator
- The transformation operator in Spark does not execute the calculation immediately, but executes the corresponding statement when encountering the action operator, triggering Spark's task scheduling.

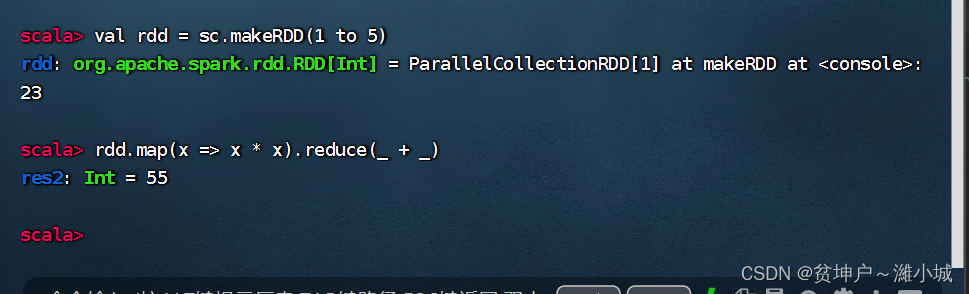
(1) Reduction operator - reduce()
1. Reduction operator function
- The reduce() operator performs reduction calculations according to the function passed in
2. Case of reduction operator
- Calculate the value of 1 + 2 + 3 + ... ... + 100 1 + 2 + 3 + ... + 1001 + 2 + 3 + ... + 100

- Calculate the value of 1 2 + 2 2 + 3 2 + 4 2 + 5 2 1^2 + 2^2 + 3^2 + 4^2 + 5^212+22+32+42+52
(3) Key count operator - countByKey()
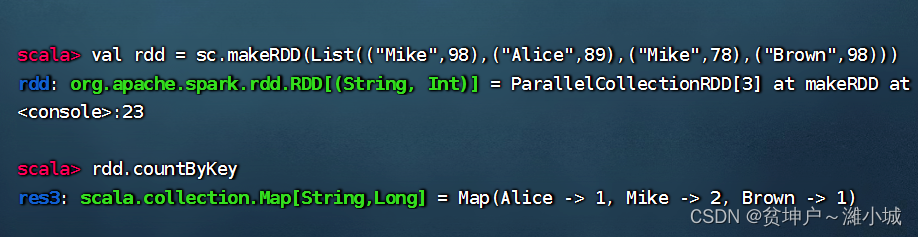
1. Button counting operator function
- Press the key to count the number of occurrences of the RDD key value, and return a map consisting of the key value and the number of times.
2. Case of button counting operator
- The List collection stores tuples in the form of key-value pairs. Use the List collection to create an RDD, and then calculate countByKey() on it.
(4) Front intercept operator - take(n)
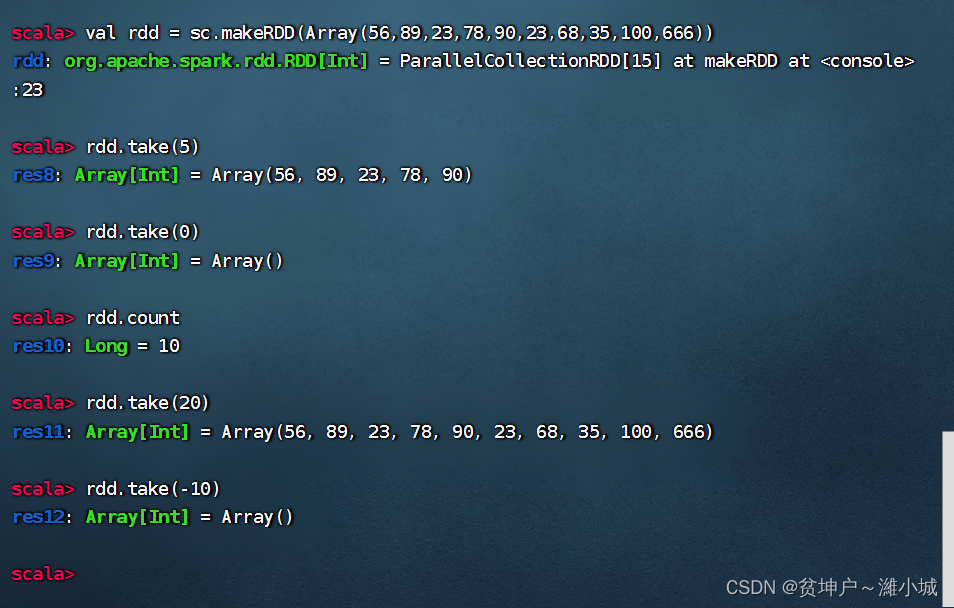
1. Front intercept operator function
- Return the first n elements of RDD (try to access the least partitions at the same time), the returned results are unordered, and the test is used.
2. Pre-interception operator case
- Returns an array of the first 5, 0, 20, and -10 elements in the collection
(5) Traversal operator - foreach()
1. Traverse operator function
- Calculate each element in the RDD, but do not return to the local (just access the data), you can use println() to print the data friendly.
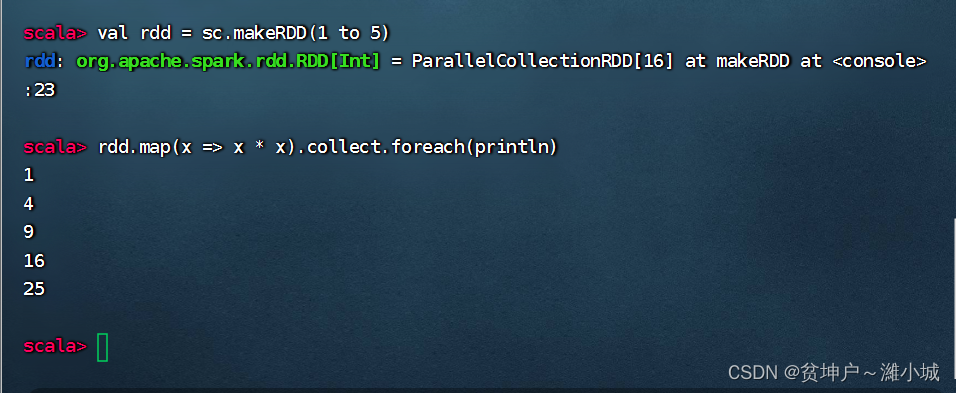
2. Cases of traversal operators
- Square each element in the RDD and output
(6) File save operator - saveAsFile()
1. Save file operator function
- Save RDD data to local file or HDFS file
2. Case of file storage operator
- Save rdd content to
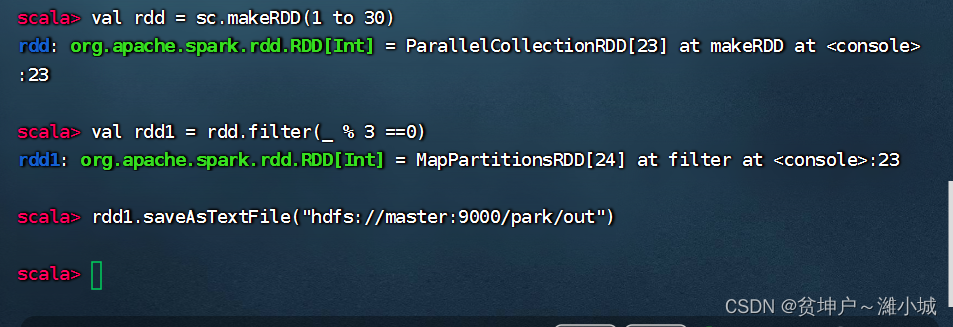
 /park/out.txt
/park/out.txt