本文声明:仅为了学习爬虫编写,请勿商业或恶意攻击网站,解释权归作者所有
由于智联招聘网的信息是动态加载的,所有对于新手比较难爬,重点在于找准确请求url
注意:前三个字段是同一个请求,address字段是详情页
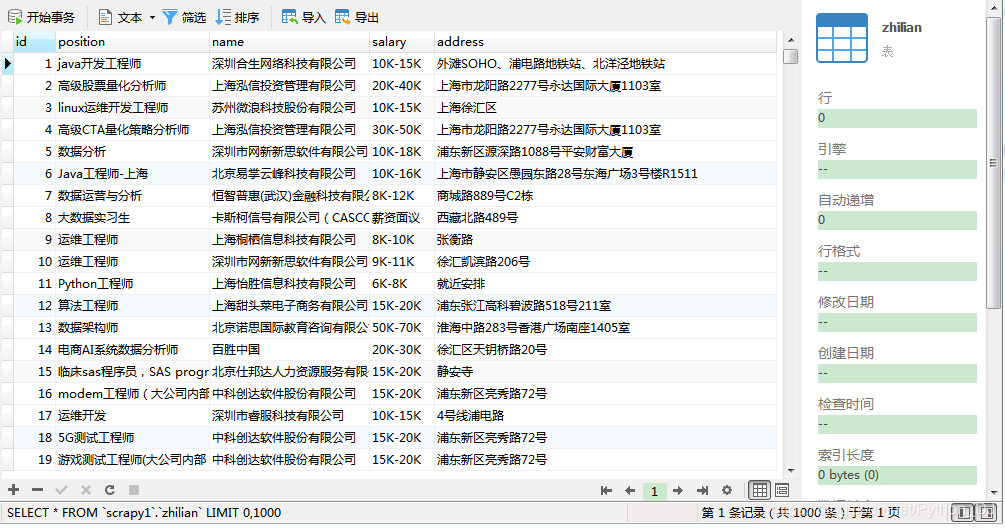
实现效果:mysql
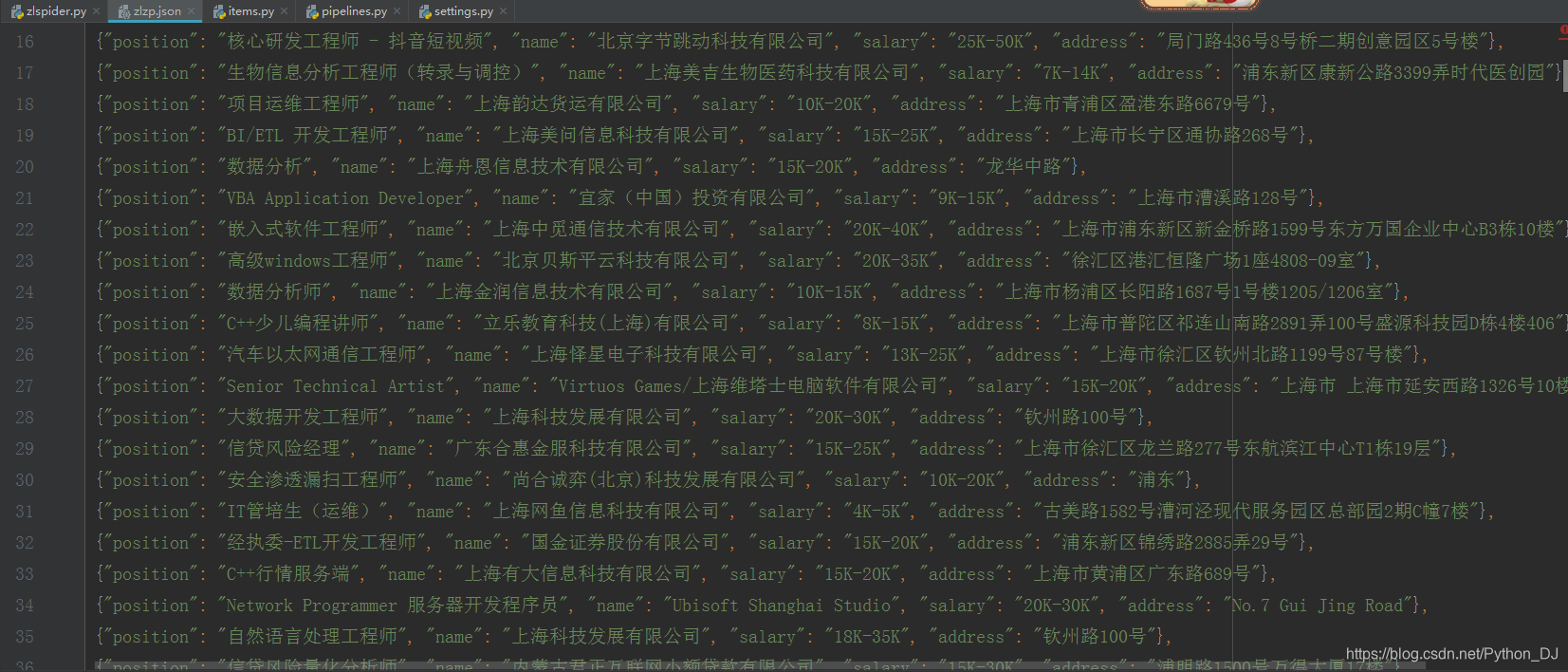
实现效果:json文件
#执行文件
# -*- coding: utf-8 -*-
import scrapy
import json
from zlzp.items import ZlzpItem
# 下面这个类urlencode,用于get路由拼接 a=1&b=2&c=3
from urllib.parse import urlencode
class ZlspiderSpider(scrapy.Spider):
name = 'zlspider'
# allowed_domains = ['sou.zhaopin.com']
start_urls = ['https://fe-api.zhaopin.com/c/i/sou?']
def start_requests(self):
print("成伟无敌最俊朗。。。")
for i in range(0,1001,90):
data = {
"start":i,
"pageSize":90,
"cityId":538,
"kw":"python",
"kt":3
}
for url in self.start_urls:
new_url = url + urlencode(data)
yield scrapy.Request(url=new_url,callback=self.parse)
def parse(self, response):
data = json.loads(response.text)
res1 = data["data"]
res2 = res1["results"]
for i in res2:
# 每个公司都实例化一个item
item = ZlzpItem()
item["position"] = i["jobName"]
item["name"] = i["company"]["name"]
item["salary"] = i["salary"]
# 找到详情页的连接
positionURL = i["positionURL"]
yield scrapy.Request(url=positionURL,callback=self.detail,meta={"item":item})
# 详情页
def detail(self,response):
item = response.meta["item"]
address = response.xpath('//div[@class="job-address"]/div/span/text()').get()
item["address"] = address
# print(item)
# 提交数据到管道
yield item
items.py文件
import scrapy
class ZlzpItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
position = scrapy.Field()
name = scrapy.Field()
salary = scrapy.Field()
address = scrapy.Field()
pass
settings.py文件
USER_AGENT= "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 开启管道
ITEM_PIPELINES = {
'zlzp.pipelines.ZlzpPipeline': 300,
'zlzp.pipelines.ZlzpJsonPipeline': 301,
}
pipelines.py管道文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
import json
import codecs
import os
# 保存到数据库
class ZlzpPipeline(object):
conn = None
mycursor = None
# 打开数据库
def open_spider(self,spider):
print("数据库连接中。。。")
# 连接数据库
self.conn = pymysql.connect(host='localhost',user='root',password='root123',db="scrapy1",port=3306)
# 获取游标
self.mycursor = self.conn.cursor()
# 执行爬虫
def process_item(self, item, spider):
position = item["position"]
name = item["name"]
salary = item["salary"]
address = item["address"]
# 插入记录
sql = "insert into zhilian values (null,'%s','%s','%s','%s')"%(position,name,salary,address)
# 执行
self.mycursor.execute(sql)
# 提交 执行的SQL才能生效
self.conn.commit()
print("正在插入%s的数据..."%name)
return item
# 关闭爬虫
def close_spider(self,spider):
print("断开数据库连接。。。")
# 关闭游标
self.mycursor.close()
# 关闭数据库
self.conn.close()
# 保存到json文件
class ZlzpJsonPipeline(object):
f = None
# 开始爬虫
def open_spider(self,spider):
# 如果不使用codecs.open打开文件,则close_spider里面的语句不生效,就是一个编码和解码的工具
self.f = codecs.open("zlzp.json","w",encoding="utf-8")
# 写入下面的字符串
self.f.write('"list":[')
# 执行爬虫
def process_item(self,item,spider):
# 想存储json文件,就得把item对象转变为字典对象
res = dict(item)
# 再把字典对象转换为json数据
# 这是因为json.dumps 序列化时对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False:
# 直接写入字典会保存,所以把字典形式的作为list列表的值字符串格式写入
str = json.dumps(res,ensure_ascii=False)
# 把数据写入json文件
self.f.write(str + "," + "\n")
return item
# 关闭爬虫
def close_spider(self,spider):
# SEEK_END 移动游标到文件最后,再向前偏移2个字符
self.f.seek(-2,os.SEEK_END)
# 移除偏移后的所有字符 移除了逗号,和一个换行符\n
self.f.truncate()
# 完成列表尾部
self.f.write("]")
# 关闭文件
self.f.close()
