1. 简介
因为想要找到一个数据分析的工作,能够了解到市面上现有的职位招聘信息也会对找工作有所帮助。
今天就来爬取一下智联招聘上数据分析师的招聘信息,并存入本地的MySQL。
2. 页面分析
2.1 找到数据来源
打开智联招聘首页,选择数据分析师职位,跳转进入数据分析师的详情页面。我们需要抓取的数据都呈现在这里。
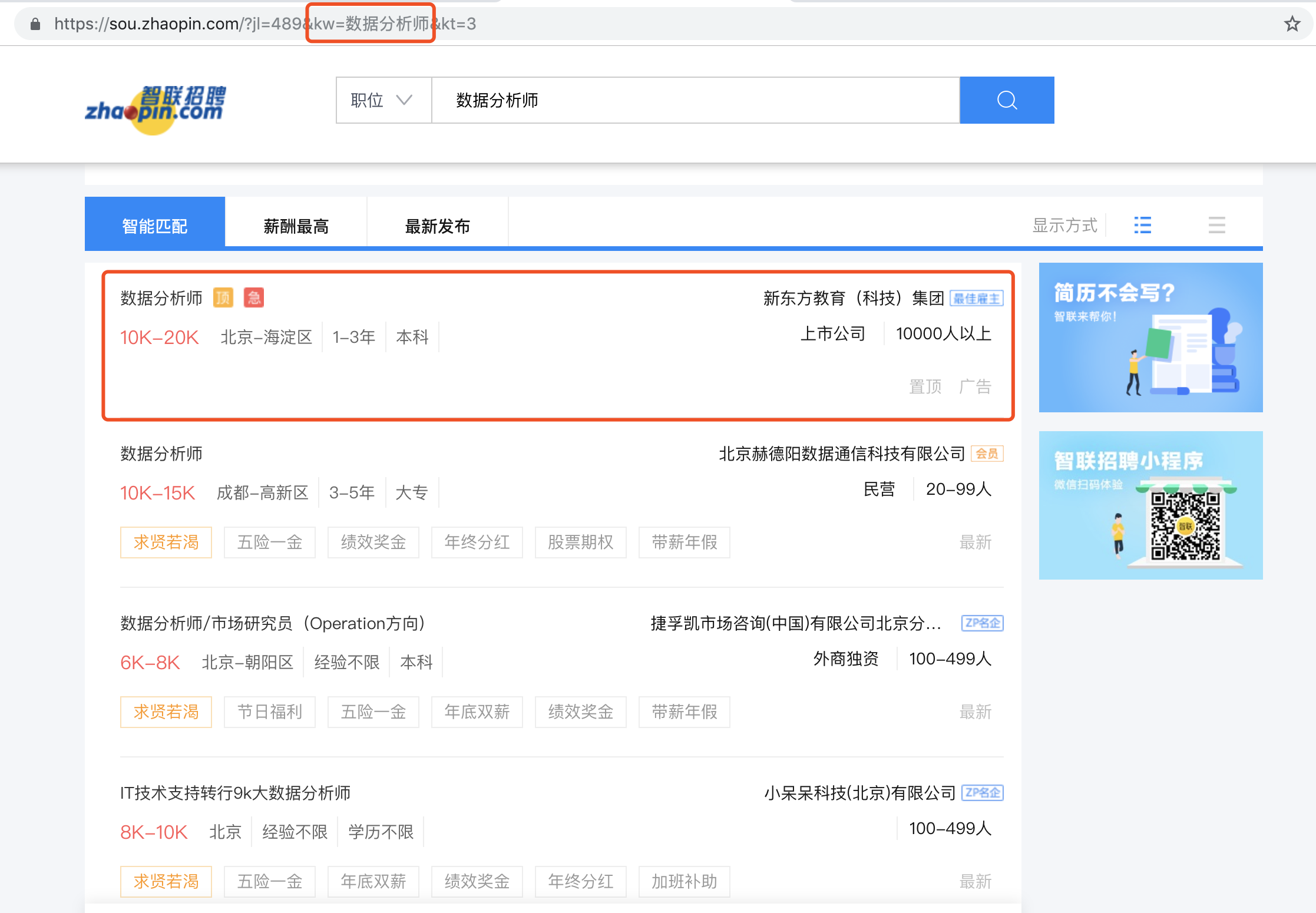
既然我们想要的数据都在这个页面上,那么就对页面分析一下,这些数据都是用什么方式传输的。
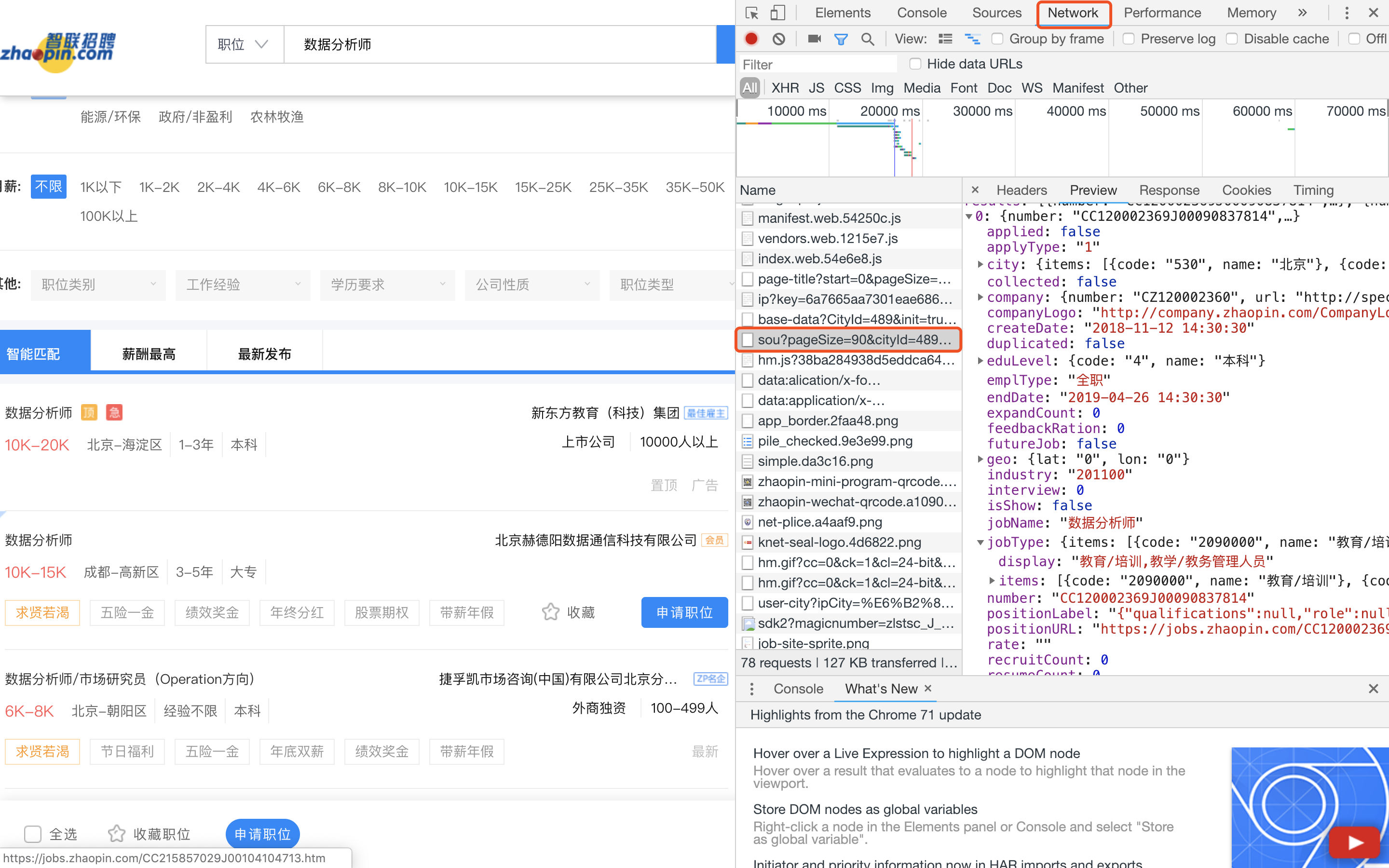
首先右键查看网页源代码,发现职位信息并不在源代码里面。也就是说,职位信息是通过其他来源加载的,并不是直接写入这个网页的代码里。

右键检查,找到network一览进行查看,发现职位信息其实是来源于接口返回的一个json格式的数据。所以我们要抓取的数据就来源于这个接口:
2.2 分析url构成
由2.1,我们已经找到数据来源的url为
https://fe-api.zhaopin.com/c/i/sou?pageSize=90&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3&_v=0.55861702&x-zp-page-request-id=112663d962234d3e8ca52b6e9d5ab4ea-1545222165002-62086
这个url中包含了很多参数,分别对应在职位搜索时加入的条件:
pageSize:指每一页显示的职位数量,也就是通过url一次取多少数
cityId:指职位的城市划分,489代表全国
workExperience:指职位要求的工作经验
education:职位要求的学历水平
companyType:公司的经营类别
employmentType:职位的性质,如实习/全职/兼职
jobWelfareTag:福利
kw:搜索关键字,如果关键字包含汉字,则进行url转码。如:此处,数据分析师转码为%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88
kt/_v/x-zp-request-id:暂时没有弄明白具体是指什么
上面的url只是搜索结果第一页对应的来源,而我们的搜索结果其实是有很多页进行展示的。
通过同样的方式,可以拿到搜索结果接下来几页对应的url。
以第二页对应的url为例:
https://fe-api.zhaopin.com/c/i/sou?start=90&pageSize=90&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3&_v=0.55861702&x-zp-page-request-id=112663d962234d3e8ca52b6e9d5ab4ea-1545222165002-62086
对比之后,发现:区别之处仅仅在于第二页对应的url加入了一个start参数。
start=90,即为第二页的搜索结果。结合pageSize参数,每一页展示90条职位信息。也就是说,start=90表示第二页,start=180表示第三页......
我们就知道了如何去得到每一页搜索结果对应的数据来源了。
3. 抓取数据
3.1 设计数据获取流程
既然我们已经发现了,每一页的职位信息都来自于访问接口后返回的json格式的数据,我们就可以直接访问接口然后读取json就可以得到想要的职位信息了。
步骤如下:
1) 设定关键字访问接口,获得包含职位信息的json数据
2) 从返回的json中提取需要的数据,存入本地MySQL中
3.2 代码实现
因为这些职位数据是没有经过登陆就可以获取的,而且在请求头中并没有发现什么特别的信息。尝试后发现,智联招聘对传输职位信息的这个接口没有做什么反爬限制,直接使用urllib包的urlopen()方法就可以获得数据。
import pymysql
import urllib
import json
import time
import random
# 在sql中创建表
def create_table_mysql():
db = pymysql.connect(host='localhost', user='root', password='mysqlkey', db='test_db', port=3306)
# 创建游标对象cursor
cursor = db.cursor()
# 执行SQL,如果表存在就删除
cursor.execute('DROP TABLE IF EXISTS zlzp_sjfx')
# 创建表
create_table_sql = """
CREATE TABLE zlzp_sjfx(
job_number CHAR(100) COMMENT '记录编号',
job_type_big_num CHAR(100) COMMENT '职业大分类编号',
job_type_big_name CHAR(100) COMMENT '职业大分类名称',
job_type_medium_num CHAR(100) COMMENT '职业细分类编号',
job_type_medium_name CHAR(100) COMMENT '职业细分类名称',
company_num CHAR(100) COMMENT '公司编号',
company_url CHAR(200) COMMENT '公司对应url',
company_name CHAR(100) COMMENT '公司名称',
company_size_num CHAR(100) COMMENT '公司规模编号',
company_size CHAR(100) COMMENT '公司规模',
company_type_num CHAR(100) COMMENT '公司类型编号',
company_type CHAR(100) COMMENT '公司类型',
job_url CHAR(200) COMMENT '职位对应url',
working_exp_num CHAR(100) COMMENT '工作经验编号',
working_exp CHAR(100) COMMENT '工作经验',
edu_level_num CHAR(100) COMMENT '教育水平编号',
edu_level CHAR(100) COMMENT '教育水平',
job_salary CHAR(100) COMMENT '工资',
job_type CHAR(100) COMMENT '工作类型',
job_name CHAR(100) COMMENT '工作类型',
job_location_lat CHAR(100) COMMENT '经度',
job_location_lon CHAR(100) COMMENT '纬度',
job_city CHAR(100) COMMENT '工作城市',
job_updatetime CHAR(100) COMMENT '更新时间',
job_createtime CHAR(100) COMMENT '创建时间',
job_endtime CHAR(100) COMMENT '结束时间',
job_welfare CHAR(100) COMMENT '工作福利'
)"""
try:
# 创建表
cursor.execute(create_table_sql)
# 提交执行
db.commit()
print('table zlzp_sjfx create done')
except:
# 回滚
db.rollback()
print('table zlzp_sjfx create not done')
return db, cursor
db, cursor = create_table_mysql()
time_0 = time.time()
for i in range(500):
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=90&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3&_v=0.89067574&x-zp-page-request-id=866368d6313e41c38a6e600b1c5d8082-1545034860140-256948'.format(i*90)
if i==0:
url = 'https://fe-api.zhaopin.com/c/i/sou?pageSize=90&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3&_v=0.89067574&x-zp-page-request-id=866368d6313e41c38a6e600b1c5d8082-1545034860140-256948'
page = urllib.request.urlopen(url).read()
data = json.loads(page)
time.sleep(random.uniform(1.2, 2.1))
add_sql = """
INSERT INTO zlzp_sjfx
(job_number, job_type_big_num, job_type_big_name,job_type_medium_num,job_type_medium_name,company_num,company_url,company_name,
company_size_num,
company_size,
company_type_num,
company_type,
job_url,
working_exp_num,
working_exp,
edu_level_num,
edu_level,
job_salary,
job_type,
job_name,
job_location_lat,
job_location_lon,
job_city,
job_updatetime,
job_createtime,
job_endtime,
job_welfare)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
for each_job in data['data']['results']:
add_data = (
each_job['number'], # 编号
each_job['jobType']['items'][0]['code'], # 职业大分类编号
each_job['jobType']['items'][0]['name'], # 职业大分类名称
each_job['jobType']['items'][1]['code'], # 职业细分类编号
each_job['jobType']['items'][1]['name'], # 职业细分类名称
each_job['company']['number'], # 公司编号
each_job['company']['url'], # 公司对应url
each_job['company']['name'], # 公司名称
each_job['company']['size']['code'], # 公司规模编号
each_job['company']['size']['name'], # 公司规模
each_job['company']['type']['code'], # 公司类型编号
each_job['company']['type']['name'], # 公司类型
each_job['positionURL'], # 职位对应url
each_job['workingExp']['code'], # 工作经验编号
each_job['workingExp']['name'], # 工作经验
each_job['eduLevel']['code'], # 教育水平编号
each_job['eduLevel']['name'], # 教育水平
each_job['salary'], # 工资
each_job['emplType'], # 工作类型
each_job['jobName'], # 工作名称
each_job['geo']['lat'], # 经度
each_job['geo']['lon'], # 纬度
each_job['city']['display'], # 工作城市
each_job['updateDate'],
each_job['createDate'],
each_job['endDate'],
'/'.join(each_job['welfare']) # 工作福利
)
cursor.execute(add_sql, add_data)
try:
db.commit()
print('page', i, 'done!用时', time.time()-time_0)
except:
db.rollback()
print('page', i, 'not done')
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()