在智联网站上搜索“大数据分析”
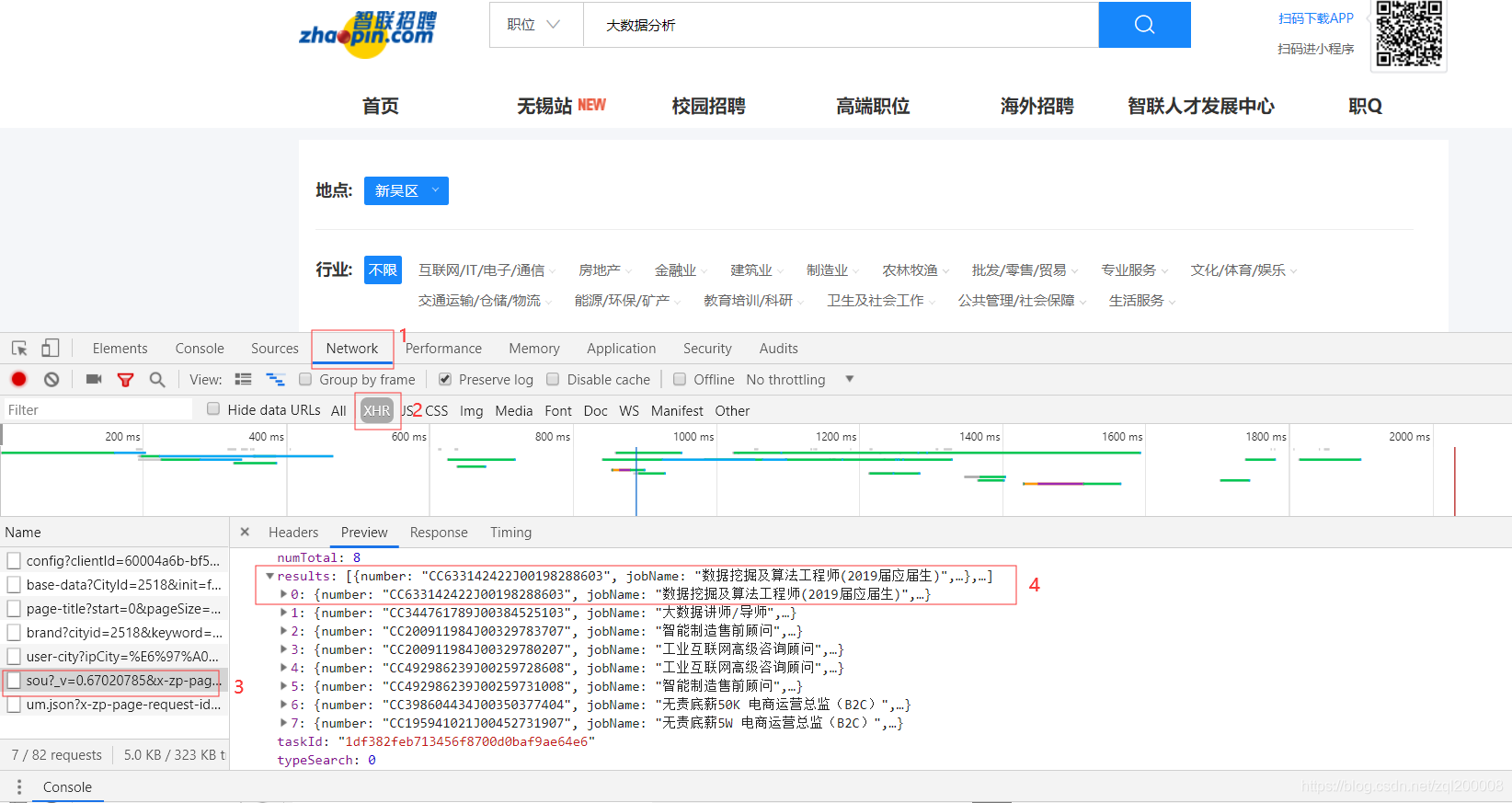
F12检索网页,找到对应的json
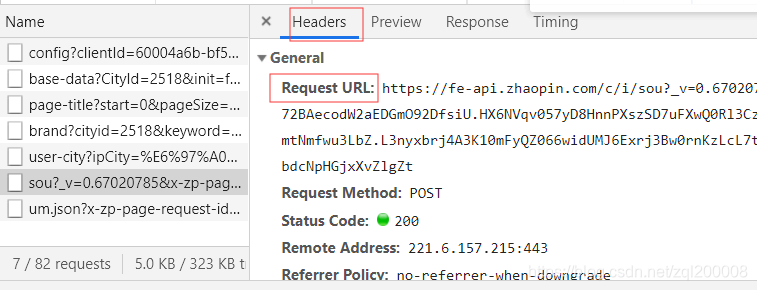
抓取URL
import requests
import pandas as pd #用于显示数据框
import time #时间停留
url = r'https://fe-api.zhaopin.com/c/i/sou?_v=0.15071971&x-zp-page-request-id=eb7282843faf4a2d827002757bcdd769-1575511230999-129076&x-zp-client-id=60004a6b-bf5e-41c0-9a37-e2aa003360c8&MmEwMD=4CkD_v9XYKkRPQD7x5kBhxL5rYE8kibi89tA7lNM3gE_o.GmRqE0CXdzn7hhrlUY4sfi_Dh2K.E.lZ7V2ohekVswQoqKdW8i4H5r5Ie9ke9hETN2dUGVd.VplT9huTmAvE69pF0udgsddmqOiGqOkO55_wyaV0lLV4uTkR41VcMsb5qV3UPIOoHl160CiBmNryjs5bk7Z6RLlZWkhRxVpXb0DbEzTXLv7T8Xst6dQ1dj1fDP.q2ERisCklLcxyRy.WgM8Xtk6mLcYkInmzFbxrmw_wz1SCOi1co_5brw8ntInYCL74N6Cv2TGFU_fxfjlKGQtShNRQliBXrk8w1ULqTTUTMk2TcdyLC3PGDCSHZajRKH7xzeulcZ0jwm9B03YBTixrfpodjXKIs0wH6brVp2Q'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'} #构建请求信息避免反爬虫
response = requests.get(url,headers=headers)
datas = response.json()
datas
爬取到json里面的内容
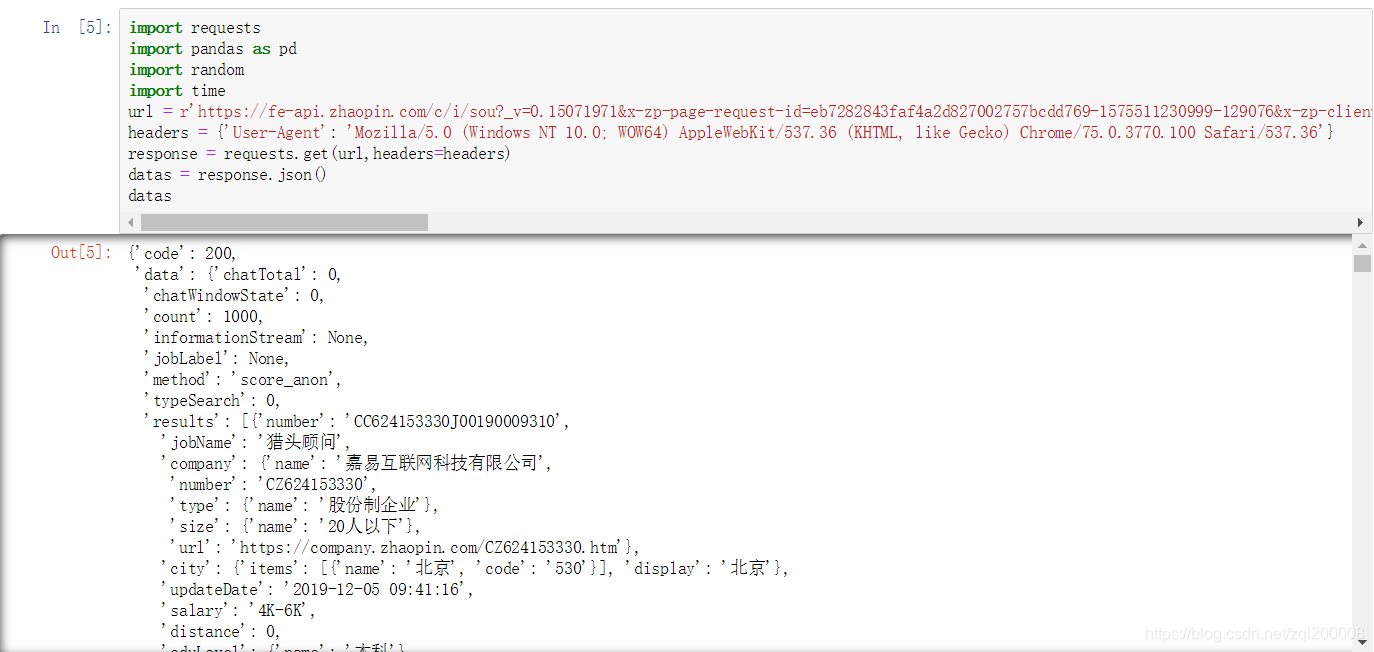
解析json中的内容

列一个循环找到[‘data’][‘results’]编写如下:就可以将json内容分别取出
for i in res_['data']['results']:
city = i['city']['items'][0]['name']
company = i['company']['name']
type = i['company']['type']['name']
size = i['company']['size']['name']
eduLevel = i['eduLevel']['name']
jobname = i['jobName']
salary = i['salary']
workingExp = i['workingExp']['name']
welfare = i['welfare']
number = i['number'][0]
最后保存到CSV
with open('zhilian.csv','a',encoding='gbk',newline='')as csv_file:
writer = csv.writer(csv_file)
try:
writer.writerow(item)
except Exception as e:
print('writer error:',e)
部分内容如下:
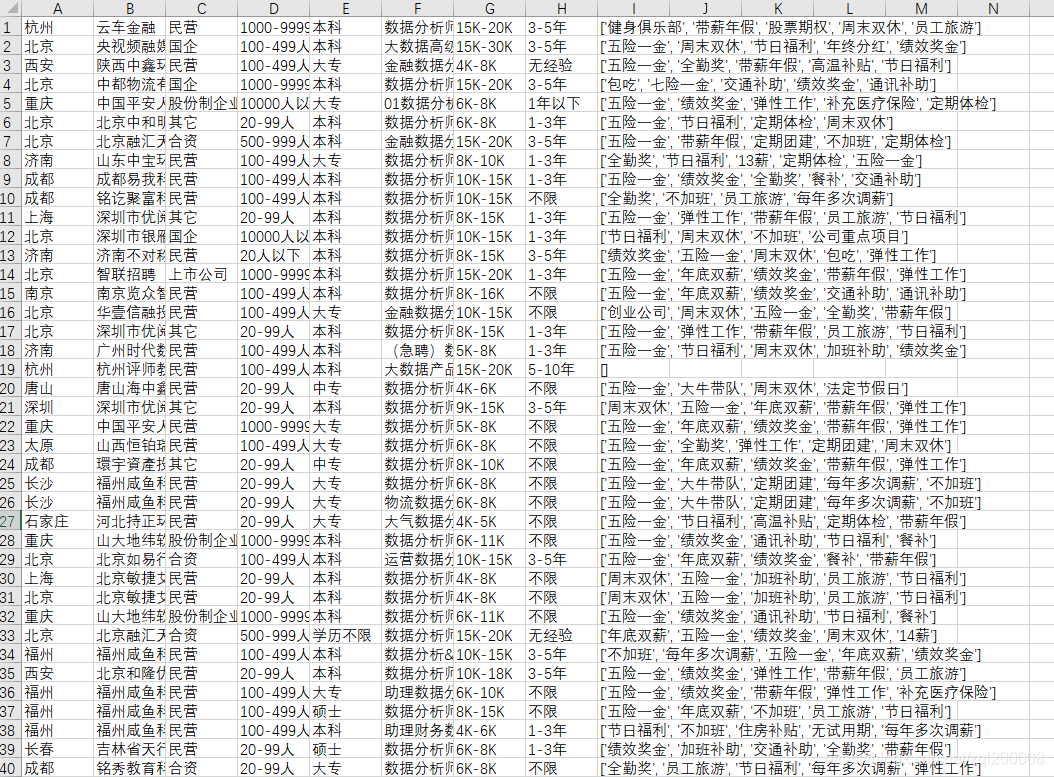
附上完整代码:
import requests
from lxml import etree
import random
import time
import csv
def csv_write(item):
with open('zhilian.csv','a',encoding='gbk',newline='')as csv_file:
writer = csv.writer(csv_file)
try:
writer.writerow(item)
except Exception as e:
print('writer error:',e)
def spider(the_url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
r = requests.get(the_url,headers=headers)
time.sleep(random.randint(2,5))
return r
def spider_list(list_url):
res = spider(list_url)
res_ = res.json()
for i in res_['data']['results']:
city = i['city']['items'][0]['name'] #城市
company = i['company']['name'] #公司
type = i['company']['type']['name'] #类型
size = i['company']['size']['name'] #规模
eduLevel = i['eduLevel']['name'] #教育程度
jobname = i['jobName'] #岗位名称
salary = i['salary'] #工资
workingExp = i['workingExp']['name'] #工作经验
welfare = i['welfare'] #待遇
number = i['number'][0]
detail_url = 'https://jobs.zhaopin.com/'+number+'.htm'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
response = requests.get(detail_url,headers=headers)
seletor = etree.HTML(response.text)
miaoshu = seletor.xpath('string(//div[@class="describtion__detail-content"])').strip()
label = ''
for i in miaoshu:
label = label + ' ' + i
item = [city,company,type,size,eduLevel,jobname,salary,workingExp,welfare,label]
csv_write(item)
# headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
# r = requests.get('https://jobs.zhaopin.com/CC811211310J00340821104.htm',headers=headers)
# r.text
for i in range(0, 6001, 60):
url = 'https://fe-api.zhaopin.com/c/i/sou?start=' + str(i) + '&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3&lastUrlQuery=%7B%22p%22:5,%22jl%22:%22489%22,%22kw%22:%22%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88%22,%22kt%22:%223%22%7D&at=17a95e7000264c3898168b11c8f17193&rt=57a342d946134b66a264e18fc60a17c6&_v=0.02365098&x-zp-page-request-id=a3f1b317599f46338d56e5d080a05223-1541300804515-144155'
spider_list(url)
