本篇文章使用 scrapy 框架爬取智联北京地区的 PHP 岗位招聘信息,将爬取到的数据保存到本地 MongoDB 数据库 和本地 zhilian_php.csv 文件中。
查看源码请移步 GitHub
爬取到的结果如下: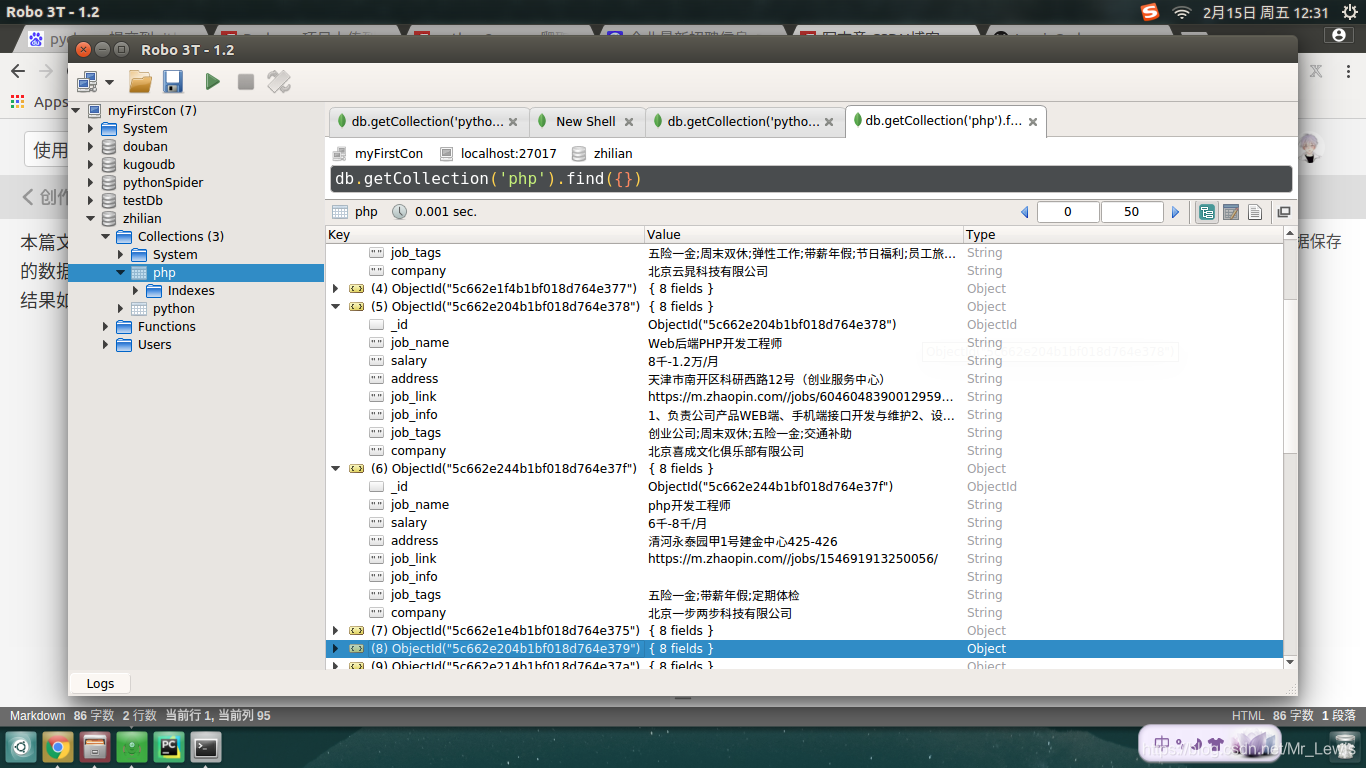

开发环境:
操作系统:Ubuntu 16.04
Python 版本:Python 3.5.2
Scrapy 框架版本:Scrapy 1.5.1
编辑器:PyCharm
最终的项目目录树为:
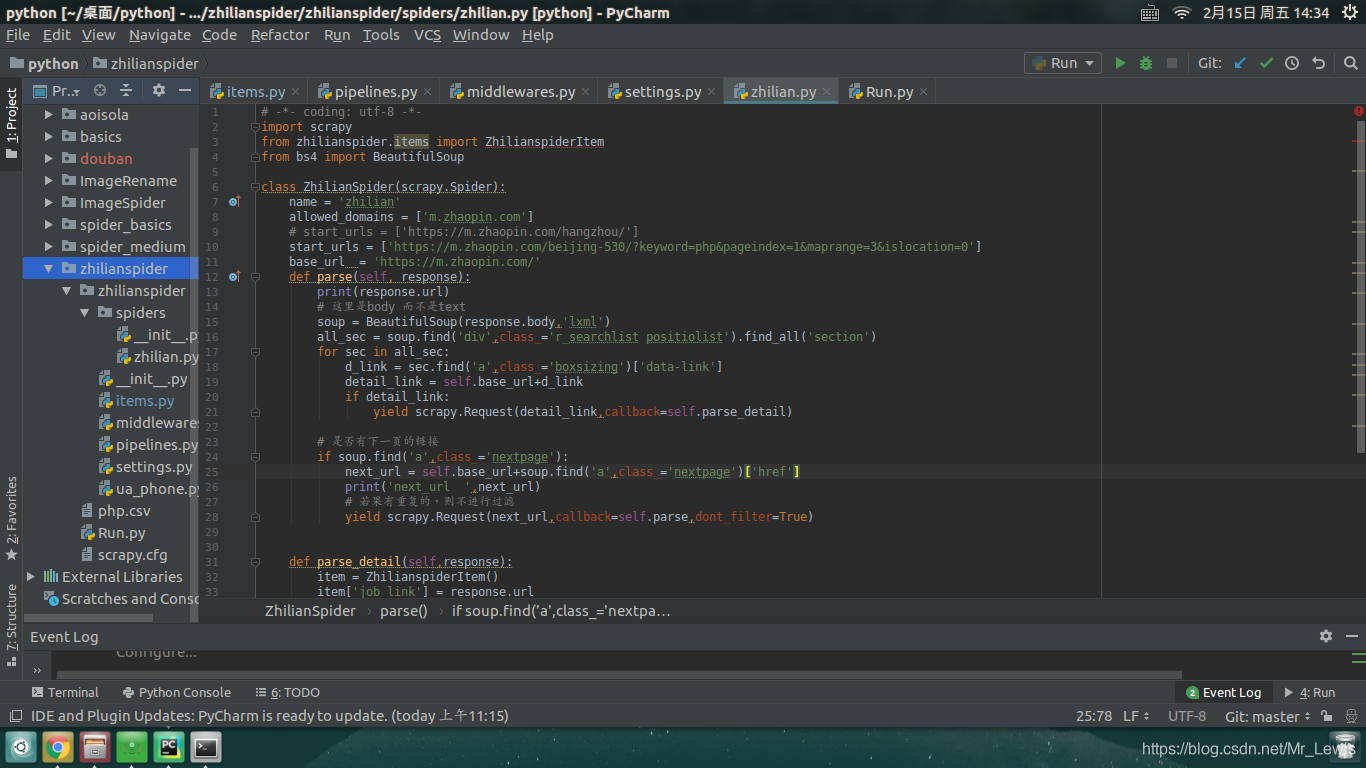
编写一个爬虫的基本步骤分为一下几步:
1.创建项目
在命令行运行以下两条命令:
命令一:创建一个爬虫项目
scrapy startproject zhilianspider
命令二:创建 spider 文件
scrapy genspider zhilian "https://m.zhaopin.com/beijing"
2.明确目标
明确自己想要收集该网站的什么信息。这里我们需要某个岗位的职位名称,职位链接,职位要求,职位待遇,公司名称,薪资,地址。明确自己需要什么信息之后,经它写入 items.py 文件进行数据结构化,代码如下:
import scrapy
class ZhilianspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
job_name = scrapy.Field() #职位名称
job_link = scrapy.Field() #职位链接
job_info = scrapy.Field() #职位要求
job_tags = scrapy.Field() #职位待遇
company = scrapy.Field() #公司名称
address = scrapy.Field() #公司地址
salary = scrapy.Field() #薪资
pass
3.编写爬虫
第一步“创建项目”中的命令二自动创建了 zhilian.py 文件,该文件的作用是用来解析网页收集数据,是整个爬虫项目的核心。
zhilian.py
import scrapy
from zhilianspider.items import ZhilianspiderItem
from bs4 import BeautifulSoup
class ZhilianSpider(scrapy.Spider):
name = 'zhilian'
allowed_domains = ['m.zhaopin.com']
# start_urls = ['https://m.zhaopin.com/hangzhou/']
start_urls = ['https://m.zhaopin.com/beijing-530/?keyword=php&pageindex=1&maprange=3&islocation=0']
base_url = 'https://m.zhaopin.com/'
def parse(self, response):
print(response.url)
# 这里是body 而不是text
soup = BeautifulSoup(response.body,'lxml')
all_sec = soup.find('div',class_='r_searchlist positiolist').find_all('section')
for sec in all_sec:
d_link = sec.find('a',class_='boxsizing')['data-link']
detail_link = self.base_url+d_link
if detail_link:
yield scrapy.Request(detail_link,callback=self.parse_detail)
# 是否有下一页的链接
if soup.find('a',class_='nextpage'):
next_url = self.base_url+soup.find('a',class_='nextpage')['href']
print('next_url ',next_url)
# 若果有重复的,则不进行过滤
yield scrapy.Request(next_url,callback=self.parse,dont_filter=True)
def parse_detail(self,response):
item = ZhilianspiderItem()
item['job_link'] = response.url
item['job_name'] = response.xpath('//*[@class="job-name fl"]/text()')[0].extract()
item['company'] = response.xpath('//*[@class="comp-name"]/text()')[0].extract()
item['address'] = response.xpath('//*[@class="add"]/text()').extract_first()
item['job_info'] = ''.join(response.xpath('//*[@class="about-main"]/p/text()').extract())
item['salary'] = response.xpath('//*[@class="job-sal fr"]/text()')[0].extract()
item['job_tags'] = ';'.join(response.xpath("//*[@class='tag']/text()").extract())
yield item
pass
4.存储数据
存储数据有两种办法,一种是存储到数据库,另一种是保存到本地文件。
1)保存到本地 MongoDB 数据库
pipelines.py
import pymongo
class ZhilianspiderPipeline(object):
#初始化,连接本地 MongoDB 数据库,指定数据库和集合
def __init__(self):
self.client = pymongo.MongoClient("localhost", connect=False)
db = self.client["zhilian"]
self.collection = db["php"]
#存入数据库
def process_item(self, item, spider):
content = dict(item) #将zhilian.py 收集到的数据转为字典类型
self.collection.insert(content)
print("###################已经存入MongoDB########################")
return item
def close_spider(self, spider):
self.client.close()
pass
2)保存到本地文件
在项目根目录运行 scrapy crawl zhilian -o zhilian_php.csv即可将爬取到数据存储到 zhilian_php.csv 文件中。也可保存为 json 格式的文件,将上面命令最后的 csv 改为 json 即可。
5.修改设置文件
修改 settings.py 文件,主要是关闭了 robots 协议,延时 0.5s 发生请求,修改 User-Agent 头,启用 SPIDER_MIDDLEWARES 和 ITEM_PIPELINES。最后的 settings.py 文件为:
BOT_NAME = 'zhilianspider'
SPIDER_MODULES = ['zhilianspider.spiders']
NEWSPIDER_MODULE = 'zhilianspider.spiders'
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.5
SPIDER_MIDDLEWARES = {
'zhilianspider.middlewares.UserAgentmiddleware': 400,
}
ITEM_PIPELINES = {
'zhilianspider.pipelines.ZhilianspiderPipeline': 300,
}
6.反爬处理
这里我们使用随机的 User-Agent 头来伪装成不同的浏览器访问。
1)新建一个 ua_phone.py 文件,保存收集到的 User-Agent 数据
ua_phone.py
ua_list = [
"HTC_Dream Mozilla/5.0 (Linux; U; Android 1.5; en-ca; Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.2; U; de-DE) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/234.40.1 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (Linux; U; Android 1.5; en-us; sdk Build/CUPCAKE) AppleWebkit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.1; en-us; Nexus One Build/ERD62) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 1.5; en-us; htc_bahamas Build/CRB17) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.1-update1; de-de; HTC Desire 1.19.161.5 Build/ERE27) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Sprint APA9292KT Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 1.5; de-ch; HTC Hero Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; ADR6300 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 2.1; en-us; HTC Legend Build/cupcake) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 1.5; de-de; HTC Magic Build/PLAT-RC33) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1 FirePHP/0.3",
"Mozilla/5.0 (Linux; U; Android 1.6; en-us; HTC_TATTOO_A3288 Build/DRC79) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 1.0; en-us; dream) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2",
"Mozilla/5.0 (Linux; U; Android 1.5; en-us; T-Mobile G1 Build/CRB43) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari 525.20.1",
"Mozilla/5.0 (Linux; U; Android 1.5; en-gb; T-Mobile_G2_Touch Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.0; en-us; Droid Build/ESD20) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Droid Build/FRG22D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 2.0; en-us; Milestone Build/ SHOLS_U2_01.03.1) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.0.1; de-de; Milestone Build/SHOLS_U2_01.14.0) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2",
"Mozilla/5.0 (Linux; U; Android 0.5; en-us) AppleWebKit/522 (KHTML, like Gecko) Safari/419.3",
"Mozilla/5.0 (Linux; U; Android 1.1; en-gb; dream) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2",
"Mozilla/5.0 (Linux; U; Android 2.0; en-us; Droid Build/ESD20) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.1; en-us; Nexus One Build/ERD62) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Sprint APA9292KT Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; ADR6300 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 2.2; en-ca; GT-P1000M Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 3.0.1; fr-fr; A500 Build/HRI66) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2",
"Mozilla/5.0 (Linux; U; Android 1.6; es-es; SonyEricssonX10i Build/R1FA016) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 1.6; en-us; SonyEricssonX10i Build/R1AA056) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
]
2)在 middlewares.py 文件中新增一个类
middlewares.py
注意在文件开头导入 random 模块和 ua_phone.py 文件
import random
from zhilianspider.ua_phone import ua_list
...
...
...
class UserAgentmiddleware(object):
def process_request(self, request, spider):
agent = random.choice(ua_list)
request.headers['User-Agent'] = agent
7.开始爬取
有两种方法启动爬虫
1)在项目根目录下打开 Ubuntu 命令行,运行 scrapy crawl zhilian
2)新建一个 Run.py 文件,用来运行爬虫(推荐),在编辑器中就可运行爬虫,方便高效。
Run.py
from scrapy import cmdline
cmdline.execute('scrapy crawl zhilian'.split())
然后只需静静地等待,我们的数据库中便会整齐的躺好许多关于PHP岗位招聘信息。如果想要将爬取的数据保存到本地文件,在项目根目录下运行 scrapy crawl zhilian -o zhilian_php.csv即可。