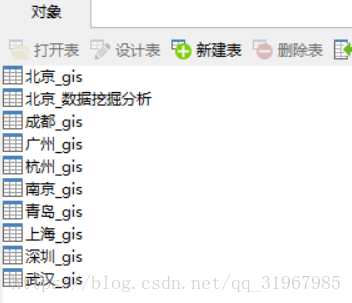
开发环境
win7+,python3.4+
pymysql库,安装:pip3 install pymysql
selenium库,火狐浏览器56.0版本,geckodriver.exe,selenium知识点
MySQL5.5数据库,Navicat图形化界面
爬取步骤
1.分析智联招聘网,获取网页信息
打开“https://www.zhaopin.com/”选择城市“北京”,输入“GIS”点击“搜工作”网页将显示与“GIS”相关的北京地区的招聘信息
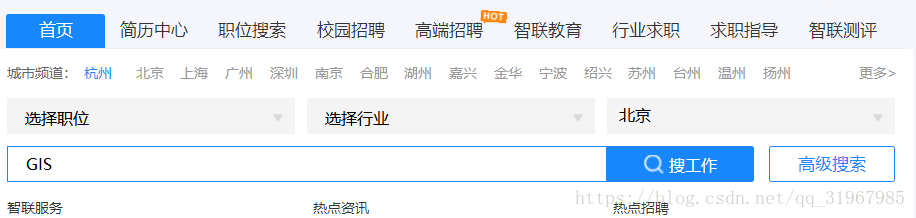
F12进去开发者后台“城市”“工作输入”“搜工作按钮”的html元素分别为“id=JobLocation”,“id=KeyWord_kw2”,“class=dosearch”(selenium知识点)。根据这些可以自动转入下个页面:
代码一:
def get_main_page(keyword, city): fox = webdriver.Firefox() url = 'https://www.zhaopin.com/' fox.get(url) time.sleep(1) jl = fox.find_element_by_id('JobLocation') jl.clear() jl.send_keys(city) zl = fox.find_element_by_id('KeyWord_kw2') zl.clear() zl.send_keys(keyword) sj = fox.find_element_by_class_name('doSearch').click() time.sleep(3)

2.分析招聘信息,获取信息
查看源代码找到各个部分的信息具体如下
def get_everypage_info(fox, keyword, city): fox.switch_to_window(fox.window_handles[-1]) tables = fox.find_elements_by_tag_name('table')
for i in range(0, len(tables)): if i == 0: ''' row = ['职位名称', '公司名称', '工作地点', '公司规模', '工作经验', '平均月薪', '学历要求', '职位描述'] information.append(row) ''' else: address, develop, jingyan, graduate, require = " ", " ", " ", " ", " " job = tables[i].find_element_by_tag_name('a').text company = tables[i].find_element_by_css_selector('.gsmc a').text salary = tables[i].find_element_by_css_selector('.zwyx').text spans = tables[i].find_elements_by_css_selector('.newlist_deatil_two span') for j in range(0, len(spans)): if "地点" in spans[j].get_attribute('textContent'): address = (spans[j].get_attribute('textContent'))[3:] elif "公司规模" in spans[j].get_attribute('textContent'): develop = (spans[j].get_attribute('textContent'))[5:] elif "经验" in spans[j].get_attribute('textContent'): jingyan = (spans[j].get_attribute('textContent'))[3:] elif "学历" in spans[j].get_attribute('textContent'): graduate = (spans[j].get_attribute('textContent'))[3:] require = (tables[i].find_element_by_css_selector('.newlist_deatil_last').get_attribute('textContent'))[8:]
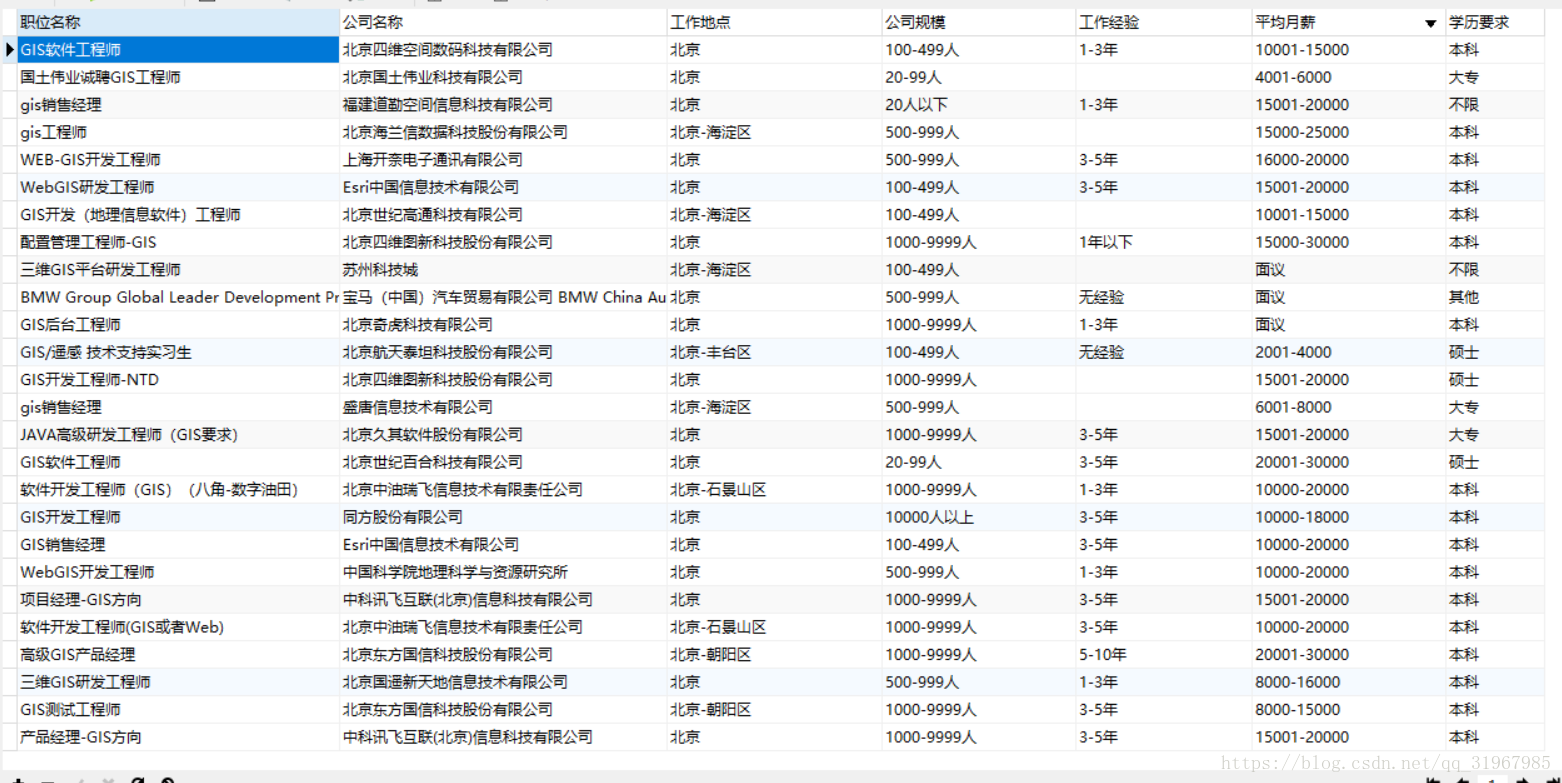
以上代码得到每一页的每个招聘公司的信息:职位名称', '公司名称', '工作地点', '公司规模', '工作经验', '平均月薪', '学历要求', '职位描述'
3.信息存入MySQL数据库
连接mysql并且创建新表,将数据逐行写入数据库,同时将“职位描述”写入一个txt文件
连接mysql:
table_name = city + '_' + keyword conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', passwd='', db='python', charset='utf8') cursor = conn.cursor()
创建新表:
sql = """CREATE TABLE IF NOT EXISTS %s( 职位名称 CHAR(100), 公司名称 CHAR(100), 工作地点 CHAR(100), 公司规模 CHAR(100), 工作经验 CHAR(100), 平均月薪 CHAR(100), 学历要求 CHAR(100) )default charset=UTF8""" % (table_name) cursor.execute(sql)
将信息分别写入mysql和txt:
insert_row = ('insert into {0}(职位名称,公司名称,工作地点,公司规模,工作经验,平均月薪,学历要求) VALUES(%s,%s,%s,%s,%s,%s,%s)'.format(table_name)) insert_data = (job, company, address, develop, jingyan, salary, graduate) cursor.execute(insert_row, insert_data) conn.commit() with open('%s职位描述.txt' % (table_name), 'a', encoding='utf-8') as f: f.write(require)
4.招聘信息页面跳转

“下一页”按钮的html元素通过下面代码找到并跳转:
count = 0 while count <= 10: try: next_page = fox.find_element_by_class_name('pagesDown-pos').click() break except: time.sleep(8) count += 1 continue if count > 10: fox.close() else: time.sleep(1) get_everypage_info(fox, keyword, city)注意:此处十分重要,while循环用于判断是否到了最后一页,如果进行10次“next_page = fox.find_element_by_class_name('pagesDown-pos').click()”仍然没反应,就会跳出循环进去下面的if,关闭浏览器;如果“next_page = fox.find_element_by_class_name('pagesDown-pos').click()”有反应break也会跳出while进入下面“else”进而跳转到下一页
5.“main”设置进行城市循环
if __name__ == "__main__": citys = ['上海', '深圳', '广州', '武汉', '杭州', '南京', '成都', '青岛'] # '北京', 已爬取 job = '数据挖掘分析' for city in citys: print(" ") get_main_page(job, city)
每个城市的job信息爬取完了自动进行列表中下个城市信息爬取
6.注意和问题
(1)创建mysql表问题一:定义表的编码形式“default charset=UTF8”,不然输入写入时报错
(2)数据写入mysql表问题二:'insert into {0}(职位名称,公司名称,工作地点,公司规模,工作经验,平均月薪,学历要求) VALUES(%s,%s,%s,%s,%s,%s,%s)'.format(table_name)处要先将表名带入,insert 语句中表名和列名都不能带单引号和双引号,提前写入可以避免。和值一起写入时默认代了引号;
insert_row = ('insert into {0}(职位名称,公司名称,工作地点,公司规模,工作经验,平均月薪,学历要求) VALUES(%s,%s,%s,%s,%s,%s,%s)'.format(table_name))
insert_data = (job, company, address, develop, jingyan, salary, graduate)
cursor.execute(insert_row, insert_data)
(3)time.sleep()根据网速和电脑性能而定,上佳的时间可以设置短;不佳的就要适当延长时间设置,不让代码将捕捉不到html元素
完整代码:
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time import pymysql def get_main_page(keyword, city): fox = webdriver.Firefox() url = 'https://www.zhaopin.com/' fox.get(url) time.sleep(1) jl = fox.find_element_by_id('JobLocation') jl.clear() jl.send_keys(city) zl = fox.find_element_by_id('KeyWord_kw2') zl.clear() zl.send_keys(keyword) sj = fox.find_element_by_class_name('doSearch').click() time.sleep(3) get_everypage_info(fox, keyword, city) def get_everypage_info(fox, keyword, city): fox.switch_to_window(fox.window_handles[-1]) tables = fox.find_elements_by_tag_name('table') table_name = city + '_' + keyword conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', passwd='', db='python', charset='utf8') cursor = conn.cursor() sql = """CREATE TABLE IF NOT EXISTS %s( 职位名称 CHAR(100), 公司名称 CHAR(100), 工作地点 CHAR(100), 公司规模 CHAR(100), 工作经验 CHAR(100), 平均月薪 CHAR(100), 学历要求 CHAR(100) )default charset=UTF8""" % (table_name) cursor.execute(sql) for i in range(0, len(tables)): if i == 0: ''' row = ['职位名称', '公司名称', '工作地点', '公司规模', '工作经验', '平均月薪', '学历要求', '职位描述'] information.append(row) ''' else: address, develop, jingyan, graduate, require = " ", " ", " ", " ", " " job = tables[i].find_element_by_tag_name('a').text company = tables[i].find_element_by_css_selector('.gsmc a').text salary = tables[i].find_element_by_css_selector('.zwyx').text spans = tables[i].find_elements_by_css_selector('.newlist_deatil_two span') for j in range(0, len(spans)): if "地点" in spans[j].get_attribute('textContent'): address = (spans[j].get_attribute('textContent'))[3:] elif "公司规模" in spans[j].get_attribute('textContent'): develop = (spans[j].get_attribute('textContent'))[5:] elif "经验" in spans[j].get_attribute('textContent'): jingyan = (spans[j].get_attribute('textContent'))[3:] elif "学历" in spans[j].get_attribute('textContent'): graduate = (spans[j].get_attribute('textContent'))[3:] require = (tables[i].find_element_by_css_selector('.newlist_deatil_last').get_attribute('textContent'))[8:] row = [job, company, address, develop, jingyan, salary, graduate, require] insert_row = ('insert into {0}(职位名称,公司名称,工作地点,公司规模,工作经验,平均月薪,学历要求) VALUES(%s,%s,%s,%s,%s,%s,%s)'.format(table_name)) insert_data = (job, company, address, develop, jingyan, salary, graduate) cursor.execute(insert_row, insert_data) conn.commit() with open('%s职位描述.txt' % (table_name), 'a', encoding='utf-8') as f: f.write(require) print('此页已抓取···') conn.close() count = 0 while count <= 10: try: next_page = fox.find_element_by_class_name('pagesDown-pos').click() break except: time.sleep(8) count += 1 continue if count > 10: fox.close() else: time.sleep(1) get_everypage_info(fox, keyword, city) if __name__ == "__main__": citys = ['上海', '深圳', '广州', '武汉', '杭州', '南京', '成都', '青岛'] # '北京', 已爬取 job = '数据挖掘分析' for city in citys: print(" ") get_main_page(job, city)
最后获取的输入如图