import csv
from pandas import json
import requests
fp = open('智联招聘.csv', 'wt', newline='', encoding='UTF-8')
writer = csv.writer(fp)
writer.writerow(('职位', '薪资', '学历','工作经验', '公司','公司人数', '地区', '福利', '链接'))
def geturl(city, keyword,working,education,companyType,page):
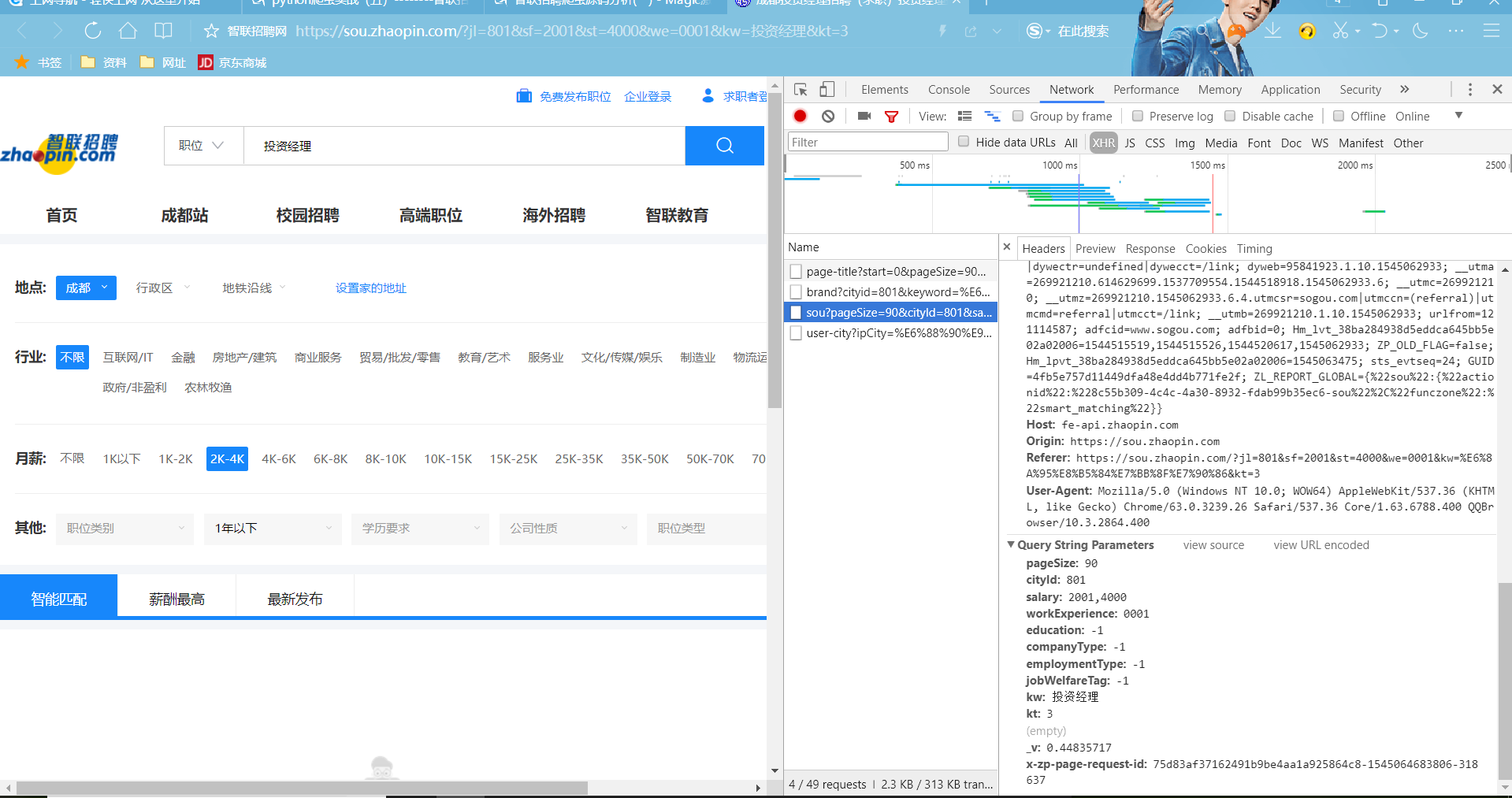
paras = {
'start': '-1',
'pageSize': page,
'cityId': city,
'workExperience': working,
'education': education,
'companyType': companyType,
'employmentType': '-1',
'jobWelfareTag': '-1',
'kw': keyword,
'kt': '3',
'_v': '0.93300214',
'x-zp-page-request-id': '6bda060a5be94fe5becd5af3465c33c4-1544103273892-946749'
}
url = 'https://fe-api.zhaopin.com/c/i/sou'
result = json.loads(requests.get(url, params=paras).text)
return result
def get_data(result):
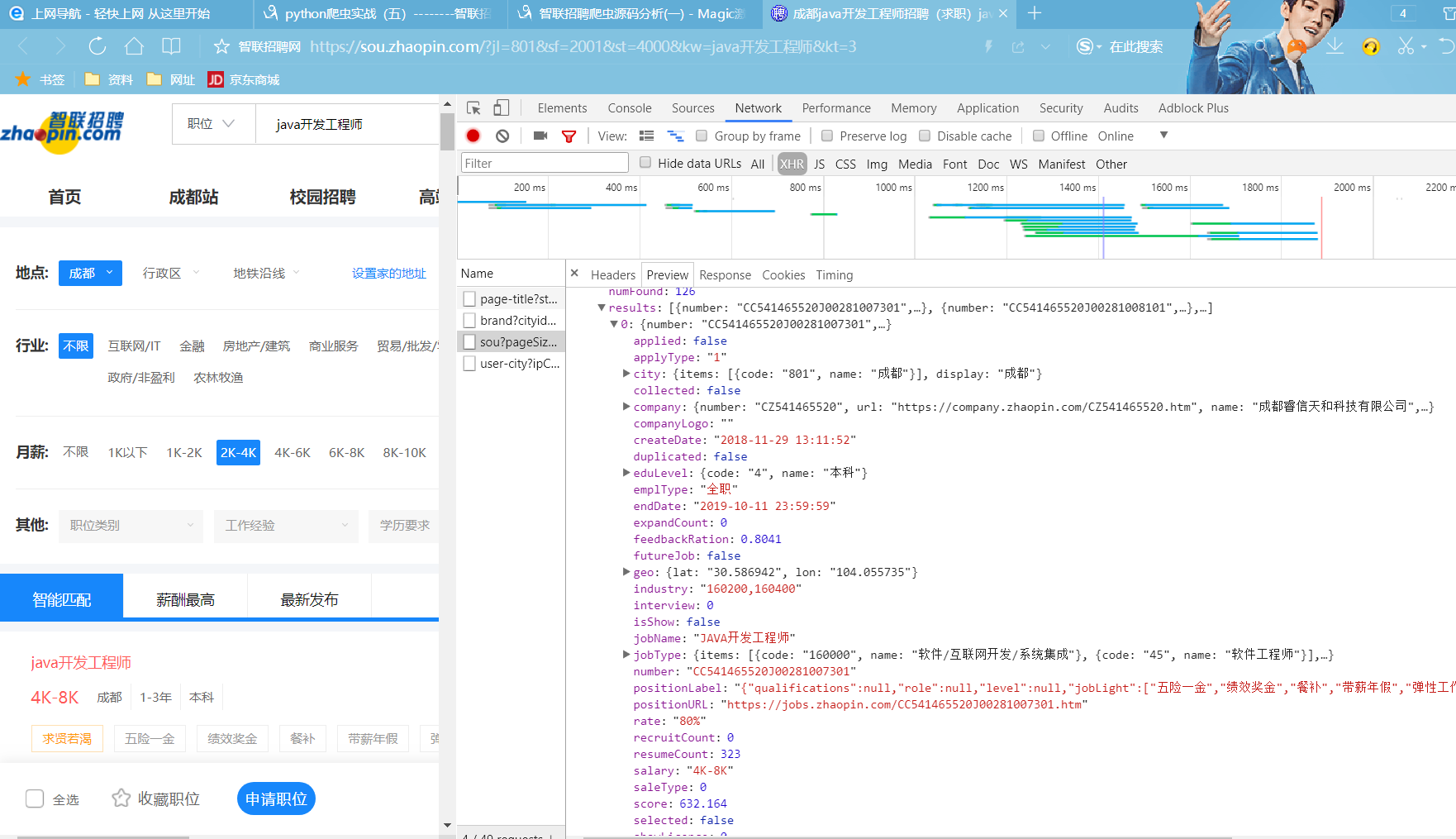
for item in result['data']['results']:
jobname = item['jobName']
companyname = item['company']['name']
companynumber = item['company']['size']['name']
xueli = item['eduLevel']['name']
salary = item['salary']
didian = item['city']['display']
workingExp = item['workingExp']['name']
url = item['positionURL']
fuli = item['welfare']
writer.writerow((jobname,salary,xueli,workingExp,companyname,companynumber,didian,fuli,url))
if __name__ == '__main__':
city = input("请输入工作的城市:")
keyword = input("请输入你要找的工作:")
working = input('工作经验:')
companyType = input('公司类型:')
education = input('学历要求:')
tatol = eval(input("共需查找几条符合条件的信息:"))
result = geturl(city,keyword,working,education,companyType,tatol)
get_data(result)
|