这套程序基于python3 ,使用requests和re正则表达式,只需要将程序保存为.py文件后,即可将抓取到的数据保存到指定路径的Excel文件中。程序在终端中启动,启动命令:
#python3 文件名.py 关键字 城市
python3 zhilian.py python 杭州
代码如下:
# coding:utf-8
import requests
import re
import xlwt
import sys,os
workbook = xlwt.Workbook(encoding='utf-8')
booksheet = workbook.add_sheet('Sheet 1', cell_overwrite_ok=True)
class ZhiLian(object):
def __init__(self):
self.start_url = 'https://m.zhaopin.com/{}/?keyword={}&pageindex={}&maprange=3&islocation=0&order=4'
self.headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Mobile Safari/537.36"
}
self.test_url = '<section class="job-list.*?".*?>.*?<div class="job-name fl ">(.*?)</div>.*?<div class="fl">(.*?)</div>.*?<div class="comp-name fl">(.*?)</div>.*?<span class="ads">(.*?)</span>.*?<div class="time fr">(.*?)</div>'
self.select_city_url = 'https://m.zhaopin.com/searchjob/selectcity'
self.test_city = ' <a data-code="(.*?)" href="/(.*?)/">(.*?)</a>'
def parse_url(self, url):
'''发送请求'''
response = requests.get(url, headers=self.headers)
return response.content.decode()
def get_data(self, test_url, content):
'''获取数据'''
content_list = re.findall(test_url, content, re.S)
return content_list
def get_content(self, content_list, DATA):
'''提取数据'''
for content in content_list:
DATA.append((content[0], content[1], content[2], content[3], content[4]))
def save_content(self, DATA, city, key_words):
'''保存到excel'''
for i, row in enumerate(DATA):
for j, col in enumerate(row):
booksheet.write(i, j, col)
#判断保存的路径,如果和我的路径不一样,会自动保存到当前程序文件所在目录
if(os.path.isdir('/home/itcast/Desktop/')):
workbook.save('/home/itcast/Desktop/{}_{}.xls'.format(city,key_words))
else:
workbook.save('{}_{}.xls'.format(city, key_words))
def select_city(self, url, search_city):
'''选择城市,返回城市代码'''
city_dict = {}
city_code = None
r = requests.get(url, headers=self.headers)
content = r.content.decode()
city_content = re.findall(self.test_city, content, re.S)
# print(city_content)
# print(len(city_content))
# 构造一个字典存储城市信息
for city in city_content:
# '566': ['tangshan', '唐山']
city_dict[city[0]] = [city[1], city[2]]
# print(len(city_dict))
for keys, value in city_dict.items():
if search_city == value[1]:
city_code = value[0] + '-' + keys
# print(city_code)
return city_code
def deal_city(self, city):
'''处理城市信息'''
city_code = self.select_city(self.select_city_url, city)
if city_code == None:
print("查找城市不存在,请重试")
sys.exit()
return city_code
def run(self, city, key_words):
# 1.start_url
# 2.发送请求,获取响应
i = 1
DATA = [('岗位', '月薪', '公司', '城市', '发布时间')]
city_code = self.deal_city(city)
while True:
url = self.start_url.format(city_code, key_words, i)
content = self.parse_url(url)
content_list = self.get_data(self.test_url, content)
self.get_content(content_list, DATA)
# 保存数据
self.save_content(DATA, city, key_words)
# 判断是否还有数据 限制保存最大页数
if (len(content_list) == 0 or i>100):
print("保存完成,共{}页数据".format(i - 1))
break
print("正在保存第{}页数据".format(i))
i += 1
if __name__ == '__main__':
key_words = sys.argv[1]
city = sys.argv[2]
zhilian = ZhiLian()
zhilian.run(city, key_words)
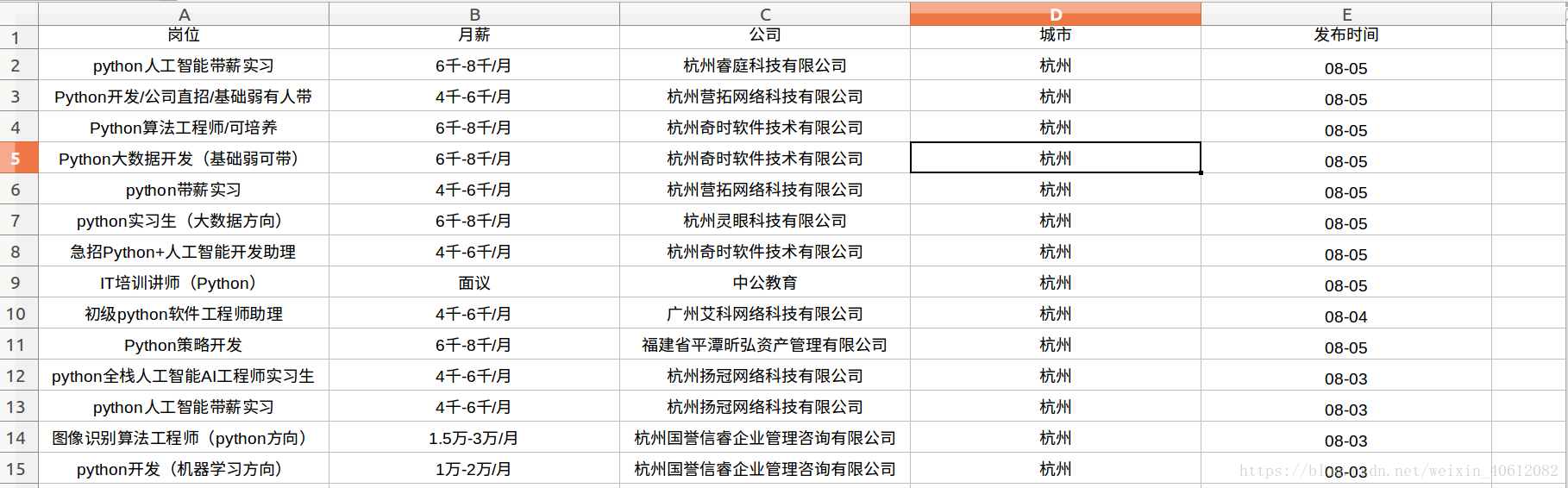
爬取结果如下: