Gated Self-Matching Networks for Reading Comprehension and Question Answering论文阅读笔记
在看完上一篇《Attention-over-Attention Neural Networks for Reading Comprehension》之后,笔者昨天看了这篇由清华大学和微软实验室发表在2017ACL的论文,两篇文论都在ACL上收录,不过AoA似乎更早一点,2016在arxiv上就发出。AoA任务是在完形填空上进行,此篇论文是基于Stanford的SQuAD数据集。本文就以下4个部分进行讨论:
- Motivation
- Model
- Experiment
- Discussion
1、Motivation
这篇文章主要从gate-attention和self-matching两个方面对阅读理解任务进行阐述。
- 其中的gate-attention是在attention的基础上增加一个gate,融合了含有问题的passage表达 。
- 而后又提出了self-matching的注意力机制,即将 做一个self-attention和gate的组合,得到最终表达 。这样做的好处是因为gate-attention得到的表达往往是非常有限的(为什么有限下文提到),会忽略窗口之外的一些关键信息。而且在SQuAD数据集中,文章和问题之间也会存在同义词或者语法差异性。文章的信息能够很好的去预测这个答案。
2、Model Structure
模型结构一共包含四部分:
- 输入表示
- Gate-attention
- self-matching
- 输出预测
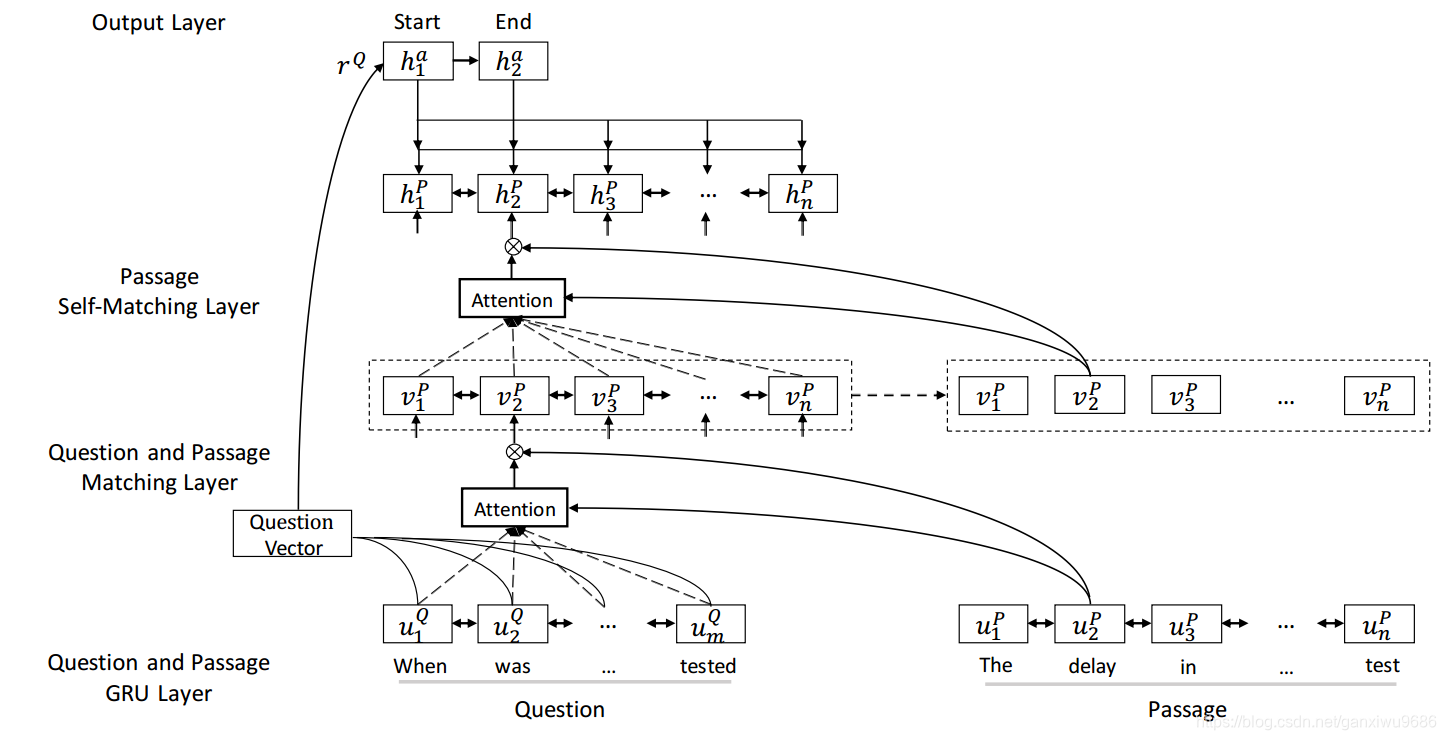
输入表示
首先把Q和P中的词转为词向量
和字符向量
和,其中词向量经过预训练,字符向量经过RNN得到最后一个状态作为输入一部分,这部分随任务同时训练。再将这两个向量拼接,经过一个双向RNN,得到输入,即图中对应的
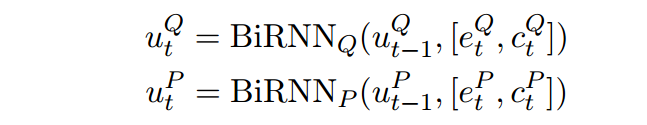
Gate-attention
首先做attention,将P中的每一个词分别和Q中的所有词做一个注意力计算,得到表示
。
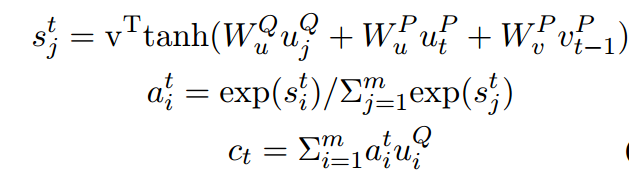
之前 Rocktaschel et al. (2015)的做法是,直接将
过一个RNN,即下公式: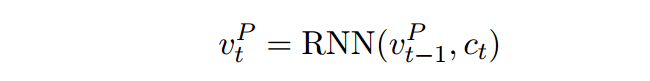
Wang and Jiang (2016a)的计算方式额外引入了
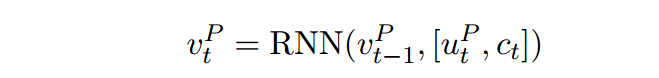
此文为了表示文章中的部分词和问题的相关性,引入门函数,得到
的新的表达,聚焦于当前词和问题的相关程度:

self-matching
gate-attention得到的表达往往是非常有限的,因为它是文章P中的每个词与Q的一个attention计算,没有专门考虑文章之间的词的关系,所以很自然作者在得到了包含Q的文档表达
之后,对其做了一个self-attention,并且同理经过一个门函数。
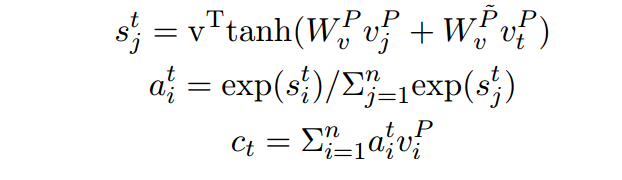
最后得到
,即抽取了包含问题表达的文章整体的证据。
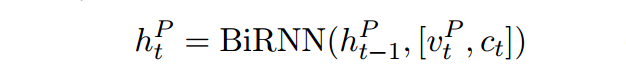
输出预测
用指针网络计算出答案所在的位置
和
,
表示的是指针网络最后一个隐藏状态(我认为就是
的计算是经过RNN并且只取最后一个state):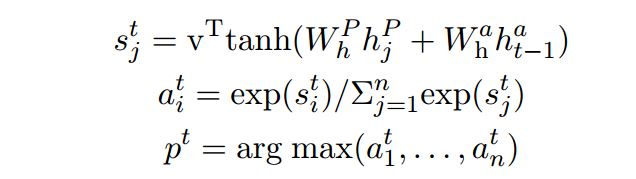
其中
的计算计算公式如下:
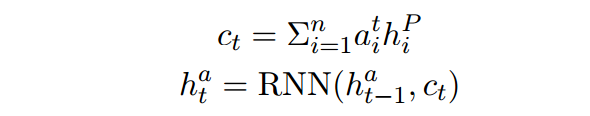
这里文章又说当预测开始位置的时候,
表示的RNN的初始状态,个人理解就是
,用
来表示,计算如下,
是定义的一个参数(类似文本分类中用于attention计算),共同训练: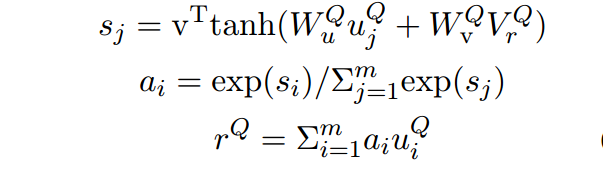
训练时则希望最大似然概率分布。
3、Experiment
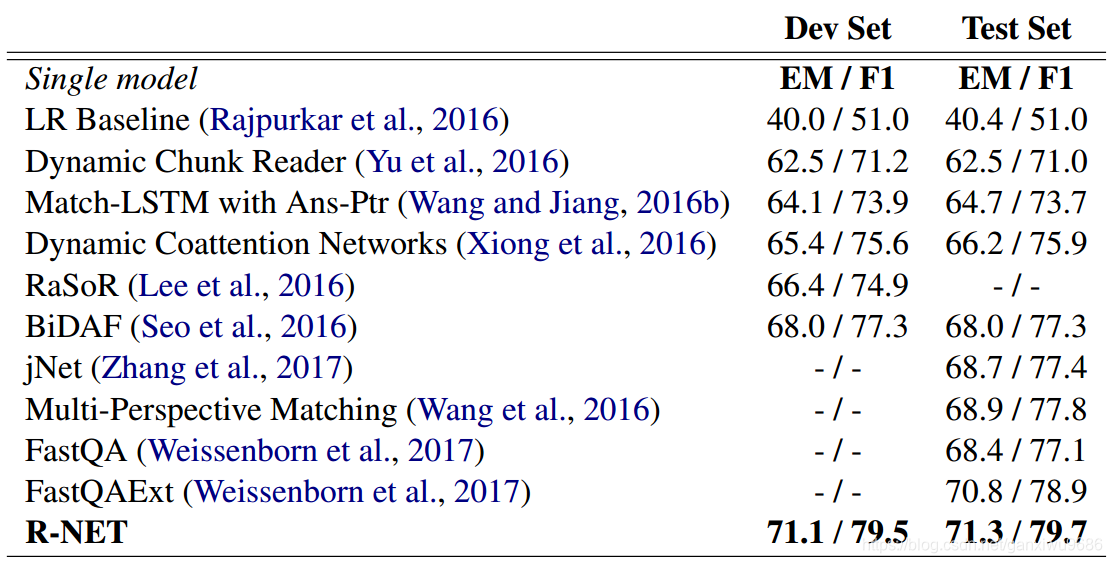
作者在单模型和集成模型上都进行了实验,可以看到在当时达到了最好对的效果。
表2显示了模型和其他方法的开发和测试集的精确匹配EM值和F1分数。集合模型由20个具有相同架构和超参数的训练组成。 在测试时,我们在每个问题的20次运行中选择具有最高置信度分数的答案。 我们可以看到,我们的方法明显优于单一模型和集合模型。

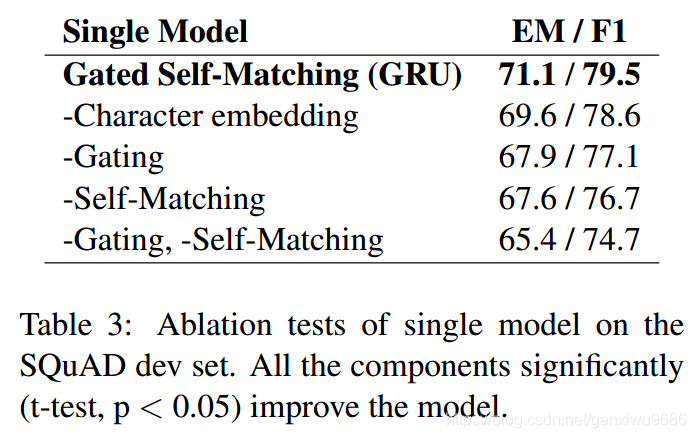
也有单独去除某些组件,模型效果的变化示意,基于注意力的门循环网络(GARNN)和自匹配注意机制对最终结果做出了积极贡献。 去除自匹配导致3.5%EM下降,这表明该段落中的信息起着重要作用。
4、Discussion
- 优点:
- 利用门函数,对问题和文章的表示进一步融合
- 引入self-matching注意力机制,在融合完问题表示之后对文章进行self-matching,从文中获取证据。
- 缺点:
- 对于长答案的问题来说,效果有明显的下降
- 设计到原因why的问题,效果也下降较为明显,说明推理在阅读理解任务中还是有很大的挑战
如有问题,欢迎大家批评讨论!