1. 论文思想
在深度学习任务中为了获得最终结果的高精度,增加网络的层数和宽度是直接有效的办法。但是增加这些改变会造成如下的后果:
(2)参数会使得网络的参数量级急剧攀升,计算的复杂度也会急剧变大;
(2)同时会存在梯度消失或是爆炸,模型难以训练的问题;
(3)而且如此巨大的参数量在训练集欠缺的情况下会使得网络过拟合情况严重等情况。
解决上述两个缺点(1)与(3)的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
GoogleNet主要的思想便是:从现有的深度网络结构中寻找到最优的局部网络结构。具体来讲就主要体现为如下两个方面:
(1)深度:GoogleNet的层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,GoogleNet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
(2)宽度:增加了多种核 1x1,3x3,5x5,还有直接max pooling的,但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。此外在网络后端的全连接层部分,并没有采用传统网络的多个全连接层连接的结构,而是采用了对卷积层输出Average Pooling再使用一个全连接映射到1000类的做法,这样极大减少了网络参数的数量,在论文中提到采用该结构之后Top-1的准确率提升了
。
2. 论文中的实现细节
2.1 Inception结构优化
在GoogleNet中采用了Inception结构,也就是使用多种卷积核与Max Pooling组合起来的结构,其结构如下:
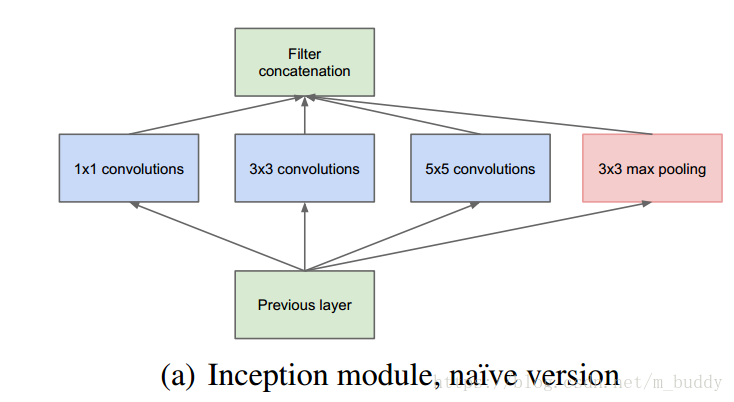
但是这样的连接会存在很大的计算量的问题,例如:假设Previous Layer的输出通道数为128,后面接的
大小的卷积有64个,那么所需的参数就是
,若是采用
的卷积在中间作为连接的话所需要的参数就变成了
,这样一来参数就直接变为了原来的0.15倍,因而极大减少了参数的数量。因而在GoogleNet中使用的Inception结构为:
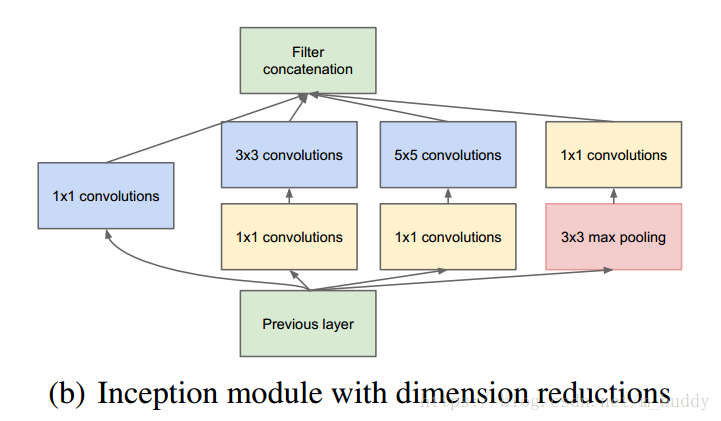
其中加入
大小的卷积最直接的好处就是减少了网络中参数的个数。
2.2 添加辅助损失(auxiliary loss)
在GoogleNet中在中部添加了两个辅助损失函数,这使得分类器在低层次特征的时候就对其进行分类,由于辅助函数的引入增加向后传播的梯度信号,并且能够提供额外的正则化。
3. GoogleNet网络
按照上述的思想进行网络设计,最后得到GoogleNet的网络结构为:
![[Googlenet网络结构图片]](https://img-blog.csdn.net/20180827223837885?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21fYnVkZHk=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
对上图做如下说明:
(1)显然GoogLeNet采用了Inception模块化(9个)的结构,共22层,方便增添和修改;
(2)网络最后采用了average pooling来代替全连接层,想法来自NIN,参数量仅为AlexNet的1/12,性能优于AlexNet,
事实证明可以将TOP-1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便finetune;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
(5)上述的GoogLeNet的版本成它使用的Inception V1结构。后面的V2是使用两个
的卷积替换原来
的卷积;V3便是使用了
和
的卷积去替换原来的
的卷积,进而减少参数数量。