前言
好久不写爬虫了,深夜想买房 不~我不想。
我就是去看了一下上海的新楼盘信息,明白一个道理…“现在我买不起(╬ ̄皿 ̄)”!
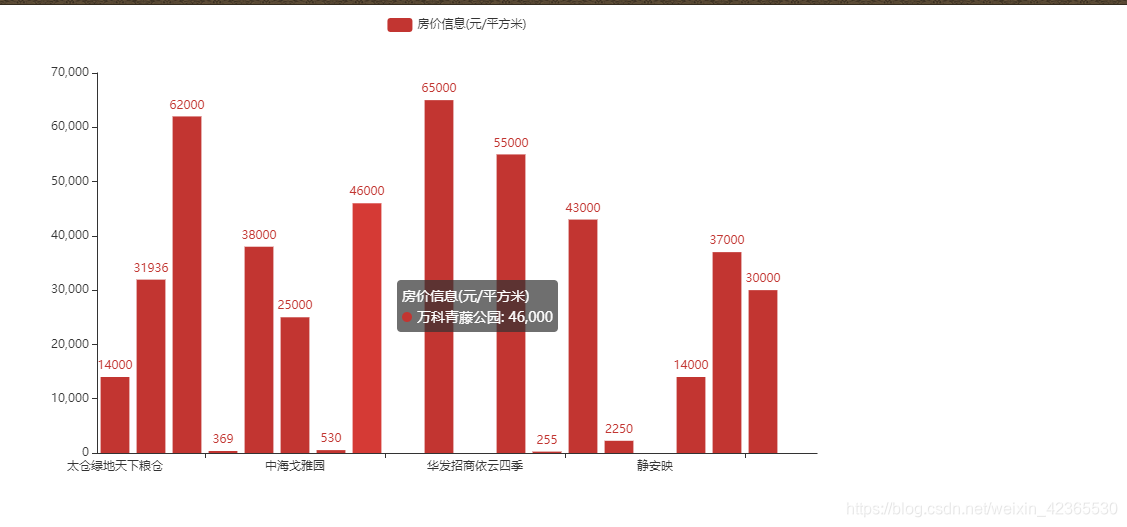
运行结果
先看一下运行后的效果,有兴趣再往下看~
虫子开始了
目标网址:https://sh.newhouse.fang.com/house/s/b91/?ctm=1.sh.xf_search.page.1
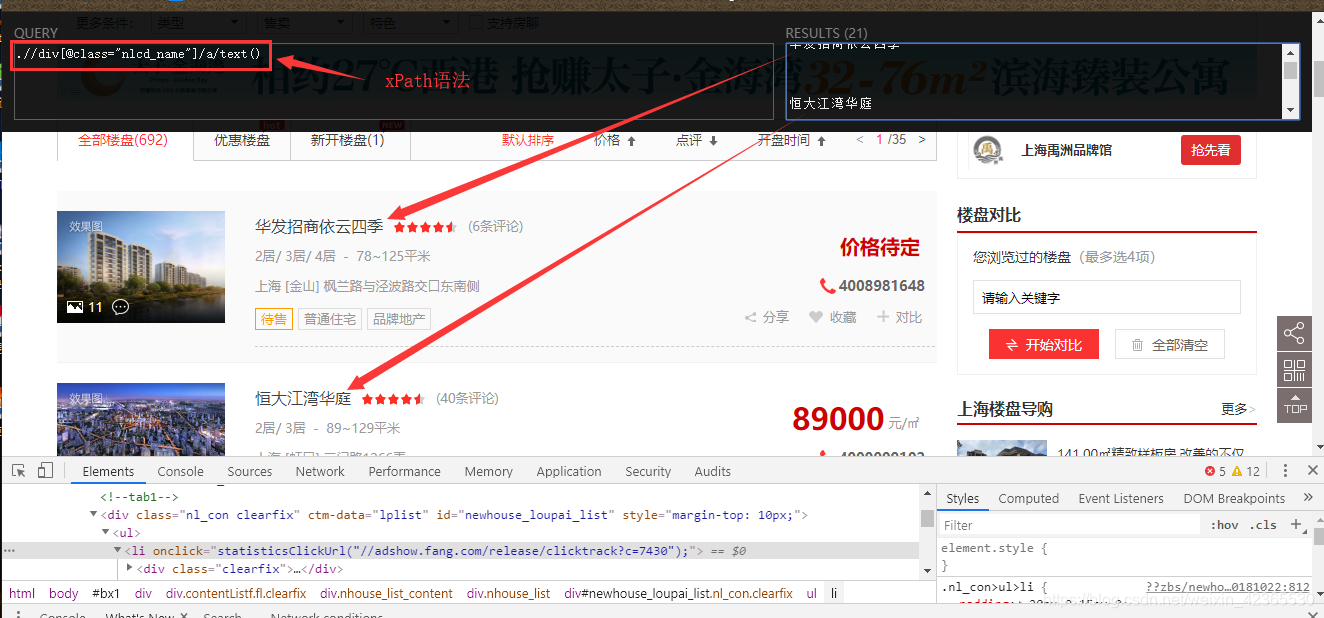
如下所示,我们需要拿到每个楼盘的name和价格
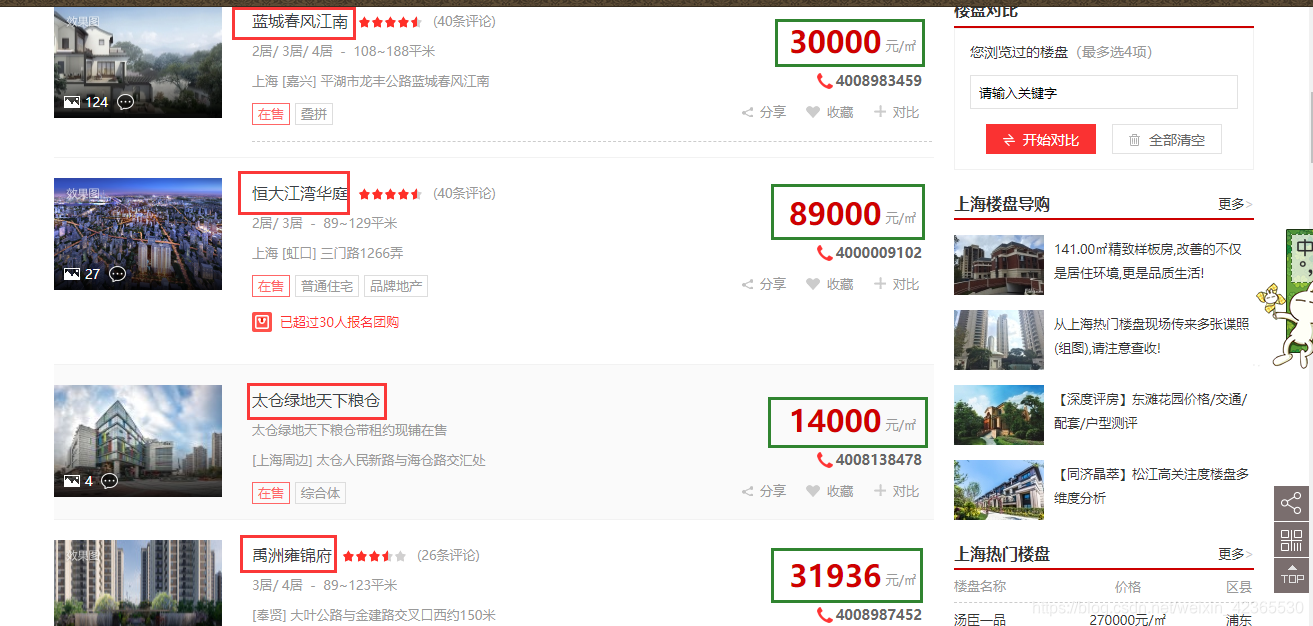
本来想像下面那样用查找请求的数据文件获取数据的
懒得找了,利用HTML解析库lxml结合xPath语法(xPath教程)很方便就拿到网页上的数据了
如下,.//div[@class=“nlcd_name”]/a/text() 拿到当前网页上所有楼盘的name
.//div[@class=“nhouse_price”]/span/text() 可拿到当前网页上所有的楼盘价格
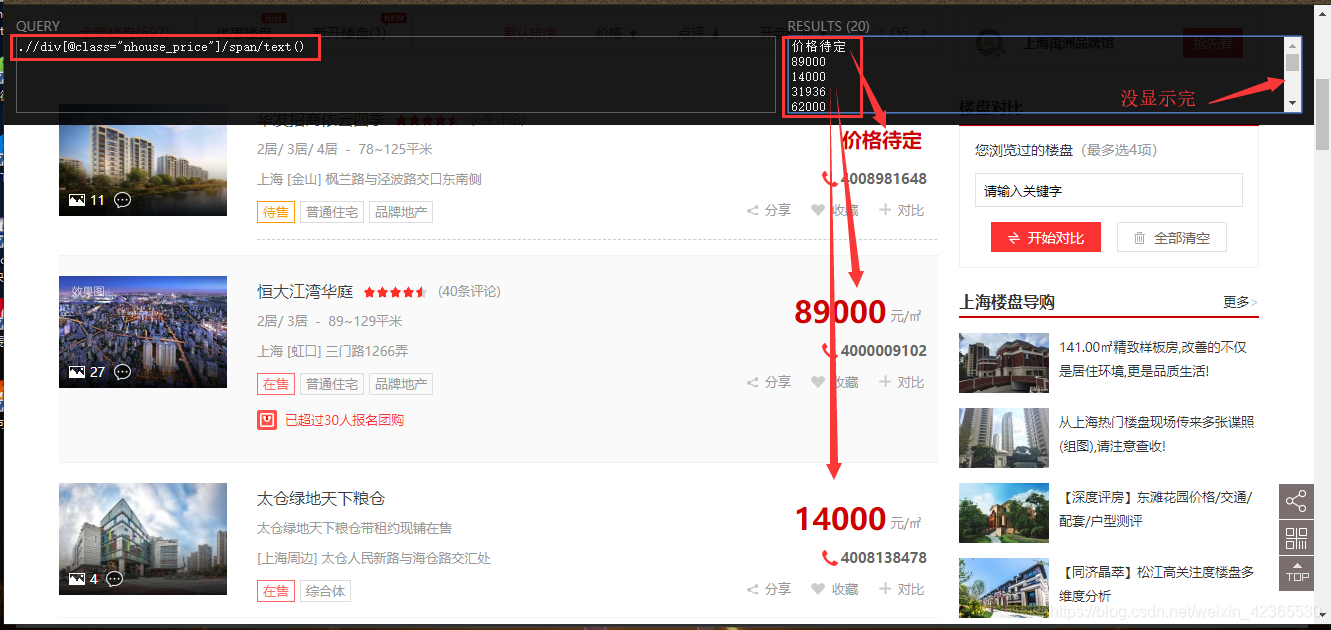
通过两个xPath语法即可拿到需要的数据,将两类数据分别保存在两个列表中,为后面数据可视化做准备(分别作为提供横、纵坐标的数据)
# .//div[@class="nlcd_name"]/a/text()拿到的是所有的数据,strip()切割后用循环来遍历每次取第一个
name = xpath('.//div[@class="nlcd_name"]/a/text()')[0].strip()
names.append(name) #将name添加至names数组中
price = i.xpath('.//div[@class="nhouse_price"]/span/text()')[0]
prices.append(price)
得到names[]和prices[]两个列表数据后,使用pyecharts来绘制柱状图
from pyecharts.charts import Bar # pip install pyecharts
bar = Bar() # Bar:柱状
bar.add_xaxis(names)
bar.add_yaxis('房价信息(元/平方米)',prices)
bar.render('D:\python_data\数据可视化\\fangJia.html')
运行成功会在 D:\python_data\数据可视化 目录下生成fangJia.html文件
源码
代码中的注释都是我的分析思路和想法,有需要的且和我一个脑筋的可以试着看下
import requests
from lxml import etree
url = 'https://sh.newhouse.fang.com/house/s/b91/?ctm=1.sh.xf_search.page.1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
resp = requests.get(url,headers=headers)
# print(resp) # <Response [200]>
resp_text = resp.content.decode(encoding='gbk')
# print(resp_text)
resp_html = etree.HTML(resp_text)
rep_lisp = resp_html.xpath('//*[@id="newhouse_loupai_list"]/ul/li')
# print(rep_lisp) # [<Element li at 0x17629a61288>, <Element li a......
# print(type(rep_lisp)) # <class 'list'>
names = []
prices = []
for i in rep_lisp:
if i.xpath('.//div[@class="nlcd_name"]/a/text()') != []:
print(i.xpath('.//div[@class="nlcd_name"]/a/text()')) # ['\n\t\t\t\t\t\t\t\t\t\t万科西郊都会 \t\t\t\t\t\t\t\t\t\t\t\n\t\t\t\t\t'] ['\n\t\t\t\t\t\t\t\t\t\t万科青藤公园 \t\t\t\t\t\t\t\t\t\t\t\n\t\t\t\t\t']...
name = i.xpath('.//div[@class="nlcd_name"]/a/text()')[0].strip()
# print(name) # 万科西郊都会 万科青藤公园 新城虹口金茂府...
# print(type(name)) #<class 'str'>
names.append(name)
if i.xpath('.//div[@class="nhouse_price"]/span/text()') != []: # and i.xpath('.//div[@class="nhouse_price"]/span/text()') != ['价格待定']
price = i.xpath('.//div[@class="nhouse_price"]/span/text()')[0]
# print(price) # 331 46000.....
# print(type(price)) # <class 'str'>
prices.append(price)
print(names) # ['万科西郊都会', '万科青藤公园', '新城虹口金茂府', '城开御瑄', '四季都会', '外滩豪...
print(prices) # ['331', '46000', '122400', '110000', '350', '价格待定', '52
# 可视化
from pyecharts.charts import Bar # pip install pyecharts
bar = Bar() # Bar:柱状
bar.add_xaxis(names)
bar.add_yaxis('房价信息(元/平方米)',prices)
bar.render('D:\python_data\数据可视化\\fangJia.html')
至此,就完了,也快凌晨一点了。这里只是爬取了第一页的数据来做可视化,需要拿到更多数据的可以在最外层再加一个循环,请求地址(url)做一下拼接就可以控制爬取数据的页数了
关于博主
做一件事不坚持怎么可能看到收获呢!