一、设计方案
1.主题式网络爬虫名称:微博热搜榜前20信息数据爬取进行数据分析与可视化
2.爬取内容与数据特征分析:爬取微博热搜榜前20热搜事件、排名与热度,数据呈一定规律排序。
3.设计方案概述:思路:首先打开目标网站,运用开发工具查看源代码,寻找数据标签,通过写爬虫代码获取所要的数据,将数据保存为csv或者xlsx文件,读取文件对数据进行数据清洗处理、可视化等操作。
难点:网站数据的实时更新,信息容易变动;重点在于寻找数据标签;对数据整理、可视化等代码的掌握程度较低,需要观看以往视频或者上网搜索,进度慢。
二、主题页面的结构特征分析
1.主题页面的结构与特征:通过分析页面得知所要获取的数据分布于a标签中,td为热度标签。
2.Htmls页面解析
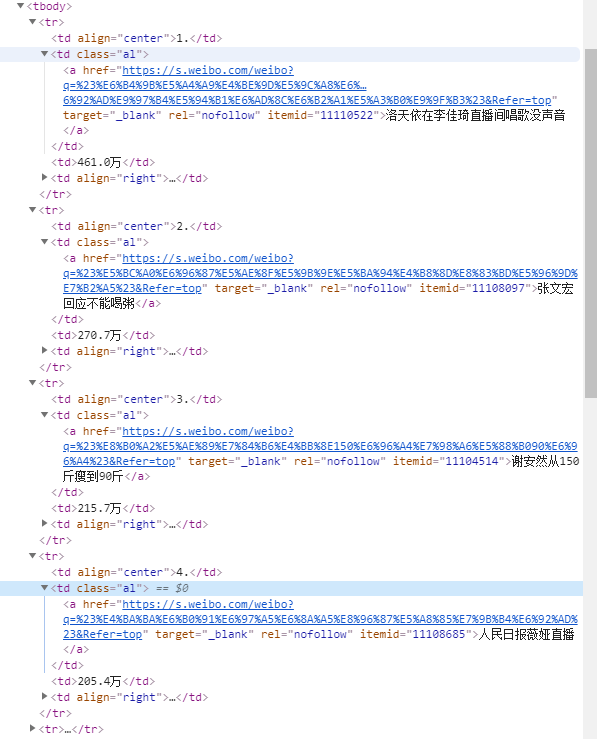
3.节点(标签)查找方法与遍历方法:通过re模块的findall方法进行查找。
三、程序设计
1.数据爬取与采集
import re import requests import pandas as pd #爬取网站 url = 'https://tophub.today/n/KqndgxeLl9' #伪装爬虫 headers = {'user-Agent':""} #抓取网页信息 response=requests.get(url,headers=headers,timeout=30) response = requests.get(url,headers = headers) #爬取内容 html = response.text titles = re.findall('<a href=".*?">.*?(.*?)</a>',html)[4:24] heat = re.findall('<td>(.*?)</td>',html)[:20] x = {'标题':titles,'热度':heat} y = pd.DataFrame(x) #创建空列表 data=[] for i in range(20): #拷贝数据 data.append([i+1,titles[i],heat[i][:]]) #建立文件 file=pd.DataFrame(data,columns=['排名','热搜事件','热度(万)']) print(file) #保存文件 file.to_excel('D:\\bbc\\微博热搜榜.xlsx')

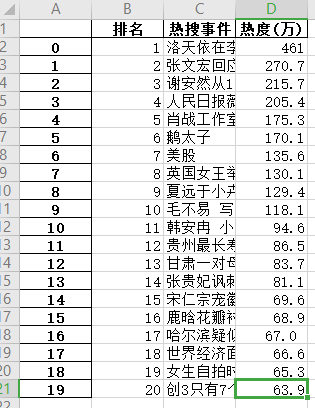
2.对数据进行清洗和处理
#读取csv文件 df = pd.DataFrame(pd.read_excel('微博热搜榜.xlsx')) df.head()

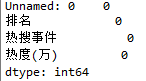
#缺失值处理 df.isnull().head() #True为缺失值,False为存在值

#空值处理# df.isnull().sum() #0表示无空值
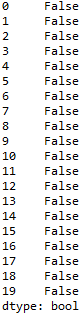
#查找重复值 df.duplicated() #显示表示已经删除重复值
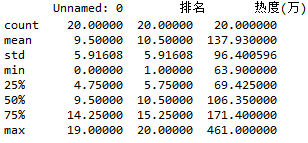
#查看统计信息 df.describe()
3.文本分析:无法安装wordcloud库
4.数据分析与可视化
#绘制条形图 df = pd.read_excel('微博热搜榜.xlsx') x = df['排名'] y = df['热度(万)'] plt.xlabel('排名') plt.ylabel('热度(万)') plt.bar(x,y) plt.title("微博热搜排名与热度条形图") plt.show()

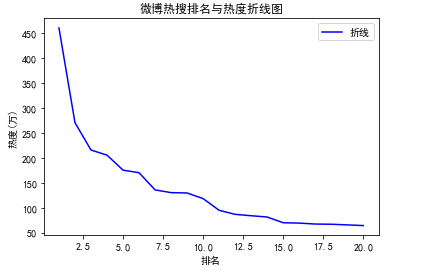
#绘制折线图 df = pd.read_excel('微博热搜榜.xlsx') x = df['排名'] y = df['热度(万)'] plt.xlabel('排名') plt.ylabel('热度(万)') plt.plot(x,y,color="blue",label="折线") plt.title("微博热搜排名与热度折线图") plt.legend() plt.show()
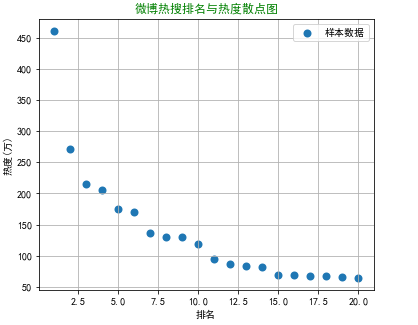
#绘制散点图 df = pd.read_excel('微博热搜榜.xlsx') 排名 = (df['排名']) 热度 = (df['热度(万)']) plt.figure(figsize=(6,5)) plt.scatter(排名,热度,label=u"样本数据",linewidth=2) plt.title("微博热搜排名与热度散点图",color="green") plt.xlabel("排名") plt.ylabel("热度(万)") plt.legend() plt.grid() plt.show()
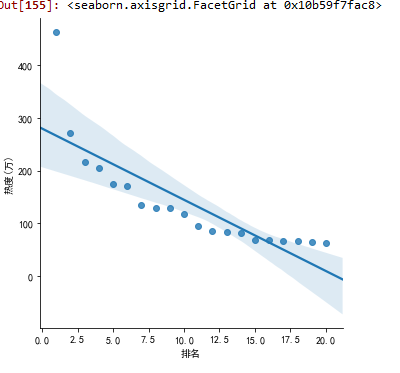
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
#线性关系散点图 df = pd.DataFrame(pd.read_excel('微博热搜榜.xlsx')) sns.lmplot(x="排名",y= "热度(万)",data=df)
#回归方程曲线图 df = pd.DataFrame(pd.read_excel('微博热搜榜.xlsx')) q = df['排名'] w = df['热度(万)'] def func(p,x): a,b,c=p return a*x*x+b*x+c def error_func(p,x,y): return func(p,x)-y p0=[0,0,0] Para=leastsq(error_func,p0,args=(q,w)) a,b,c=Para[0] plt.figure(figsize=(12,6)) plt.scatter(q,w,color="blue",label=u"热度散点",linewidth=2) x=np.linspace(0,20,15) y=a*x*x+b*x+c plt.plot(x,y,color="green",label=u"回归方程曲线",linewidth=2) plt.xlabel("排名") plt.ylabel("热度(万)") plt.title("微博热搜排名与热度回归曲线图") plt.legend() plt.show()
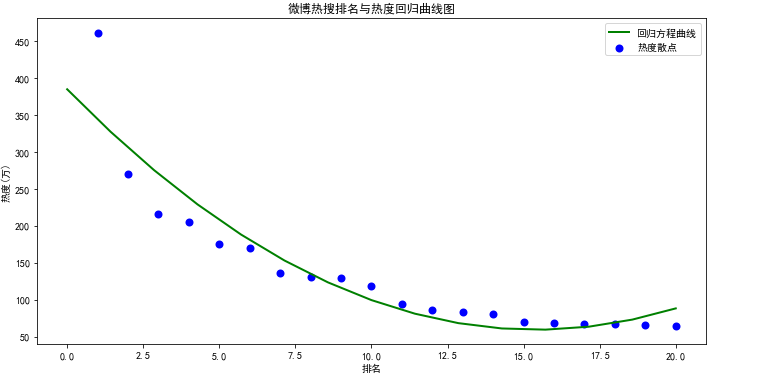
6.代码汇总
import re import requests import pandas as pd import seaborn as sns import numpy as np from numpy import genfromtxt import scipy as sp import matplotlib.pyplot as plt from scipy.optimize import leastsq plt.rcParams['font.sans-serif']=['SimHei']#用来正常显示中文 plt.rcParams['axes.unicode_minus']=False#用来正常显示负号 #爬取网站 url = 'https://tophub.today/n/KqndgxeLl9' #伪装爬虫 headers = {'user-Agent':""} #抓取网页信息 response=requests.get(url,headers=headers,timeout=30) response = requests.get(url,headers = headers) #爬取内容 html = response.text titles = re.findall('<a href=".*?">.*?(.*?)</a>',html)[4:24] heat = re.findall('<td>(.*?)</td>',html)[:20] x = {'标题':titles,'热度':heat} y = pd.DataFrame(x) #创建空列表 data=[] for i in range(20): #拷贝数据 data.append([i+1,titles[i],heat[i][:]]) #建立文件 file=pd.DataFrame(data,columns=['排名','热搜事件','热度(万)']) print(file) #保存文件 file.to_excel('D:\\bbc\\微博热搜榜.xlsx') #读取csv文件 df = pd.DataFrame(pd.read_excel('微博热搜榜.xlsx')) df.head() #缺失值处理 df.isnull().head() #True为缺失值,False为存在值 #空值处理# df.isnull().sum() #0表示无空值 #查找重复值 df.duplicated() #显示表示已经删除重复值 #查看统计信息 df.describe() #绘制条形图 df = pd.read_excel('微博热搜榜.xlsx') x = df['排名'] y = df['热度(万)'] plt.xlabel('排名') plt.ylabel('热度(万)') plt.bar(x,y) plt.title("微博热搜排名与热度条形图") plt.show() #绘制折线图 df = pd.read_excel('微博热搜榜.xlsx') x = df['排名'] y = df['热度(万)'] plt.xlabel('排名') plt.ylabel('热度(万)') plt.plot(x,y,color="blue",label="折线") plt.title("微博热搜排名与热度折线图") plt.legend() plt.show() #绘制散点图 df = pd.read_excel('微博热搜榜.xlsx') 排名 = (df['排名']) 热度 = (df['热度(万)']) plt.figure(figsize=(6,5)) plt.scatter(排名,热度,label=u"样本数据",linewidth=2) plt.title("微博热搜排名与热度散点图",color="green") plt.xlabel("排名") plt.ylabel("热度(万)") plt.legend() plt.grid() plt.show() #线性关系散点图 df = pd.DataFrame(pd.read_excel('微博热搜榜.xlsx')) sns.lmplot(x="排名",y= "热度(万)",data=df) #回归方程曲线图 df = pd.DataFrame(pd.read_excel('微博热搜榜.xlsx')) q = df['排名'] w = df['热度(万)'] def func(p,x): a,b,c=p return a*x*x+b*x+c def error_func(p,x,y): return func(p,x)-y p0=[0,0,0] Para=leastsq(error_func,p0,args=(q,w)) a,b,c=Para[0] plt.figure(figsize=(12,6)) plt.scatter(q,w,color="blue",label=u"热度散点",linewidth=2) x=np.linspace(0,20,15) y=a*x*x+b*x+c plt.plot(x,y,color="green",label=u"回归方程曲线",linewidth=2) plt.xlabel("排名") plt.ylabel("热度(万)") plt.title("微博热搜排名与热度回归曲线图") plt.legend() plt.show()
四、结论
1.结论:对主题数据的分析与可视化,能将数据变的更加直观,更加容易观察出数据的规律、关系等。此次微博热榜的排名和热度是呈正比的,但其实事件内容才是吸引大众的关键因素。总之数据发分析与可视化直观的展示信息的分析结果与构思,令抽象的数据具体化,便于我们观察。
2.任务小结:本次程序设计任务完成时间较久,也是在一步一步学习熟悉python的知识,通过本次任务提高了对代码的掌握程度,并且在完成任务的过程中提高了实践能力,也是为以后编写代码打下一点基础。