
思路:
1. 安装代理AnProxy,在手机端安装CA证书,启动代理,设置手机代理;
2. 获取目标微信公众号的__biz;
3. 进入微信公众号的历史页面;
4. 使用Monkeyrunner控制滑屏;获取更多的历史消息;
5. 记录文章标题,摘要,创建时间,创作类型,地址等等;
6. 文章列表获取完成后,利用Monkeyrunner进入文章的列表,
7. 记录文章的阅读数,点赞数,评论数等;
8. 重复以上操作。
数据爬取结果
数据分析
文章发布数量分析:
文章总数:914篇,每个月发布情况如下:
import pandas as pd
import matplotlib.pyplot as plt
name=['日期','时间','标题','作者','摘要','创作类型','是否头条号','阅读数','点赞数','评论数','地址']
df = pd.read_excel('weixin1.xlsx',encoding= 'utf-8',header=1,names=name,)
df['文章数'] = pd.to_datetime(df['日期']).dt.month
date = pd.DataFrame(df['文章数'].value_counts())
plt.figure(figsize=(15, 5))
plt.title('CSDN公众号文章发布情况')
plt.xlabel('月份')
plt.ylabel('文章数')
plt.xticks((1,2,3,4,5,6,7,8,9,10,11,12),('2017-01','2017-02','2017-03','2017-04','2017-05','2017-06','2017-07','2017-08','2017-09',
'2017-10','2017-11','2017-12'))
plt.plot(date.sort_index(),color='green',linestyle='dashed', marker='o', markerfacecolor='blue', markersize=8,)
plt.show()
通过发布文章次数的曲线来看,CSDN在4月份的才正式确定运营微信公众号,在11月份和12月份月发布次数已经超过100篇,每天6篇文章已经成为常态,小姐姐确实不容易啊,手动点赞!
创作类型分析:
import pandas as pd
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.pyplot as plt
name=['日期','时间','标题','作者','摘要','创作类型','是否头条号','阅读数','点赞数','评论数','地址']
df = pd.read_excel('weixin1.xlsx',encoding= 'utf-8',header=1,names=name,)
data = pd.DataFrame(df['创作类型'].value_counts())
explode=[0,0,0,0,0]
plt.figure(figsize=(15, 6))
plt.axes(aspect=1)
plt.title('文章创作情况',fontsize=18)
plt.pie(x=data,autopct='%.2f%%',explode=explode,shadow=True,labels=['原创','未标记作者','创作或转发','其它','未知'])
plt.show()

通过文章的创作情况来看,一半以上的文章都是原创。基本上每天至少有一篇原创的文章。
有这样的文采,确实是难得的人才。
阅读数分析:
import pandas as pd
import matplotlib.pyplot as plt
name=['日期','时间','标题','作者','摘要','创作类型','是否头条号','阅读数','点赞数','评论数','地址']
df = pd.read_excel('weixin.xlsx',encoding= 'utf-8',header=1,names=name,)
data = df[['阅读数']]
a = data.sort_values(by=['阅读数'],ascending=False)
one = a[a['阅读数']>=70000].size
two = a[(a['阅读数']>=30000) & (a['阅读数']<70000)].size
three = a[(a['阅读数']>=10000) & (a['阅读数']<30000)].size
four = a[(a['阅读数']>=1000) & (a['阅读数']<10000)].size
five = a[(a['阅读数']<1000)].size
explode=[0.3,0,0,0,0]
fras = [one,two,three,four,five]
plt.figure(figsize=(15, 5))
plt.axes(aspect=1)
plt.title('阅读数分布比例',fontsize=18)
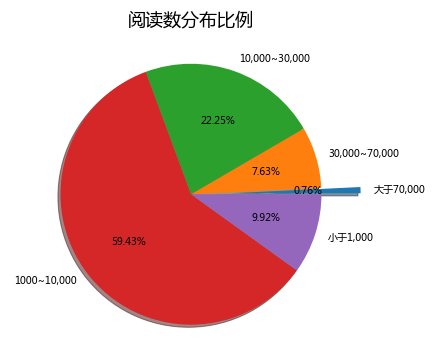
plt.pie(x=fras,autopct='%.2f%%',explode=explode,shadow=True,labels=['大于70,000','30,000~70,000','10,000~30,000','1000~10,000','小于1,000'])
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.pyplot as plt
name=['日期','时间','标题','作者','摘要','创作类型','是否头条号','阅读数','点赞数','评论数','地址']
df = pd.read_excel('weixin1.xlsx',encoding= 'utf-8',header=1,names=name,)
df_read = df[['标题','阅读数']]
data_read = df.sort_values(by=['阅读数'],ascending=False)
data_read.index = data_read['标题']
var = data_read['阅读数'][:10]
plt.figure(figsize=(15, 6))
plt.title('阅读数 TOP10 的文章',fontsize=18)
plt.xlabel('数量',fontsize=18)
plt.ylabel('标题',fontsize=18)
var.plot(kind='barh', stacked=True,alpha=0.5, color=['red'])
plt.show()
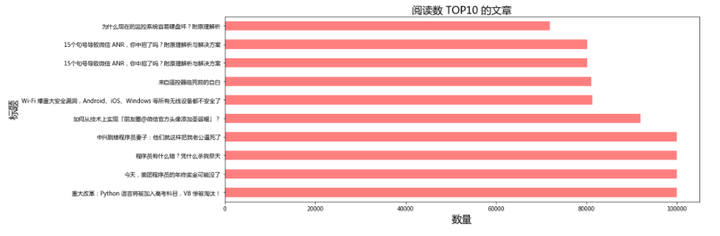
由于阅读数超过10W,返回值为100001,具体数字是多少,前后台不得而知。整体文章质量比较高,不乏有10万+的文章出现。大V,对技术资讯的传播具有很大的影响力!
点赞数分析:
import pandas as pd
import matplotlib.pyplot as plt
name=['日期','时间','标题','作者','摘要','创作类型','是否头条号','阅读数','点赞数','评论数','地址']
df = pd.read_excel('weixin.xlsx',encoding= 'utf-8',header=1,names=name,)
data = df[['点赞数']]
a = data.sort_values(by=['点赞数'],ascending=False)
one = a[a['点赞数']>=200].size
two = a[(a['点赞数']>=50) & (a['点赞数']<200)].size
three = a[(a['点赞数']<50)].size
explode=[0.3,0,0]
fras = [one,two,three]
plt.figure(figsize=(15, 5))
plt.axes(aspect=1)
plt.title('点赞数分布比例',fontsize=18)
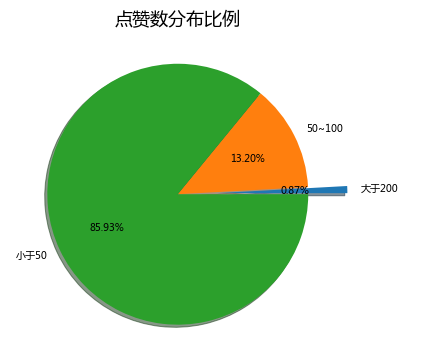
plt.pie(x=fras,autopct='%.2f%%',explode=explode,shadow=True,labels=['大于200','50~100','小于50'])
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.pyplot as plt
name=['日期','时间','标题','作者','摘要','创作类型','是否头条号','阅读数','点赞数','评论数','地址']
df = pd.read_excel('weixin1.xlsx',encoding= 'utf-8',header=1,names=name,)
df = df[['标题','点赞数']]
data = df.sort_values(by=['点赞数'],ascending=False)
data.index = data['标题']
var = data['点赞数'][:10]
plt.figure(figsize=(15, 6))
plt.title('点赞数 TOP10 的文章',fontsize=18)
plt.xlabel('数量',fontsize=18)
plt.ylabel('标题',fontsize=18)
var.plot(kind='barh', stacked=True,alpha=0.7, color=['green'])
plt.show()
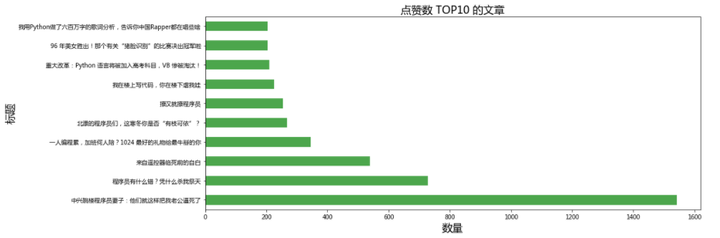
“中兴跳楼程序员妻子:他们就这样把我老公逼死了”文章点赞数1542,“我们愤恨于现实,在互联网内外,公司调整牺牲员工利益的不公平不道德之事时有发生,尤其是在互联网公司,裁员更是屡见不鲜,尤以“为什么总说程序员是吃青春饭的?”为重。而到了个人身上,随着年岁增长,学习、精神等的下降,上有老下有小,面对突然的被辞退,压力可想而知,但是当事情发生之时,我们还是要尽可能地调整心态,网上评论的很多,这种基层主管处于不上不下的尴尬处境,只能考虑降低心理预期,哪怕是从头再来呢。生活固然残酷,但也不要轻易放弃,毕竟还有自己爱和爱自己的人啊!”,大家对此特别赞同!
评论数分析:
import pandas as pd
import matplotlib.pyplot as plt
name=['日期','时间','标题','作者','摘要','创作类型','是否头条号','阅读数','点赞数','评论数','地址']
df = pd.read_excel('weixin.xlsx',encoding= 'utf-8',header=1,names=name,)
data = df[['评论数']]
a = data.sort_values(by=['评论数'],ascending=False)
one = a[a['评论数']>=50].size
two = a[(a['评论数']>=20) & (a['评论数']<50)].size
three = a[(a['评论数']<20)].size
explode=[0.3,0,0]
fras = [one,two,three]
plt.figure(figsize=(15, 5))
plt.axes(aspect=1)
plt.title('评论数分布比例',fontsize=18)
plt.pie(x=fras,autopct='%.2f%%',explode=explode,shadow=True,labels=['大于50','20~50','小于20'])
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.pyplot as plt
name=['日期','时间','标题','作者','摘要','创作类型','是否头条号','阅读数','点赞数','评论数','地址']
df = pd.read_excel('weixin1.xlsx',encoding= 'utf-8',header=1,names=name,)
df = df[['标题','评论数']]
data = df.sort_values(by=['评论数'],ascending=False)
data.index = data['标题']
var = data['评论数'][:10]
plt.figure(figsize=(15, 5))
plt.title('评论数 TOP10 的文章',fontsize=18)
plt.xlabel('数量',fontsize=18)
plt.ylabel('标题',fontsize=18)
var.plot(kind='barh', stacked=True,alpha=0.7, color=['blue'])
plt.show()
