Logistic回归是一种最优化算法
Logistic回归的一般过程
(1) 收集数据:采用任意方法收集数据。
(2) 准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据 格式则最佳。
(3) 分析数据:采用任意方法对数据进行分析。
(4) 训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
(5) 测试算法:一旦训练步骤完成,分类将会很快。
(6) 使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值; 接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于 哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
适用数据类型:数值型和标称型数据。
引入一个单位阶跃函数,sigmoid函数
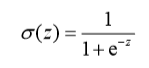
z=w0x0+w1x1+…+xnxn
如果采用向量的写法,上述公式可以写成z = wTx,
x为输入数据,w即为要求的参数
梯度上升法
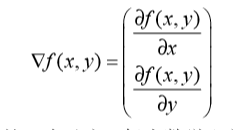
迭代公式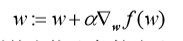
算法实现:
画拟合直线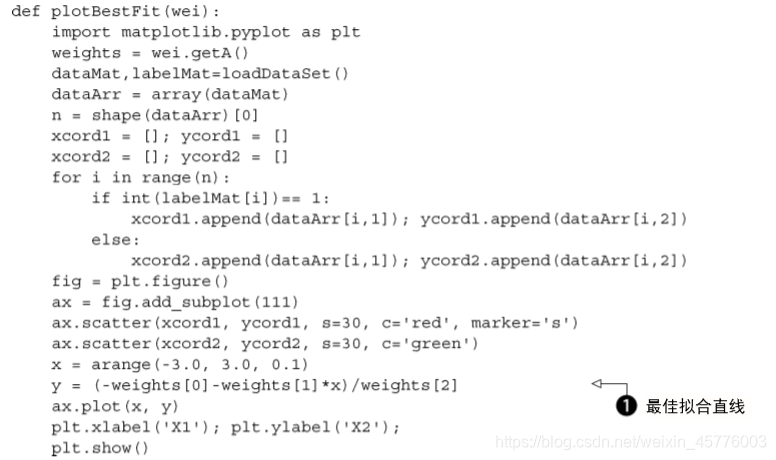
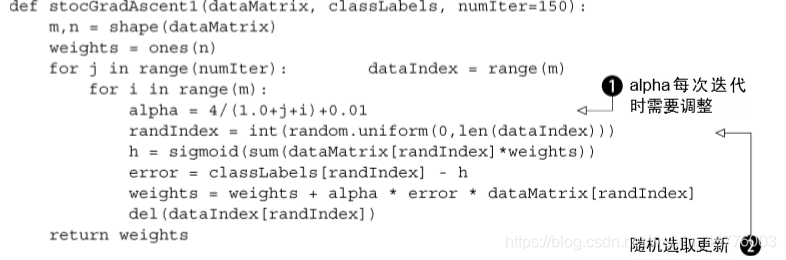
随机梯度上升,梯度上升法的改进,一次仅用一个样本点来更新回归系数

示例:从疝气病症预测病马的死亡率
丢失数据的预处理:
这里选择实数0来替换所有缺失值,恰好能适用于Logistic回归。这样做的直觉在 于,我们需要的是一个在更新时不会影响系数的值。
如果dataMatrix的某特征对应值为0,那么该特征的系数将不做更新
另外,由于sigmoid(0)=0.5,即它对结果的预测不具有任何倾向性,因此上述做法也不会对 误差项造成任何影响。基于上述原因,将缺失值用0代替既可以保留现有数据,也不需要对优化算 法进行修改。此外,该数据集中的特征取值一般不为0,因此在某种意义上说它也满足“特殊值” 这个要求
预处理中做的第二件事是,如果在测试数据集中发现了一条数据的类别标签已经缺失,那么我 们的简单做法是将该条数据丢弃。这是因为类别标签与特征不同,很难确定采用某个合适的值来替 换。采用Logistic回归进行分类时这种做法是合理的,而如果采用类似kNN的方法就可能不太可行。
函数如图

