文章目录
本文创新点\贡献
对于每个帧,使用语义的逐像素嵌入和全局、局部匹配机制来将信息从第一帧和前面帧转到当前帧
本文IDEA来源
Pixel-Wise Metric Learning (PML),这个东西通过Triplet loss来学习逐像素的嵌入,测试的时候通过计算和第一帧的最近邻来给每个像素分配label
作者提出方法学习嵌入向量和最近邻匹配,来用作卷积网络内置的指导,使用交叉熵来学习
设计目标
- 简单:只有一个网络,不需要模拟数据
生成数据也不用,这么厉害吗
- 快速:不依赖第一帧微调
- 端到端:解决每个视频包含多种物体的情况
方法
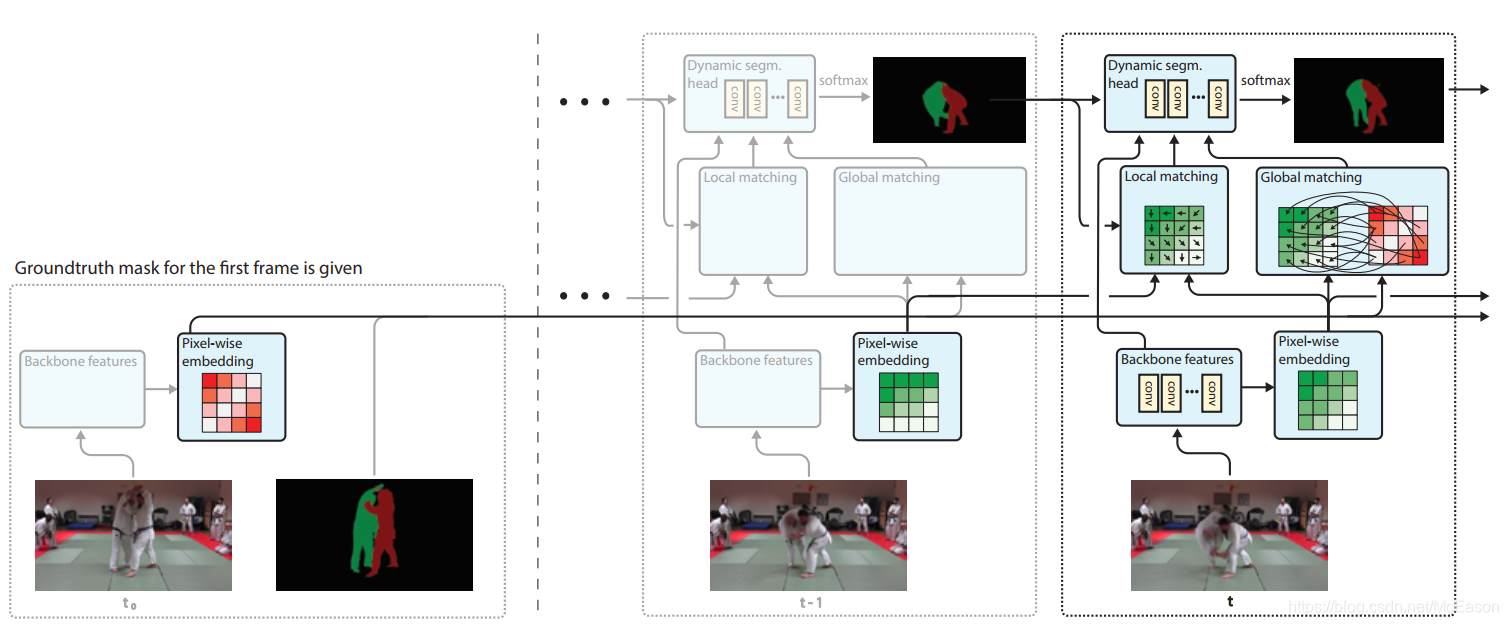
对第一帧进行全局匹配,对前面帧进行局部匹配。
最近邻匹配只是个软线索,网络能复原这里的错误信息, 保证结果的准确性
最后结合全局distance map、局部distance map、前一帧的预测结果、backbone特征,将这些送进动态分割head,对每个像素生成一个第一帧存在的全部类的分布。
Semantic Embedding
对每个像素 都提取一个嵌入空间的嵌入向量
也就和特征向量是一个思想,这里用PLM
作用:
在同一帧或不同帧中,属于同一物体实例的像素之间的嵌入空间会相似,不属于同一物体实例的会差别很大
使用:
这个向量能被动态分割头微调,只是一个软线索,事实证明这个线索对后来的分割效果很有效
通过嵌入向量来计算distance:
这个公式看起来很不错,将结果限制在了[0,1]中,最相似为0,最不相似为1
计算的时候是如何对应像素的?比如第一帧o物体M个像素,当前帧H x W个像素,最后计算M x H x W个式子?
对
Gloab match
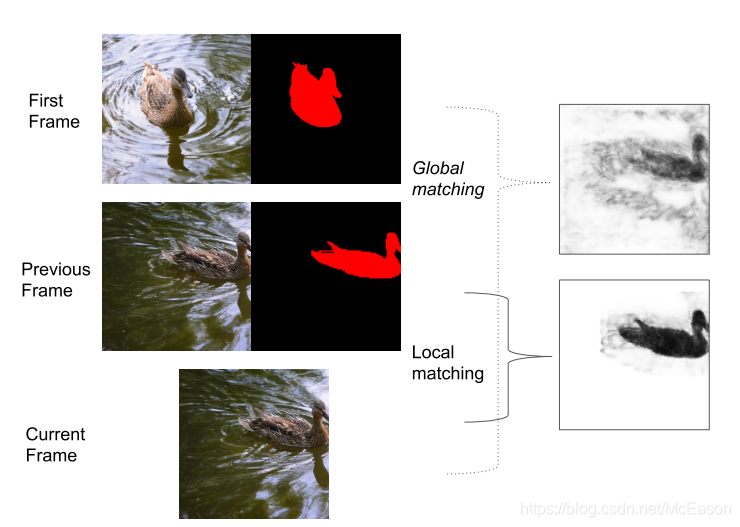
对于每个物体,通过将第一帧的属于该物体的嵌入向量和当前帧的嵌入向量做全局匹配, 来计算一个distance map
设定 表示 帧的所有像素(步长为4), ,表示 帧中属于物体 的像素。
然后计算全局匹配,对于每个第一帧标注的真实物体
都计算和
帧里所有像素
的distance map
,用这个作为属于物体
的最近邻距离:
其中
不会是空的,这是从第一帧提取出来的物体
像素,这个
提供了当前帧的每个像素和每个物体的关于是否属于某个物体的软线索。
或许当前帧的每个像素会和第一帧的所有物体 的像素计算相似度,然后取最小的一个作为当前像素的相似度,也就是说对应的distance map的该位置的值就是这个,然后就能得到上面的distance map图
由上图可知全局的distance map的噪声还是蛮大的,所以不能直接用于分割,要通过一个head的处理。
实践的时候作者做了一个很大的矩阵,我来想象一下:
设高为H,宽为W,物体数为O,嵌入向量长度为E,所以第一帧的数据维度是H x W x E,然后当前帧是H x W x E,把当前帧转换成 E x (HW) 让H x W x E 和 E x HW做广播相减,就是H x W x (E x HW) - H x W x (E x HW) ,第一项是把E重复了HW次,第二项是把E x HW重复了H x W次,然后按维度相加再处理,每个O都这么操作一次,在不是object的像素的位置设置特殊的嵌入向量。
Local match
使用前一帧的预测来为每个物体计算另一个distance map,方法是将当前帧的嵌入与前一帧的嵌入向量进行局部匹配
粗糙构想:

其中
的index从1到
,应该不是说全部算一遍吧,应该是说可以的取值,
来自网络的预测,也有可能是空的。
这种情况下假设移动很小,也就不需要每个像素对应每个像素那样取计算了。
修改:
但是没有用上面的公式,受FlowNet启发,对于t帧的p像素,只计算t-1帧的p周围的像素q,将周围像素定义为
。
假设窗口大小是 ,计算 次
这个次数我感觉是有问题的
由此计算公式变成:
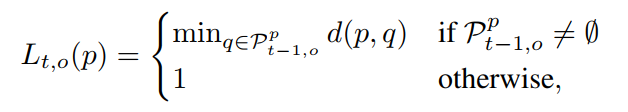
其中
是
帧的属于
的像素和
的近邻。可以通过叉乘来计算
。实验表明
优于
Dynamic Segmentation Head

由一些卷积构成,对每个object提取logits的一维特征图。
输入的通道时是259,其中256来自backbone,这个对于每个物体来说都是相同的,只有三个通道是不同的,但是实验证明这三个通道足够表达很强的线索,最后每个物体输出一个一维的logits分数,所有的一维logits叠放到一起后在物体的维度上使用softmax,然后计算交叉熵loss
训练
使用的DeepLabv3+的结构,提取特征是4步长,在后边加了嵌入层,以同样的步长提取特征向量。
Training procedure
对于每一步,先随机选择video的最小batch,其中一个作为参考帧,扮演第一帧的角色,然后取相邻的两帧作为前一帧和当前帧,只计算当前帧的loss。
训练的时候使用前一帧的真实值来做局部匹配,也用这个来生成预测mask。
Inference
对动态分割头的输出,计算逐像素的argmax,生成最后的分割。
Implementation Details
用一个depthwise分离的 卷积和 卷积生成嵌入向量,维度是100,加载backbone的后面
这个卷积的说明
depthwise就是每个通道独立卷积,输出的特征图通道数不变,然后在加上point wise就是深度分离卷积了,point wise是N个卷积核,N是输出的特征图的维度,卷积核的大小是$ 1 \times 1 \times M$,M是输入的通道数,在通道上加权求和,这样能融合通道特征
发现动态分割头的大的感受野很重要,用了四个深度分离卷积,维度是256,大小是 ,然后加一个ReLU激活函数。然后在后面加一个 卷积提取1维的logits
top好像就是后面的意思
然后计算全局匹配的时候点太多了,对第一帧的像素做了随机下采样,每个物体只包含1024个像素,发现不会影响结果
如何控制每个物体的像素数?用box?
局部匹配的窗口 ,使用在ImageNet上预训练的权重。
使用bootstrapped cross entropy loss只计算15%最尖锐的像素来计算loss
尖锐如何衡量呢?用softmax的分数吗?
实验结果

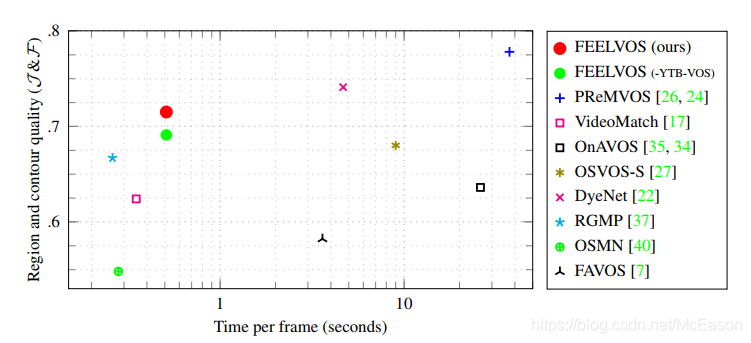
比起PReMVOS的效果还是差不少,速度快一些
总结
感觉这些东西都很依赖第一帧啊,跟RGMP也蛮像的,就是RGMP只用了全局信息,而这个将第一帧和前一帧分开来,分别计算全局信息和局部信息;
再就是嵌入向量,像STM,STM是计算memory和当前帧的相似性,但是没用这种嵌入向量的方式,memory来自前面多帧共同结果,而这个是计算第一帧和当前帧、前一帧和当前帧的相似性。
或许是占了嵌入向量的光?
