参见:论文翻译:Associative Embedding:End-to-End Learning for Joint Detection and Grouping_Leopiglet的博客-CSDN博客
论文笔记_人体姿态估计:Associative Embedding - 知乎
论文下载链接与代码链接
论文:https://arxiv.org/pdf/1611.05424v2.pdf
代码:https://github.com/princeton-vl/pose-ae-train
【B视频】
Associative Embedding,一种有监督的卷积神经网络用于检测与分组任务中采取的新方法。
对于大多数CV问题,如多人姿态估计、实例分割、多对象跟踪,均可使用该方法。通常对检测结果的分组借助多阶段pipeline达成,本文则训练出单个网络用以实时输出检测结果与分组情况。该方法能够兼容任意现有最佳的网络结构,获得像素级的预测结果。
一、Introduction:
大部分CV问题可被视为检测与分组的结合:检测较小的可视单元并将其分组到大框架中。例如,多人姿态估计可被视为检测人体关键点并将其分组到个人的标签上;实例分割可被视为检测相关的像素并将其分组到对象实例上;多对象跟踪可被视为检测对象实例并将其分组到相应轨迹上。针对以上案例,其输出为一系列的可视化单元与一系列的可视化分组任务。
通常此类任务需要进行两个阶段的pipeline:先进行检测,后进行分组。但这样的做法有些欠佳(suboptimal),因为检测与分组通常来说是紧密耦合的(tightly coupled)。例如,多人姿态估计中,在附近未被检测到有同组手肘的一个手腕检测响应会被视为错检(FP)。for example, in multi-person pose estimation, a wrist detection is likely a false positive if there is not an elbow detection nearby to group with.
本文提出利用单阶段的深层网络并进行端到端训练,可以实现将检测与分组结合。
Associative Embedding(关联式嵌入策略),是一种输出将检测与分组相结合表达的新颖方法。
基本思想:Associative Embedding是一种表示关节检测和分组任务的输出的新方法,其基本思想是为每次检测引入一个实数,用作识别对象所属组的“标签tag”,换句话说,标签将每个检测与同一组中的其他检测相关联。作者使用一个损失函数使得如果相应的检测属于ground truth中的相同组则促使这一对标签具有相似的值。需要注意的是,这里标签具体的值并不重要,重要的是不同标签之间的差异。
借鉴了word embedding的思想,为每个关节点生成一个embedding,通过embedding之间的距离来组合关节点。作者发现1D embedding就已经足够表达,也可以称之为tag。
文章的思想很直观,方法也很简单。网络不需要two branch,只需要在原来输出的heatmap中增加几层来表达embedding即可。这个方法很容易集成到各种bottom up的方法中去,比如HigherHRNet(CVPR2020)就是使用Assoc. Embed的方式来进行组合的。

什么是associative embedding?
用于多目标组分配,可结合多人姿态估计、实例分割、多目标跟踪等许多视觉任务,可看作检测和分组的组合,检测较小的视觉单元,并将其组合成更大的结构,作者提出检测与分组group是耦合的,例如,当手肘不存在时,检测出来的手肘可能是FP
网络输出逐像素的检测得分heatmap以及逐像素的身份标签,identity tags heatmap,相同分组的tag期望具有相似的值,tag并没有确定的gt,起决定因素的不是tag绝对值,而是tag之间的相对差异。associative embedding用于在每一格候选目标的检测分数之外,再预测一个embeding;这些嵌入可以作为分组编码的标签,具有相似编码的应该被分在一起(相同人体tag相同,不同人体tag不同)。
multiperson pose estimation可以被视为检测人体关节并将它们分组为单个人。实体分割可以被视为检测相关的像素并分组到对象实体。 multi-object tracking可以被视为检测实体分割并分组到各自轨道。这些都有相似性,detect一系列微小的visual units,被分配到一系列的grouping。
论文研究detection and grouping紧密结合性,在单一阶段end-to-end实现detection and grouping。提出 associative embedding,说白了就是在每次检测过程中,用tag识别不同group,相同tag的detection分成相同的group。(从像素分割延伸,就是detection 分割)
grouping分组:
- 依次遍历关节点,先确定头部和躯干,然后确定四肢, 直至所有关节点都分配了人体
- 两个tags只有当他们落入设定阈值后,才被分为同一个group
针对该任务,本文将AE(Associative Embedding)策略与SHN(Stacked Hourglass Networks)进行结合,获得各个关节点的检测热图与标签热图,随后将TAG值相似的关键点分组为同一个人。
本文贡献主要有2点:
1、提出associative embedding,实现 single- stage,end-to-end joint detection and grouping。其实这种思路就是从像素级instance segmentation到detection级instance segmentation。
2、用associative embedding实现multiperson pose estimation,并取得state-of-the-art水平。
二、Related Work:
2.1 Vector Embedding{向量嵌入}:
图像检索(image retrieval)方面多用到VE向量嵌入来测定图像间的相似度[17,53]。
图像分类、图像说明(image captioning)、短语定位等方面也用VE通过将可视化特征与纹理特征映射到同一向量空间来建立可视化特征与纹理特征间的关系[16,20,30]。
自然语言处理也采用VE策略来表达单词、句子、段落的含义[39,32]。
不同于以上用法,本文在检测和分组相结合的上下文中使用VE向量嵌入作为身份标记TAG。
2.2 Perceptual Organization{感知组织}:
感知组织旨在将图片的像素分组成不同的区域、部件、对象。
感知组织囊括(encompass)了广泛的复杂多变的任务:从地物分割[37](figure-ground segmentation)到层次图像分析[21](hierarchical image parsing)。
以往的研究多采用2阶段的pipeline[38],先检测基本可视化单元(像素块patch、超像素superpixels、图像片段part等),再将这些可视化单元进行分组。
常见的分组方法包括光谱聚类 (spectral clustering,51,46),条件随机场(conditional random fields,31)和生成概率模型(generative probabilistic models,21)。
以上分组方法都假定预检测到的基本可视化单元和它们之间预计算得到的关联度量(affinity measures), 但在将关联度量转化为分组的过程中存在差异。
相比之下,本文方法采用不包含特殊分组设计的通用网络(generic network)将检测与分组在一个阶段中获得实现。
值得注意的是本文的方法与那些利用了光谱聚类的方法之间存在着紧密的联系(It is worth noting a close connection)。光谱聚类(例如归一化割[46])将输入作为可视化单元之间的预计算关联度(例如通过一个深度网络来进行预测)并且解决了一个广义特征问题(generalized eigent problem),以生成与高关联度视觉单元相似的(每个视觉单元一个)嵌入。角度嵌入[37,47]通过嵌入深度排序与分组拓展了光谱聚类。本文的方法不同于光谱聚类的是本文既没有对关联度中间的表示也没有求解任何特征问题。相对地,本文网络直接输出最终的嵌入结果。
本文的方法也与Harley等人在深度卷积嵌入学习方面的工作——训练了一个深度网络为语义分割任务生成像素级的嵌入值——有一定关系。而不同之处在于本文的网络不仅生成了像素级的嵌入值,还生成了像素级的检测得分。本文的亮点:将检测与分组融合到单个网络;
三、Multi-person Pose Estimation{多人姿态估计}:
为了介绍检测与分组结合的关联性嵌入方法,本文先对可视化检测的基础部分进行回顾。
3.1 如何评分:
大部分可视化任务涉及到可视化单元集合的检测。这些任务通常被描述为对大量候选集的评分。
例如,单人姿态估计可以被描述为对所有可能的像素位置处的候选关节点检测结果的评分。
对象检测可以被描述为对候选边界框(B-Box)在不同像素位置、比例、方位比(aspect ratios)的评分。
新的评分思路:
AE的思路是在检测评分的基础上,预测每个候选点的嵌入值。
嵌入值作为编码分组的TAG标记:有着相似TAG的检测结果被分为一组。
在多人姿态估计中,有着相似TAG的人体关节点应被分组并构建成单个人。
TAG的绝对值是什么不重要,只需要知道TAG之间距离。
只要具有相同值的检测结果属于同一分组,网络可以为TAG设定任意值。
嵌入值的维度并不重要。如果一个网络可以顺利地预测高维的嵌入值并将检测结果分组,只要网络容量充足,那这个网络也应该可以学习如何将那些高维嵌入值投影到低维。
实践中,1D嵌入值就可以充分满足多人姿态估计,况且更高维度的嵌入值并未达到更好的改善。
如何定义损失:
为训练可以预测TAG的网络,本文定义了一个损失函数:它可以使相同分组的检测结果具有相似的TAG值,不同分组的检测结果具有不同的TAG值(即随后公式中的两部分所表达的含义)。
值得一提的是,该TAG损失只对那些与GT相一致的检测结果进行计算。
本文比较检测对,并根据标签的相对值以及检测是否属于同一分组来定义惩罚。
3.2 Stacked Hourglass Architecture:
本文把AE与SHN[40]——一种用于密集型像素级预测模型——相结合,其由一系列模块组成,每个模块的形状都像沙漏。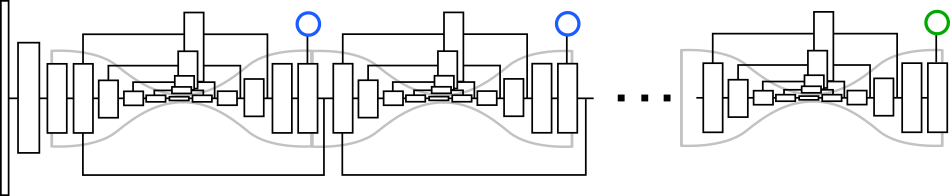
网络执行重复的Bottom-up、Top-down的推论(inference)生成一系列的中间预测,直到最后一个沙漏模型生成最终结果。卷积层的核尺寸皆取3×3,特征图通过上采样与跨层连接执行点加获得。网络所做的所有预测都遵循同一GT。
每个沙漏模块都有一个卷积池化层的标准集合,此过程中特征被处理到低分辨率以获得图像的全部上下文信息。然后,这些特征被上采样并与更高分辨率的输出进行逐一结合,直到获得最终的输出分辨率。级联多个沙漏模块可以重复地采用Bottom-up、Top-down的推论(inference)并生成更精确的最终预测。
级联沙漏模型最初是因单人姿态估计而发展起来的。模型对目标单人的每个关节点输出热图,热图中最高激励响应(activation)的像素被用作该关节点的预测位置。
该网络旨在整合(consolidate)全局与局部特征,这些特征用于获得有关人体整体结构的信息,同时保留用于精确定位的精细细节。这种介于全局与局部特征间的平衡与其他像素级预测任务同等重要。
本文对该网络结构进行了一些轻微的改动。
1、提高特征的分辨率,增加特征的通道数(每次分辨率下降时增加输出的特征的数量(256-386-512-768)),m层是预测人体的各个部位heatmap,m层是对应的tag heatmap。
2、用3x3卷积代替原来的残差模块。
3、For each joint of the body, the network simultaneously produces detection heatmaps and predicts associative embedding tags. We take the top detections for each joint and match them to other detections that share the same embedding tag to produce a final set of individual pose predictions.
这才是改进版Stacked Hourglass的精髓。在预测人体各个关节热点图同时,预测tag。
对于多人姿势检测任务,在训练的时候使用了4个hourglass模块,输入大小为512×512,输出大小为128×128,batch size为32,学习速率为2e-4(100K次迭代后降为1e-5).
四、Multi-person Pose Estimation
- 使用堆叠沙漏模型来预测每个身体关节 ("左手腕"、"右肩" 等) 在每个像素定位上的检测分数, 而不考虑个体实例。
- 除了生成全部关键点检测外, 网络还自动将检测分组为个体实例姿态。为此, 网络将在每个关节的像素位置生成一个标记。换句话说, 每个关节热图都有相应的 "标签tag" 热图。 因此, 如果有m个人体关节需要预测, 那么网络将输出总共 2m 通道, m 个通道用于检测和m 个通道 用于分组。
- 为了将检测解析成个体实例, 使用非最大抑制NMS来获取每个关节的峰值检测, 并在相同的像素位置检索其相应的标记(如图3所示)。
- 然后, 我们通过比较检测的标记值和匹配足够接近的标记值, 对身体各部位的检测进行分组。一组检测结果现在形成了一个人的姿势估计。
多人姿势检测与单人姿势检测的区别在于多人的heatmap应具有多个峰值(例如,属于不同人的多个左手腕),而不是单人的单个峰值。为了实现多人姿势检测,网络需要对每个关节点的每个像素位置产生一个标签,也就是说,每个关节点的heatmap对应一个标签heatmap,因此,如果一张图片中待检测的关节点有 m 个,则网络理想状态下会输出 2m 个通道, m 个通道用于定位, m个通道用于分组。
为了将检测结果对应到个人,作者使用非极大值抑制(non-maximun suppression)来取得每个关节heatmap峰值,然后检索其对应位置的标签,再比较所有身体位置的标签,找到足够接近的标签分为一组,这样就将关节点匹配单个人身上,整个过程如下图所示:
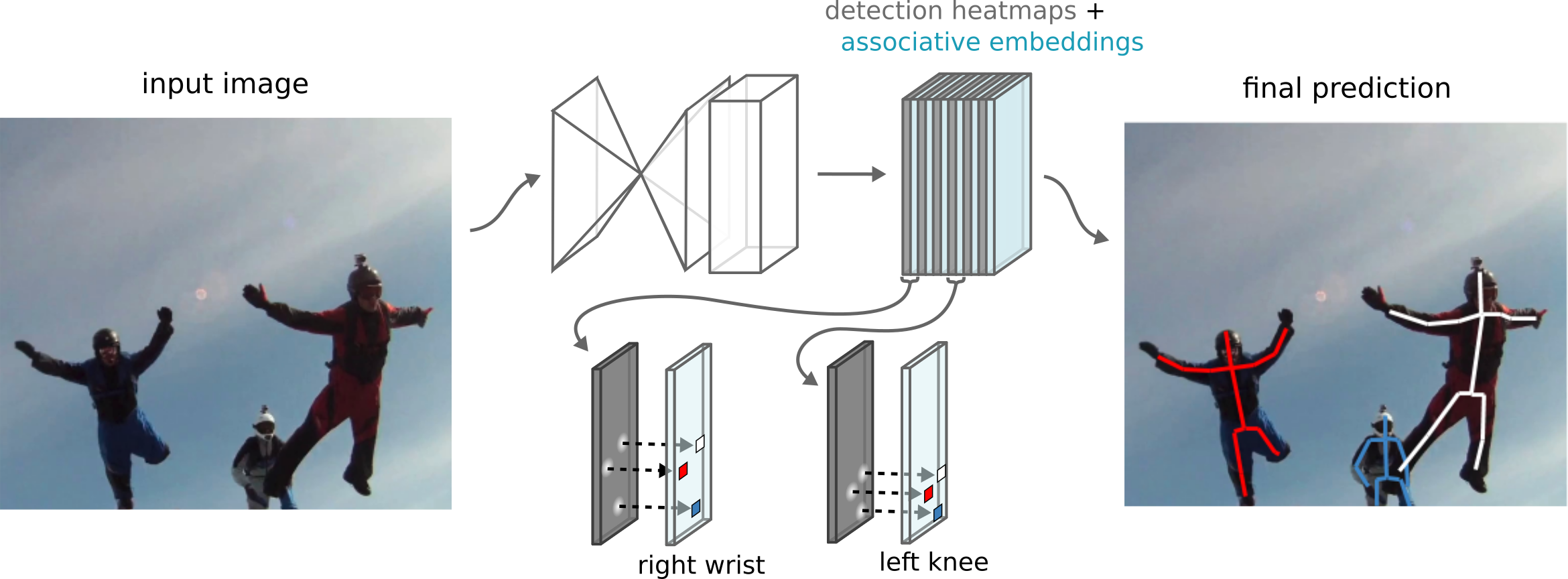
对每个关节点,该网络同步生成检测热图并预测关联性嵌入TAG。本文拿每个关节点取检测结果与其他检测结果进行匹配,具有相同嵌入TAG的关节点检测结果构成最终的单个姿态估计集合。
本文通过比较检测结果的TAG值来对人体部位的检测结果进行分组,并把那些足够接近的进行匹配,一组检测结果构成一个单人的姿态估计。
为了训练该网络,本文实行(impose)一个detection loss检测损失和一个grouping loss分组损失。。
检测损失计算每个预测的检测热图与其“ground truth”热图之间的均方误差,该热图由每个关键点位置的二维高斯激活组成。
分组损失函数评估预测的标签与GT分组的契合程度。
4.1 Detection loss
detection loss使用均方误差,即计算预测的detection heatmap与在关键点加入2D高斯激活的ground truth的heatmap之间的均方误差。
4.2 Grouping loss
grouping loss衡量的是预测的标签和ground truth分组的标签匹配得有多好,具体说,就是检索图片中所有人的所有身体节点的在相应的ground truth位置的标签,然后比较每个人和人之间的标签,同一个人的标签应该相同,反之,不同人的标签应该不同。
为了减少运算量,我们应该避免直接计算每一对关节点之间的损失,相应的,我们对每个人都产生一个reference embedding,reference embedding的生成方法就是对人的关节点的embedding值取平均。有了reference embedding后,对于单个人来说,我们计算每个关节点预测的embedding和reference embedding的平方距离;对于两个不同的人来说,我们比较他们之间的reference embedding,随着它们之间距离的增加,惩罚将以指数方式降为0. 接下来,我们对这一过程进行形式化。
具体而言, 我们为所有人在他们所有身体关节的地面真相位置检索预测的标签; 然后, 我们比较个体内和个体间的标签。个体内的标签应该是一样的, 而个体间的标签应该是不一样的。
为了减少运算量,我们应该避免直接计算每一对关节点之间的损失, 我们为每个每个个体生成一个参考嵌入。这是通过取每个个体关节的输出嵌入的平均值来实现的。在个体内部, 我们计算出每个关节的预测嵌入与参考嵌入之间的平方距离。在两对人之间,将他们的参考嵌入彼此进行比较,并且随着两个标记之间的距离的增加,惩罚将呈指数下降到零。
grouping loss损失函数的定义:
1、{分辨率为W×H}: 第k个关节点的预测热图,这个是经过SHN网络后的预测热图。
2、: 像素位置
对应的标签值(tag value)
3、 给定 个人,ground truth的身体关节点集合为
其中 是第
个人第
个关节点的ground truth像素位置。
4、第n个人的参考嵌入值(reference embedding)定义为:
即第n个人的 K个关键点在真实位置处的TAG值之和的均值
5、分组损失函数:分为两部分。
上式中,前面部分为单个人的损失,后面部分为了两个人之间的损失,这里我有一个不太理解的地方,在损失的第一部分,作者为什么用第 n 个人的每个关节点的embedding与这个人的reference embedding作损失?
答:经过一番思考,将第 个人的每个关节点的embedding与这个人的reference embedding作损失的话会使得所有关节点的embedding“拉”向这个平均值,这样就使得这个人所有关节点的embedding最相近。
总的loss为:
![]()
- 为了产生最后一个最终预测集合,对每个关节点进行迭代。迭代的顺序是先考虑头和躯干而后逐渐像肢体移动。我们从第一个关节点开始,NMS后得到每个超过阈值的关键点。这些关键点组组成了我们待检测人的最初候选池。
- 然后我们考虑后续关节的检测。我们将此关节中的标记与当前人员池中的标记进行比较,并尝试确定它们之间的最佳匹配。
- 只有在特定阈值内,两个标签才能匹配。此外,我们希望优先匹配高可信度检测。因此,执行最大匹配,其中权重由标记距离和检测分数确定。如果任何新的检测不匹配,它将用于启动一个新的person实例。这种情况可能是因为某个特定人体只有手或脚可见。
- 我们在每类关节点上循环匹配,直到每个检测都被匹配到一个人。
- 尽管训练网络来预测所有尺寸大小的人体是可行的,但这存在一些缺陷。额外的容量将被用来学习必要的尺度不变性,而池化后的低分辨率问题将影响小人物的预测精度。
- 有许多潜在的方法可以使用每个尺度的输出来产生最终的姿势预测。我们把制作好的热图平均起来。然后,为了跨尺度组合标签tags,我们将同一点像素位置的标记集合连接成一个向量
(假设m尺度)。解码过程与标量标记值描述的方法没有变化,我们现在只比较矢量距离。
- 有许多潜在的方法可以使用每个尺度的输出来产生最终的姿势预测。我们把制作好的热图平均起来。然后,为了跨尺度组合标签tags,我们将同一点像素位置的标记集合连接成一个向量
关节点的检测与分组原则:
将下一个关节点的TAG与当前被检测人体的预测池的TAG进行比较,确定最优匹配。这两个TAG只有在特定阈值内(fall within a specific threshold)才算匹配。除此之外,置信度高的检测结果将被优先匹配(prioritize matching)。权重最大的一组作为最优匹配,其权重最终通过TAG距离与检测评分来确定。如果新的检测结果不与任何一组个人实例匹配,则开启一个新的个人实例。
这也就解释了为什么会有一只手和一条腿的特殊人体的案例。对人体的每个关节进行循环遍历,直到每一次检测都有了所属的人体案例。其中没有采取任何步骤来确保解剖的正确性(anatomical correctness)或关节对之间的合理空间关系。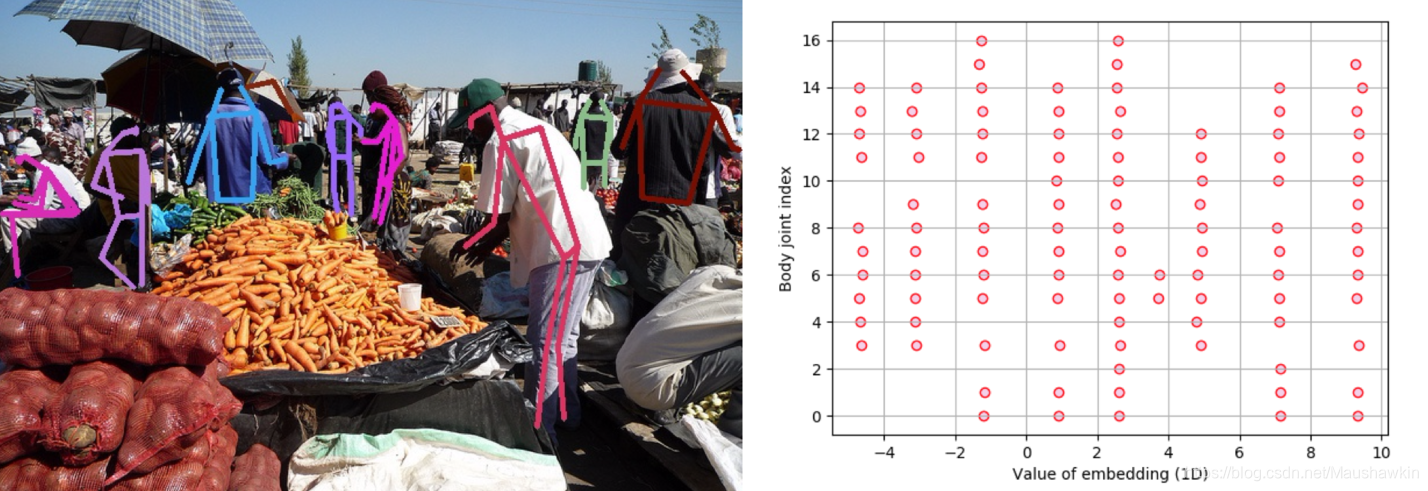
测试结果给人以网络产生的TAG类型与分组很离散分明(琐碎)的印象。。。。
训练一个用来对所有尺度的人进行姿态估计的网络是可行的(feasiable),但却存在一些弊端。
网络需要额外的容量(capacity)来学习必要的尺度变量,对小尺寸人预测的精度会因为pooling后的低分辨率问题而受到影响(suffer due to issues of …)。本文多尺度地在测试阶段评估图像。
大量潜在的方法可以使用各个尺度生成的输出来获得最终的姿态估计集合。本文把生成的热图取均值,然后为了跨尺度(across scales)组合TAG,本文把像素位置上的TAG集合连接到向量v中。
解码过程并没有改为采用标量TAG值进行描述的方法,只是比较向量距离。
五、Instance Segmentation
- 实例分割的目标是检测和分类对象实例, 同时为每个对象提供分割掩码。
- 与多人姿态估计一样, 实例分割是一个联合检测和分组的问题。检测到属于对象类的像素, 然后将与单个对象关联的像素组合在一起。
- 给定输入图像, 我们使用堆叠沙漏网络生成两个热图, 一个用于检测, 一个用于标记。检测热图在每个像素处给出检测分数,指示该像素是否属于对象类别的任何实例,即检测热图从背景分割前景。同时,标记热图标记每个像素,使得属于同一对象实例的像素具有相似的标记。
- 训练网络
- 通过将预测的热图与真值热图 (所有实例掩码的并集) 进行比较来监督检测热图。损失是两个热图间的MeanSquareError。
- 通过施加一个损耗来监督标记热图,该损耗鼓励标记在一个对象实例中相似,在不同实例中不同。无需对实例分段掩码中的每个像素进行比较。相反, 我们随机抽取来自每个对象实例的一小部分像素, 并对一组采样像素进行成对比较。
- 形式上, 让
是一个预测的
标记热图。x表示像素位置, h(x) 标记在该位置处的标记值, 让
是在 n个对象实例中随机采样的一组位置。分组损失
被定义为

- 对网络的输出进行解码
- 我们首先对detection通道的热图进行阈值, 以生成二进制掩码。
- 然后,我们看看这个掩码中标记tags的分布。我们计算标记的直方图,并执行非最大抑制,以确定一组值,用作每个对象实例的标识符。然后,将检测掩码中的每个像素分配给具有最接近标记值的对象。参见图5了解此过程的说明

-
- 为了产生实例分段,我们将网络输出解码如下:首先,我们在检测热图上设置阈值,得到的二进制掩码用于获取一组标签值。通过查看标签tags的分布,可以确定每个实例的识别标签,并将每个激活像素的标签与最近的识别匹配。
- 注意,从一个对象类别推广到多个对象类别是很简单的:我们只是为每个对象类别输出一个检测热图和一个标记热图。与多人姿态一样,尺度不变性问题值得考虑。与其训练网络在每个可能的尺度上识别对象实例的外观,不如在多个尺度上进行评估,并以与姿势估计类似的方式组合预测。
六、Experiments:(仅讨论人体姿态估计部分)
{Dataset}:
MPII: 包括25k张图片,40k标记人体(3/4可用于训练)
从测试集中获取的1758组多人集合按照[45]的主题思路(set as outlined)进行设置。
该组通常作为一幅特定图片中总体人数的子集,因此需要提供一些信息来保证正确预测了目标,这些信息包括了B-Box和一些用于说明所占区域的标量信息。
而关于人体数量或是单个人体比例的信息并未被提供。
最终按[45]的标准计算关节点检测结果的AP。
MS-COCO[1]:包括60k张训练图片,多于100k标记人体。
本文在2个测试集上进行实验:test-dev(development test set) & test-std(standard test set)。
本文采用官方的标准进行评测:AP、AR(该评测方法与对象检测的评测标准很像,除了其评分是基于关键点的距离,而非b-box的的重叠)。
{Implementation}:
该网络由4个级联沙漏模块组成,输入尺寸为512×512,输出尺寸为128×128。Batch尺寸为32,学习率为2e-4(每100k次迭代后下降1e-5)[2,tensorflow]。
AE损失函数由一个因子进行加权,该因子为1e-3并和检测热图的MSE损失有关。该损失被掩盖用以忽略被稀疏注释的人群。
测试阶段时输入图片在多个尺度上运行,输出的检测热图被跨尺度取均值,而跨尺度的TAG被连接到更高维度的TAG。
因为MPII与MS-COCO的标准都对关键点的精确定位很敏感,依据[6],本文采用在同样数据集上训练的[40]单人姿态模型来优化预测结果。
{MPII Results}:
关联式嵌入证明了引导网络将关键点分组成单个人体是一种有效的策略。其无需任何有关图像中所出现人体个数的假设,但需要提供一个网络机制来表达对共同任务的困惑。例如,如果2个人的相同关节点在极小的像素位置上产生重叠,那么预测的AE将是这2个人各自(respective)TAG间的一个TAG。
通过嵌入热图的可视化,本文可以更好地了解(get a better sense of)AE的输出。
严重遮挡与检测关节点间距过近等情况将使单人姿态的分析(parse out)过程更加困难,于是本文特别关注人体重叠严重时预测嵌入值的差异。
{MS-COCO Results}:
在2个测试集上本文的方法都取得了最优的表现结果。
网络所产生的典型故障是因为(stem from)杂乱场景中关节点中的重叠与遮挡。
从模型在多尺度应用与采用单人姿态估计器优化上,本文各pipline消融版本的性能展现了较好的贡献。
本文还对MS-COCO进行了额外的实验,以评估(gauge)检测与分组的相对难度,即哪一部分是该系统的主要瓶颈。
该系统在一组500张训练图像上进行了评估。评估中,采用GT标注的检测结果来代替预测所得的检测结果,但TAG依然采用预测值,这使得AP从59.2提升到了94.0。该效果体现了关键点检测是该系统的主要瓶颈,即网络已学到了高质量的分组模型。预测所得的TAG值的定性分析也支持了该结论。
从下图可见TAG被很好的分隔开,而且解码分组也很简单。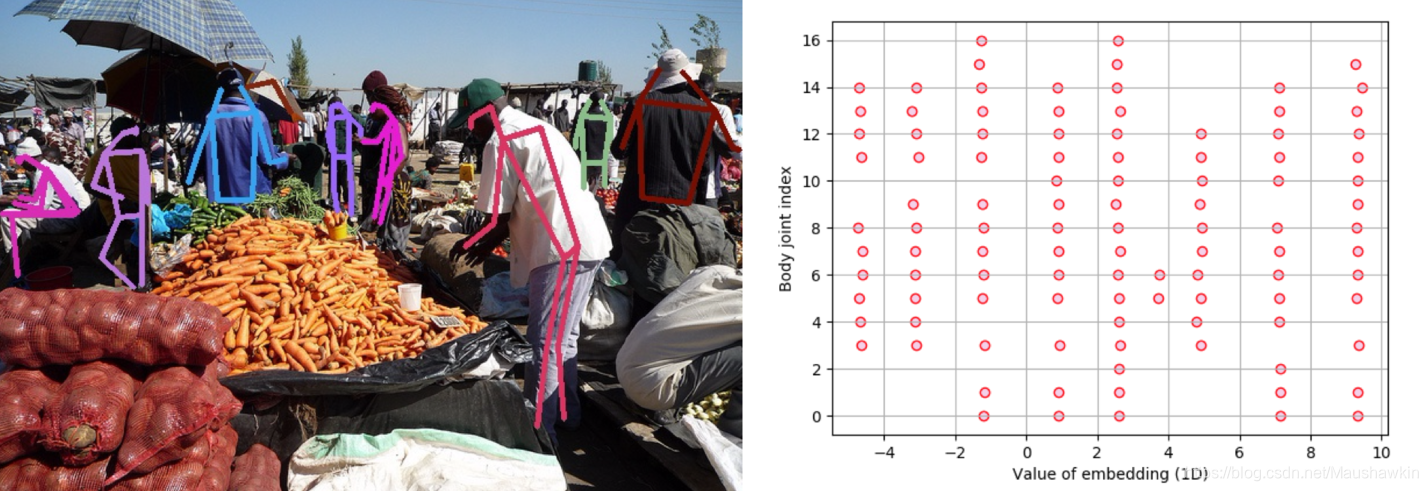
七、Conclusion:
本文介绍了Associative Embedding(关联性嵌入)来对一个卷积神经网络进行监督,其可以同步地生成检测结果并进行分组。
本文验证了AE方法在训练多人姿态估计与实例分割上的可行性,并在姿态估计中获得了当前最优结果。
该方法也可被用于视频信息的多目标跟踪等其他视觉问题。
给定任意可以生成像素级预测结果的网络,关联性嵌入损失函数都可以被实现,因此其易于与其他当前较好的框架进行结合。