内容简介
项目名称:工业离散制造过程中的符合率
任务名称:数据介绍
任务简介:了解数据的来源、数据的内容,学会查看数据等等数据的指标。
详细说明:如何观察数据以及了解数据数据背景介绍、来源于工业实际生产环境,CCF指定专业大数据及人工智能竞赛平台-DataFountain 工业离散制造质量符合率预测,数据已经脱敏处理过,不涉及商业秘密。
第一眼就要看到数据的方向,这个数据是干什么的?如何做?分类还是回归?
数据不大,感兴趣的可以下来看看
数据背景介绍
来源:工业生产实际–西门子公司
官网在此:https://www.datafountain.cn/competitions/351/datasets
第一节课已经讲了各个字段什么的,不啰嗦了。
数据准备工作
是csv格式的,导入很简单:
import pandas as pd
train=pd.read_csv("data/first_round_training_data. csv")
train. head()#显示前五行
数据细看
给出了拿到数据要干什么的参考步骤:
1、有哪些
2、干什么
3、有什么用
4、数据的分布
5、数据的EDA
6、具体业务具体分析–如乘一个业务你很熟悉的话那这个就不是问题了,你自己应该知道要做什么。
当数据量很大的时候,我们还需要使用一些特定的工具或者平台来进行处理:dask、spark、集群。
判断是否有空,并统计个数
train_data.isnull().sum()#对所有列判断是否有空,然后再统计个数
train_data.Parameter1.isnull().sum()#对Parameter1列判断是否有空,然后再统计个数
查看数据类型
#查看数据类型
train_data.dtypes
查看数据大小,这里的大小是指数据文件的大小,当然也包含记录的条数(样本个数,这里是6000),字段类型,字段长度等信息
#查看数据大小
train_data.info()

利用EDA工具进行数据初始分析
import pandas_profiling as ppf
ppf.ProfileReport(train_data)
工具安装方法:pip install pandas profiling
下面是结果:

这里是一些warning

这个是我们需要处理的重点,这里提示数据分布不均匀。
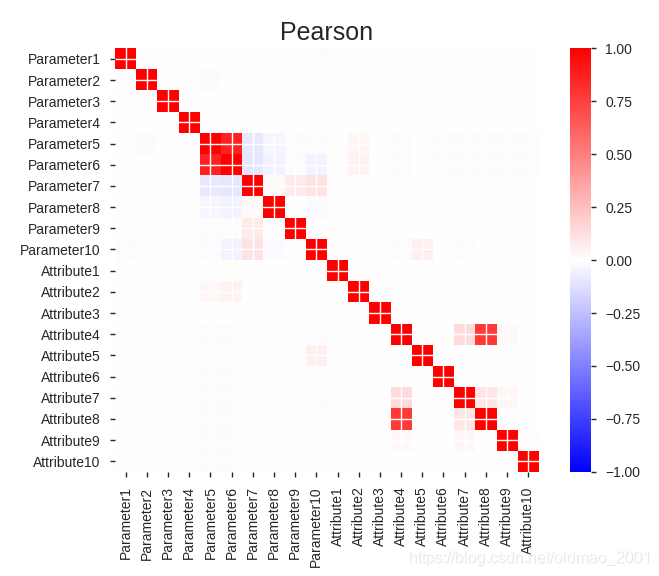
这里是相关性,中间对角线是自己和自己,所以显示自相关性很高。其他的Attribute4和Attribute8相关性较大。
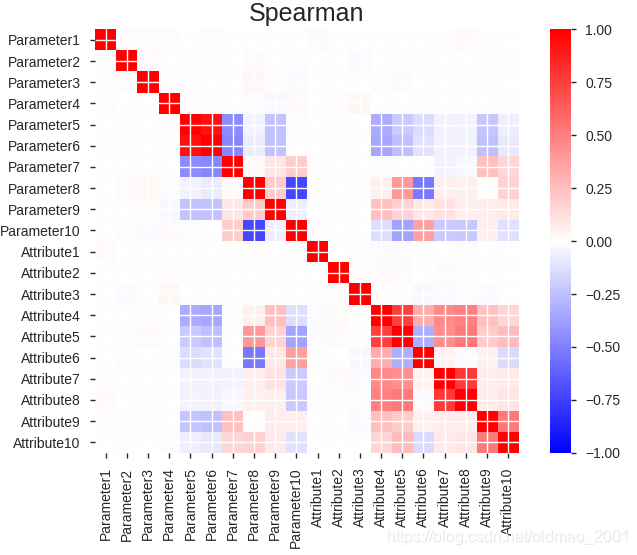
这里是自相关性有两个:
1、Pearson相关系数
最常用的相关系数,又称积差相关系数,取值-1到1,绝对值越大,说明相关性越强。该系数的计算和检验为参数方法,适用条件如下: (适合做连续变量的相关性分析)
(1)两变量呈直线相关关系,如果是曲线相关可能不准确。
(2)极端值会对结果造成较大的影响
(3)两变量符合双变量联合正态分布。
2、Spearman秩相关系数
对原始变量的分布不做要求,适用范围较Pearson相关系数广,即使是等级资料,也可适用。但其属于非参数方法,检验效能较Pearson系数低。(适合含有等级变量或者全部是等级变量的相关性分析)
看完训练数据后,再自己看看测试数据即可。
