本次实验内容为餐饮订单数据的分析,数据请见:https://pan.baidu.com/s/1tL7FE5lxs-gb6Phf8XRu_Q,文件夹:data_analysis,下面的文件:job_info.csv 本次实验主要是对python中的数据进行基本操作。
代码为:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pandas as pd
import re
# 招聘数据探索与分析
# 1. 读取数据并存为一个名叫job_info的数据框。此处encoding='GBK'语句是为了读取中文
job_info = pd.read_csv('data_analysis/job_info.csv', encoding='GBK', header=None)
# 2. 将列命名为:['公司', '岗位', '工作地点', '工资', '发布日期']。
job_info.columns = ['公司', '岗位', '工作地点', '工资', '发布日期']
# 3. 哪个岗位招聘需求最多?
job_info['岗位'].value_counts().idxmax()
# 4. 取出9月3日发布的招聘信息。
job_info['发布日期'].value_counts() #频次统计
job_info[job_info['发布日期'] == '09-03']
job_info.loc[job_info['发布日期'] == '09-03', :]
# 5. 找出工作地点在深圳的数据分析师招聘信息。
index1 = job_info['工作地点'].apply(lambda x: '深圳' in x) #工作地点包含 '深圳'这两个字的索引
index2 = job_info['岗位'] == '数据分析师'
job_info.loc[index1 & index2, :]
# 6. 取出每个岗位的最低工资与最高工资,单位为“元/月”,若招聘信息中无工资数据则无需处理。(如2-2.5万/月,则最低工资为20000,最高工资为25000。)
job_info['工资'].str[-3].value_counts() #只处理一下按年和按月给工资的
#string = '2-3.5万/月'
def get_number(string =None):
try:
if string[-3] == '万':
x = [float(i)*10000 for i in re.findall('\d+\.{0,1}\d*', string)]
elif string[-3] == '千':
x = [float(i)*1000 for i in re.findall('\d+\.{0,1}\d*', string)]
if string[-1] == '年':
x = [i/12 for i in x]
return x
except:
return None
job_info['最低月薪']=job_info['工资'].apply(get_number).str[0]
job_info['最高月薪']=job_info['工资'].apply(get_number).str[1] #apply只能加函数名,不能加参数
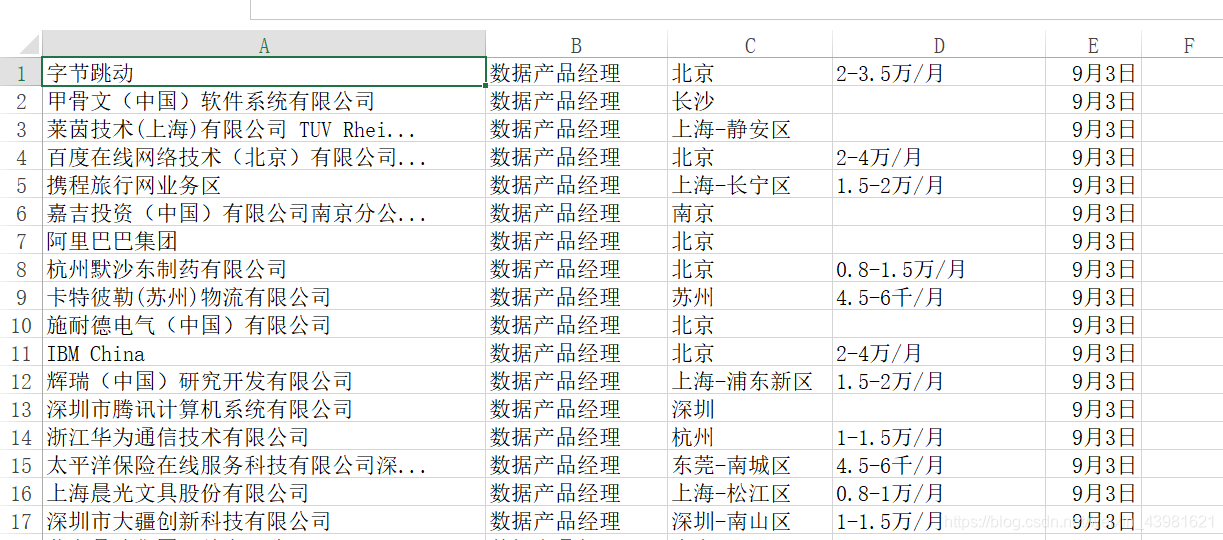
文件‘job_info.csv’中的数据截图为:
运行结果如图: