因本人刚开始写博客,学识经验有限,如有不正之处望读者指正,不胜感激;也望借此平台留下学习笔记以温故而知新。这个系列主要是Python数据分析基础的学习笔记。
原始Excel文件:sales_2013.xlsx
- january_2013
- february_2013
- march_2013
读取Excel基本信息
# 读取Excel基本信息
#!/usr/bin/env python3
import sys
from xlrd import open_workbook
input_file = sys.argv[1]
workbook = open_workbook(input_file)
print('Number of worksheets:', workbook.nsheets)
for worksheet in workbook.sheets():
print("Worksheet name:", worksheet.name, "\tRows:", worksheet.nrows, "\tColumns:", worksheet.ncols)
使用基础Python和xlrd、xlwt模块读写Excel文件
# 使用基础Python和xlrd、xlwt模块读写Excel文件
#!/usr/bin/env python3
import sys
from xlrd import open_workbook
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
for row_index in range(worksheet.nrows):
for column_index in range(worksheet.ncols):
output_worksheet.write(row_index, column_index, \
worksheet.cell_value(row_index, column_index))
output_workbook.save(output_file)
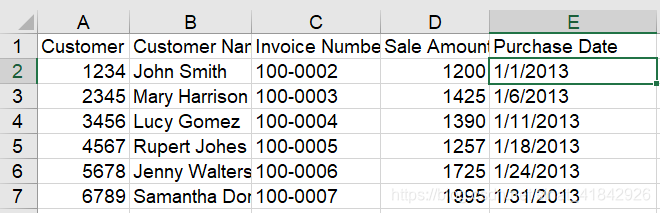
对日期列进行的相应格式处理
# 对日期列进行相应格式处理
#!/usr/bin/env python3
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
for row_index in range(worksheet.nrows):
row_list_output = []
for col_index in range(worksheet.ncols):
if worksheet.cell_type(row_index, col_index) == 3:
date_cell = xldate_as_tuple(worksheet.cell_value\
(row_index, col_index),workbook.datemode)
print(date_cell)
date_cell = date(*date_cell[0:3]).strftime\
('%m-%d-%Y')
print(date_cell)
row_list_output.append(date_cell)
output_worksheet.write(row_index, col_index, date_cell)
else:
non_date_cell = worksheet.cell_value\
(row_index,col_index)
row_list_output.append(non_date_cell)
output_worksheet.write(row_index, col_index,\
non_date_cell)
output_workbook.save(output_file)
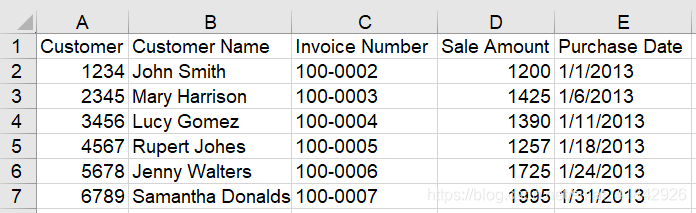
使用pandas读取Excel中的数据
# 使用pandas读取Excel中的数据
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file, sheetname='january_2013')
writer = pd.ExcelWriter(output_file)
data_frame.to_excel(writer, sheet_name='jan_13_output', index=False)
writer.save()

筛选出january_2013表中Sale>1400的行
# 筛选出january_2013表中Sale>1400的行
#!/usr/bin/env python3
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
sale_amount_column_index = 3
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
data = []
header = worksheet.row_values(0) # 标题行
data.append(header)
for row_index in range(1,worksheet.nrows):
row_list = []
sale_amount = worksheet.cell_value\
(row_index, sale_amount_column_index)
if sale_amount > 1400.0:
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value\
(row_index,column_index)
cell_type = worksheet.cell_type\
(row_index, column_index)
if cell_type == 3:
date_cell = xldate_as_tuple\
(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3])\
.strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index, output_list in enumerate(data):
for element_index, element in enumerate(output_list):
output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)


用pandas筛选出符合某个条件的行,例如 Sale>1400的行
# 用pandas筛选出符合某个条件的行,例如 Sale>1400的行
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file, 'january_2013', index_col=None)
data_frame_value_meets_condition = \
data_frame[data_frame['Sale Amount'].astype(float) > 1400.0]
writer = pd.ExcelWriter(output_file)
data_frame_value_meets_condition.to_excel(writer, sheet_name='jan_13_output',\
index=False)
writer.save()

筛选出购买日期属于一个特定集合的表格
# 筛选出购买日期属于一个特定集合的表格
#!/usr/bin/env python3
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
important_dates = ['01/24/2013', '01/31/2013']
purchase_date_column_index = 4
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
data = []
header = worksheet.row_values(0)
data.append(header)
for row_index in range(1, worksheet.nrows):
purchase_datetime = xldate_as_tuple(worksheet.cell_value(row_index, purchase_date_column_index),workbook.datemode)
purchase_date = date(*purchase_datetime[0:3]).strftime('%m/%d/%Y')
row_list = []
if purchase_date in important_dates:
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index, column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index, output_list in enumerate(data):
for element_index, element in enumerate(output_list):
output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)

pandas提供了isin 函数,可以用来检验一个特定值是否在一个列表中
# pandas提供了isin 函数,可以用来检验一个特定值是否在一个列表中
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
date_frame = pd.read_excel(input_file,'january_2013',index_col=None)
important_dates = ['01/24/2013','01/31/2013']
date_frame_value_in_set = date_frame[date_frame['Purchase Date'].isin(important_dates)]
writer = pd.ExcelWriter(output_file)
date_frame_value_in_set.to_excel(writer,sheet_name='jan_2013_output',index=False)
writer.save()

采用匹配模式,如筛选出客户姓名包含一个特定模式的形式
# 采用匹配模式,如筛选出客户姓名包含一个特定模式的形式
import sys
import re
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
pattern = re.compile(r'(?P<my_pattern>^J.*)')
customer_name_column_index = 1
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
data = []
header = worksheet.row_values(0)
data.append(header)
for row_index in range(1,worksheet.nrows):
row_list = []
if pattern.search(worksheet.cell_value(row_index,customer_name_column_index)):
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)

pandas筛选客户姓名以大写字母J开头的那些行
# pandas筛选客户姓名以大写字母J开头的那些行
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
date_frame = pd.read_excel(input_file,'january_2013',index_col=None)
date_frame_value_matches_pattern = date_frame[date_frame['Customer Name'].str.startswith('J')]
writer = pd.ExcelWriter(output_file)
date_frame_value_matches_pattern.to_excel(writer,sheet_name='Jan_13_output',index=False)
writer.save()

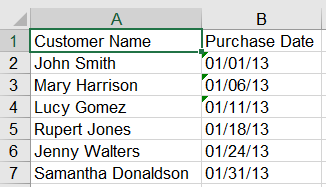
用列索引值,保留Customer Name和Purchase Date这两列
# 用列索引值,保留Customer Name和Purchase Date这两列
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
my_columns = [1,4]
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
data = []
for row_index in range(worksheet.nrows):
row_list = []
for column_index in my_columns:
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
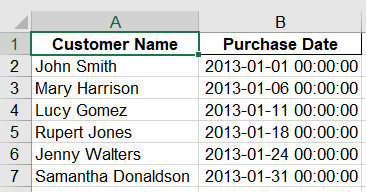
用pandas进行选取特定列
# 用pandas进行选取特定列
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file,'january_2013',index_col=None)
date_frame_column_by_index = data_frame.iloc[:,[1,4]]
writer = pd.ExcelWriter(output_file)
date_frame_column_by_index.to_excel(writer,sheet_name='jan_13_output',index=False)
writer.save()
用列标题,保留Customer Name和Purchase Date这两列
# 用列标题,保留Customer Name和Purchase Date这两列
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
my_column = ['Customer ID', 'Purchase Date']
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
data = [my_column]
header_list = worksheet.row_values(0)
header_index_list = []
for header_index in range(len(header_list)):
if header_list[header_index] in my_column:
header_index_list.append(header_index)
for row_index in range(1,worksheet.nrows):
row_list = []
for column_index in header_index_list:
cell_date = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_date,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%d/%m/%y')
row_list.append(date_cell)
else:
row_list.append(cell_date)
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)

用pandas基于列标题选取特定列
# 用pandas基于列标题选取特定列
import sys
import pandas as pd
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file,'january_2013',index_col=None)
data_frame_column_by_name = data_frame.loc[:,['Customer ID','Purchase Date']]
writer = pd.ExcelWriter(output_file)
data_frame_column_by_name.to_excel(writer,sheet_name='jan_2013_output',index=False)
writer.save()
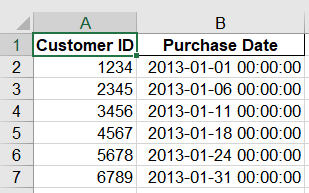
在工作表所有子表中筛选出销售额大于$2000.00的所有行
# 在工作表所有子表中筛选出销售额大于$2000.00的所有行
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('filtered_rows_all_worksheets')
sales_column_index = 3
threshold = 2000.0
first_worksheet = True
with open_workbook(input_file) as workbook:
data = []
for worksheet in workbook.sheets():
if first_worksheet:
header_row = worksheet.row_values(0)
data.append(header_row)
first_worksheet = False
for row_index in range(1,worksheet.nrows):
row_list = []
sale_amount = worksheet.cell_value(row_index,sales_column_index)
if sale_amount > threshold:
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
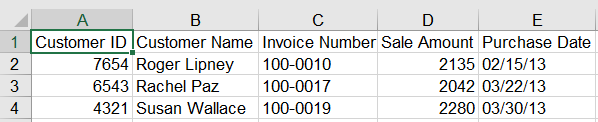
Pandas中通过在字典的键和值之间迭代,可以使用工作簿中所有的数据
# Pandas中通过在字典的键和值之间迭代,可以使用工作簿中所有的数据
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file,sheetname=None,index=None)
row_output = []
for worksheet_name,data in data_frame.items():
row_output.append(data[data['Sale Amount'].astype(float)>2000.0])
filtered_rows = pd.concat(row_output,axis=0,ignore_index=True)
writer = pd.ExcelWriter(output_file)
filtered_rows.to_excel(writer,sheet_name='sale_amount_gt2000',index=False)
writer.save()

从工作表所有子表中选取一组列
# 从工作表所有子表中选取一组列
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('selected_columns_all_worksheets')
my_columns = ['Customer Name','Sale Amount']
first_worksheet = True
with open_workbook(input_file) as workbook:
data = [my_columns]
index_of_cols_to_keep = []
for worksheet in workbook.sheets():
if first_worksheet:
header = worksheet.row_values(0)
for column_index in range(len(header)):
if header[column_index] in my_columns:
index_of_cols_to_keep.append(column_index)
first_worksheet = False
for row_index in range(1,worksheet.nrows):
row_list = []
for column_index in index_of_cols_to_keep:
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
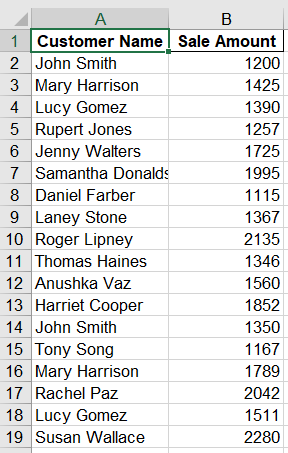
使用pandas选取指定列
# 使用pandas选取指定列
import sys
import pandas as pd
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file,sheetname=None,index=None)
column_output = []
for worksheet_name,data in data_frame.items():
column_output.append(data.loc[:,['Customer Name','Sale Amount']])
selected_column = pd.concat(column_output,axis=0,ignore_index=True)
writer = pd.ExcelWriter(output_file)
selected_column.to_excel(writer,sheet_name='selected_column_all_worksheets',index=False)
writer.save()
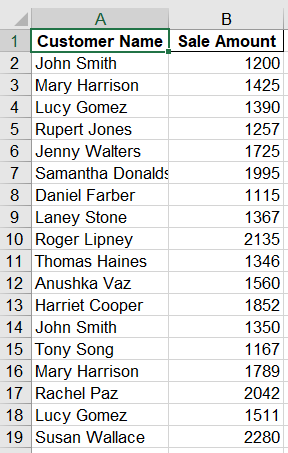
从第一个和第二个工作表中筛选出销售额大于$1900.00的那些行
# 从第一个和第二个工作表中筛选出销售额大于$1900.00的那些行
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('set_of_worksheets')
my_sheets = [0,1]
threshold = 1900.0
sales_column_index = 3
first_worksheet = True
with open_workbook(input_file) as workbook:
data = []
for sheet_index in range(workbook.nsheets):
if sheet_index in my_sheets:
worksheet = workbook.sheet_by_index(sheet_index)
if first_worksheet:
header_row = worksheet.row_values(0)
data.append(header_row)
first_worksheet = False
for row_index in range(1,worksheet.nrows):
row_list = []
sale_amount = worksheet.cell_value(row_index,sales_column_index)
if sale_amount > threshold:
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)

pandas在工作簿中选择一组工作表的操作
# pandas在工作簿中选择一组工作表的操作
import sys
import pandas as pd
input_file = sys.argv[1]
output_file = sys.argv[2]
my_sheets = [0,1]
threshold = 1900.0
data_frame = pd.read_excel(input_file,sheetname=my_sheets,index_col=None)
row_list = []
for worksheet_name,data in data_frame.items():
row_list.append(data[data['Sale Amount'].astype(float)>threshold])
filtered_rows = pd.concat(row_list,axis=0,ignore_index=True)
writer = pd.ExcelWriter(output_file)
filtered_rows.to_excel(writer,sheet_name='set_of_worksheets',index=False)
writer.save()

原始Excel文件:sales_2014.xlsx,在原始文件sales_2013.xlsx基础上将时间直接由2013替换为2014即可。
原始Excel文件:sales_2015.xlsx,在原始文件sales_2013.xlsx基础上将时间直接由2013替换为2015即可。
读取一个文件夹中工作簿的数量,每个工作簿中工作表的数量,以及每个工作表中行与列的数量
# 读取一个文件夹中工作簿的数量,每个工作簿中工作表的数量,以及每个工作表中行与列的数量
import glob
import sys
import os
from xlrd import open_workbook
intput_directory = sys.argv[1]
workbook_count = 0
for input_file in glob.glob(os.path.join(intput_directory,'*.xlsx')):
workbook = open_workbook(input_file)
print('Workbook: %s' % os.path.basename(input_file))
print('Number of worksheets: %d' % workbook.nsheets)
for worksheet in workbook.sheets():
print('Worksheet name:',worksheet.name,'\t rows:',worksheet.nrows,'\t lolumns:',worksheet.ncols)
workbook_count += 1
print('Number of Excel workbooks: %d' % (workbook_count))
将多个工作簿中所有工作表的数据垂直连接成一个输出文件
# 将多个工作簿中所有工作表的数据垂直连接成一个输出文件
import sys
import os
import glob
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
from datetime import date
input_folder = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('add_data_all_workbooks')
data = []
first_worksheet = True
for input_file in glob.glob(os.path.join(input_folder,'*.xlsx')):
print(os.path.basename(input_file))
with open_workbook(input_file) as workbook:
for worksheet in workbook.sheets():
if first_worksheet:
header_row = worksheet.row_values(0)
data.append(header_row)
first_worksheet = False
for row_index in range(1,worksheet.nrows):
row_list = []
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
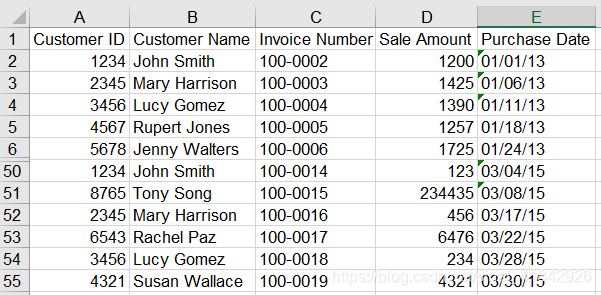
pandas提供了concat函数来连接数据框
# pandas提供了concat函数来连接数据框
import pandas as pd
import sys
import os
import glob
input_path = sys.argv[1]
output_file = sys.argv[2]
all_workbooks = glob.glob(os.path.join(input_path,'*.xls*'))
data_frame = []
for workbook in all_workbooks:
all_worksheets = pd.read_excel(workbook,sheetname=None,index_col=None)
for worksheet_name,data in all_worksheets.items():
data_frame.append(data)
all_data_concatenated = pd.concat(data_frame,axis=0,ignore_index=True)
writer = pd.ExcelWriter(output_file)
all_data_concatenated.to_excel(writer,sheet_name='all_data_all_workbooks',index=False)
writer.save()
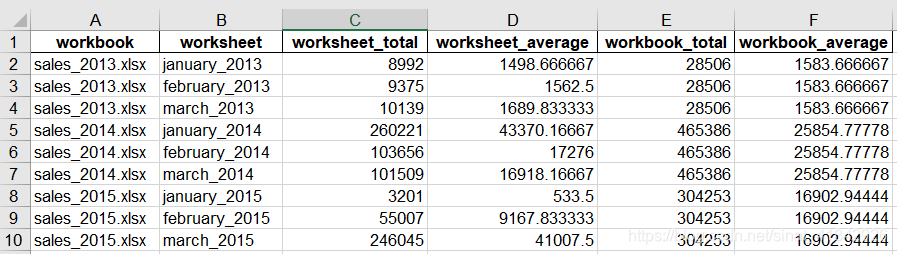
多个工作簿计算工作表级别和工作簿级别的统计量
# 多个工作簿计算工作表级别和工作簿级别的统计量
import glob
import os
import sys
from xlrd import open_workbook
from xlwt import Workbook
input_folder = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('sums_and_averages')
all_data = []
sales_column_index = 3
header = ['workbook','worksheet','worksheet_total','worksheet_average',\
'workbook_total','workbook_average']
all_data.append(header)
for input_file in glob.glob(os.path.join(input_folder,'*.xls*')):
with open_workbook(input_file) as workbook:
list_of_totals = []
list_of_numbers = []
workbook_output = []
for worksheet in workbook.sheets():
total_sales = 0
number_of_sales = 0
worksheet_list = []
worksheet_list.append(os.path.basename(input_file))
worksheet_list.append(worksheet.name)
for row_index in range(1,worksheet.nrows):
try:
total_sales += float(str(worksheet.cell_value(row_index,sales_column_index)).strip('$').replace(',',''))
number_of_sales += 1
except:
total_sales += 0
number_of_sales += 0
average_sales = '%.2f' % (total_sales / number_of_sales)
worksheet_list.append(total_sales)
worksheet_list.append(float(average_sales))
list_of_totals.append(total_sales)
list_of_numbers.append(float(number_of_sales))
workbook_output.append(worksheet_list)
workbook_total = sum(list_of_totals)
workbook_average = sum(list_of_totals) / sum(list_of_numbers)
for list_element in workbook_output:
list_element.append(workbook_total)
list_element.append(workbook_average)
all_data.extend(workbook_output)
for list_index,output_list in enumerate(all_data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
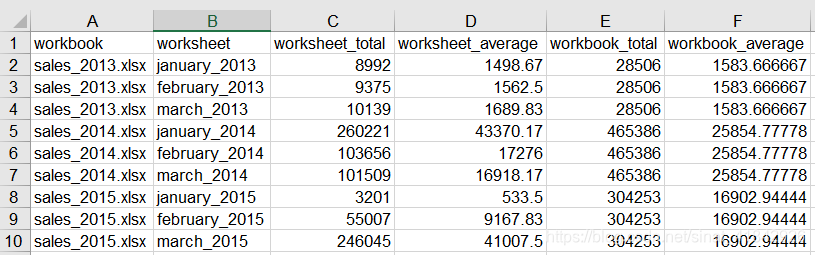
pandas在工作簿级别和工作表级别计算统计量中的使用
# pandas在工作簿级别和工作表级别计算统计量中的使用
import pandas as pd
import sys
import os
import glob
input_path = sys.argv[1]
output_file = sys.argv[2]
all_workbooks = glob.glob(os.path.join(input_path,'*.xls*'))
data_frames = []
for workbook in all_workbooks:
all_worksheets = pd.read_excel(workbook,sheetname=None,index_col=None)
workbook_total_sales = []
workbook_number_of_sales = []
worksheet_data_frames = []
worksheets_data_frame = None
workbook_data_frame = None
for worksheet_name,data in all_worksheets.items():
total_sales = pd.DataFrame([float(str(value).strip('$').replace(',','')) \
for value in data.loc[:,'Sale Amount']]).sum()
number_of_sales = len(data.loc[:,'Sale Amount'])
average_sales = pd.DataFrame(total_sales / number_of_sales)
workbook_total_sales.append(total_sales)
workbook_number_of_sales.append(number_of_sales)
data = {'workbook': os.path.basename(workbook),
'worksheet': worksheet_name,
'worksheet_total': total_sales,
'worksheet_average': average_sales}
worksheet_data_frames.append(pd.DataFrame(data,\
columns=['workbook','worksheet','worksheet_total','worksheet_average']))
worksheets_data_frame = pd.concat(worksheet_data_frames,axis=0,ignore_index=True)
workbook_total = pd.DataFrame(workbook_total_sales).sum()
workbook_total_number_of_sales = pd.DataFrame(workbook_number_of_sales).sum()
workbook_average = pd.DataFrame(workbook_total / workbook_total_number_of_sales)
workbook_stats = {'workbook': os.path.basename(workbook),
'workbook_total': workbook_total,
'workbook_average': workbook_average}
workbook_stats = pd.DataFrame(workbook_stats,columns=['workbook','workbook_total','workbook_average'])
workbook_data_frame = pd.merge(worksheets_data_frame,workbook_stats,on='workbook',how='left')
data_frames.append(workbook_data_frame)
all_data_concat = pd.concat(data_frames,axis=0,ignore_index=True)
writer = pd.ExcelWriter(output_file)
all_data_concat.to_excel(writer,sheet_name='sums_and_averages',index=False)
writer.save()