经过RCNN和Fast RCNN的积淀,Ross B. Girshick在2016年提出了新的Faster RCNN,在结构上,Faster RCN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。

Faster R-CNN
从RCNN到Fast R-CNN,再到本文的Faster R-CNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。剔除了大部分的计算冗余,大部分训练过程在GPU中完成,进一步提高了运行速度。

Faster R-CNN主要用两个模块组成:
- 第一个模块是深层的全卷积网络用于区域推荐
- 第二个模块是Fast R-CNN detector.
Faster R-CNN可以看做”区域生成网络+fast R-CNN”的系统,用区域生成网络代替Fast-RCNN中的Selective Search方法,来产生一堆候选区域。
论文中着重解决了下面问题:
- 如何设计/训练 区域生成网络
- 如何整合区域生成网络和Fast R-CNN网络共享特征提取网络
侯选区域生成网络
当前检测网络最耗时的地方在proposals选取。现在用的最多的时Selective Search,这在测试过程中会耗费较多的时间。
论文提出了使用CNN来推荐候选区域,称之为RPNs(Region Proposal Networks)。作者观察到区域检测器(例如Fast R-CNN)的卷积层后的特征映射(feature map)可用户RPNs生成侯选区域.在特征映射的基础上向后添加几层卷积层构成区域推荐网络。这是一个FCN(fully convolutional network,全卷积网络).
RPN网络主要用于生成region proposals,首先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),即是物体or不是物体,所以这是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal(注:这里的较精确是相对于后面全连接层的再一次box regression而言)
侯选区域生成网络架构
RPN网络基本设想是:在提取好的特征图上,通过一个滑动窗口获取特征向量,然后输出到两个全连接层:
- 一个是box-regression layer(reg)
- 另一个是 box-classification layer(cls).

下图中可以看到,在feature map上会有一个sliding window,这个sliding window会遍历feature map上的每一个点,并且在每个点上配置k个anchor boxes。这k个anchor boxes就是用于提取feature map上的特征,但是这样提取出来效果不是很好,所以后面会接一个分类器和一个bbox回归,这样就能修正检测位置了。

侯选区域生成网络(Region Proposal Networks,RPN),RPN网络接收任意大小的图片作为输入,输出一组目标侯选矩形框,并带有目标分数.
Anchors
在每一个滑动窗口的位置,我们同时预测k个推荐区域,故reg层有4k个输出(每个侯选区域是一个元素个数为4的元组)。cls层输出2k个得分(即对每个推荐区域是目标/非目标的估计概率)
k个推荐区域对应着k个参考框的参数形式,我们称之为anchors.每个anchor以当前滑动窗口的中心为中心,并与尺度和长宽比相关。默认地我们使用3种尺度和3种长宽比,对于每个滑动位置就有k=9个anchor。对于大小为W×H(例如2,400)的卷积特征映射,总共有W*H*k个anchor。
特征可以看做一个尺度51*39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{128**2,256**2,512**2}× 三种长宽比例{1:1,1:2,2:1},下图示出51*39个anchor中心,以及9种anchor示例。
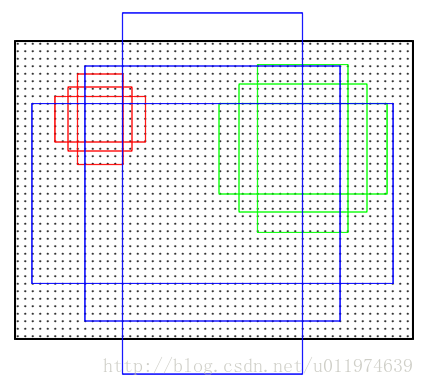
分类层(cls_score)输出每一个位置上,9个anchor属于前景和背景的概率;窗口回归层(bbox_pred)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数。对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;窗口回归层从256维特征中输出4个平移缩放参数。
就局部来说,这两层是全连接网络;就全局来说,由于网络在所有位置(共51*39个)的参数相同,所以实际用尺寸为1×1的卷积网络实现。需要注意的是:并没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正。
侯选区域生成网络的训练
训练数据
对每个anchor给定标签选项,认定两种anchors为正样本:
- anchor/anchors与ground-truth box有着最高的IoU记为正样本
- 剩下的anchor/anchors与任何ground-truth box的IoU大于0.7记为正样本,IoU小于0.3,记为负样本
- 剩下的anchor/anchors记为非正样本,对训练没有贡献,不使用
同一个ground-truth可以确定多个anchors.
损失函数
这里使用的损失函数和Fast R-CNN内的损失函数原理类似,同时最小化两种代价:

- RPN可以BP算法和SGD算法完成end-to-end训练。每个mini-batch的数据包含着一张图片上的多个正样本和负样本。
- 在网络参数初始化上,前面的卷积层使用预训练的ImageNet的网络参数,新添加的层使用随机的高斯分布初始化权重.
- 在前60K的mini-batch上我们使用0.001的学习率,后20K的mini-batch上我们使用0.0001的学习率,同时使用全职衰减,momentum=0.9,weight decay=0.0005.
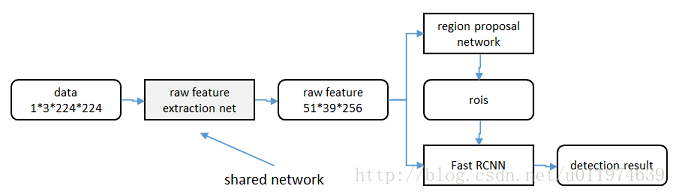
共享特征
RPN和Fast R-CNN都需要一个原始特征提取网络(下图灰色方框)。这个网络使用ImageNet的分类库得到初始参数W0,但要如何精调参数,使其同时满足两方的需求呢?本文讲解了三种方法。
Alternating training(轮流训练)
- 先独立训练RPN,然后用这个RPN的网络权重对Fast-RCNN网络进行初始化并且用之前RPN输出proposal作为此时Fast-RCNN的输入训练Fast R-CNN
- 用Fast R-CNN的网络参数去初始化RPN
- 交换a,b训练过程即可
具体操作时,仅执行两次迭代(后面再迭代,效果没啥大的提升),并在训练时冻结了部分层。
Approximate joint training(近似联合训练)
直接在上图结构上训练。proposals是由中间的RPN层输出的,而不是从网络外部得到。需要注意的一点,名字中的”approximate”是因为反向传播阶段RPN产生的cls score能够获得梯度用以更新参数,但是proposal的坐标预测则直接把梯度舍弃了,这个设置可以使backward时该网络层能得到一个解析解,能将训练时间减少20%-25%。
Non-approximate training(联合训练)
直接在上图结构上训练,上面的Approximate joint training把proposal的坐标预测梯度直接舍弃,所以被称作approximate,那么理论上如果不舍弃是不是能更好的提升RPN部分网络的性能呢?作者把这种训练方式称为“ Non-approximate joint training”,论文没有对这个方法进行讨论。
参考链接:
https://blog.csdn.net/u011974639/article/details/78053203#faster-r-cnn
