spp-net,通过选取2k个候选框,一次输入给CNN,在最后卷积层和全连接层中间加了金字塔池化层,最后也是用svm分类。金字塔池化层得到了大家的广泛认可,以后的许多模型,或多或少在这方面都是参考了这种思路。
fast -rcnn,通过selective search 选择2k 个候选框,然后特征提取+分类,定位都一个神经网络搞定。
=====
spp-net特征提取和分类是2步骤分离的。Fast R-CNN使用了SPP-net和RCNN的思想,并解决了SPP-net中的关键问题,即它们可以进行端到端训练。
为了通过金子塔空间池化来传播梯度(SPP网络有一个缺点,通过空间金字塔层进行反向传播梯度消失),它使用了一个简单的反向传播计算,与最大池化(max-pooling)梯度计算非常相似,区别在于池化区域重叠,因此一个单元可以从多个区域抽取梯度。使得输入图像任意尺寸,只进行1次整体卷积操作省时间,然后特征映射到已经选取好的2K个候选框,没有2K个选取好的候选框,又都卷积提取特征计算2K次。
Fast R-CNN它在神经网络训练本身中加入了bounding box 回归(rcnn是单独进行回归算法的)。所以现在网络上有两个输出,即分类输出和 bounding box 回归定位输出。多任务目标函数是Fast-rcnn的一个显著特点,它不再需要分别训练网络进行分类和定位。 由于CNN的端到端学习,这两个改变减少了整体训练时间,预测时间上,因为借鉴了spp-net的一次卷积操作也是很高效。并且相对于SPP网络提高了准确性。
创新点
规避R-CNN中冗余的特征提取操作,只对整张图像全区域进行一次特征提取;
用RoI pooling层取代最后一层max pooling层,同时引入建议框信息,提取相应建议框特征;
Fast R-CNN网络末尾采用并行的不同的全连接层,可同时输出分类结果和窗口回归结果,实现了end-to-end的多任务训练【建议框提取除外】,也不需要额外的特征存储空间【R-CNN中这部分特征是供SVM和Bounding-box regression进行训练的】;
采用SVD对Fast R-CNN网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度。
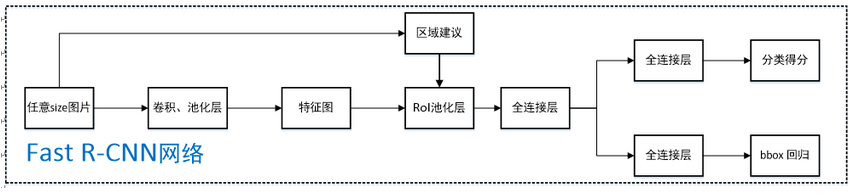
整体流程:
1采用selective search算法提取约2k个建议框;
2任意size整张图片输入CNN网络vgg,googlenet,resnet等),经过若干卷积层与池化层,得到特征;
3根据原图中建议框映射到最后一层卷积特征图上。
4最后一层卷积网络接的是roi polling ,它后面接全连接层。通过ROI 使得每一个建议窗口得到固定大小的特征向量;
5第4步所得特征向量经由各自的全连接层【由SVD分解实现】,分别得到两个输出向量:一个是softmax的分类得分,一个是Bounding-box窗口回归;
6利用窗口得分 分别对每一类物体进行非极大值抑制剔除重叠建议框,最终得到每个类别中回归修正后的定位窗口。
为什么要采用SVD分解实现Fast R-CNN网络中最后的全连接层?具体如何实现?
图像分类任务中,用于卷积层计算的时间比用于全连接层计算的时间多,而在目标检测任务中,selective search算法提取的建议框比较多【约2k】,几乎有一半的前向计算时间被花费于全连接层,就Fast R-CNN而言,RoI池化层后的全连接层需要进行约2k次【每个建议框都要计算】,因此在Fast R-CNN中可以采用SVD分解加速全连接层计算。
这里解释一下为什么SPPnet不能更新spatial pyramid pooling层前面的卷积层,而只能更新后面的全连接层?
博主没有看过SPPnet的论文,有网友解释说卷积特征是线下计算的,从而无法在微调阶段反向传播误差;另一种解释是,反向传播需要计算每一个RoI感受野的卷积层梯度,通常所有RoI会覆盖整个图像,如果用RoI-centric sampling方式会由于计算too much整幅图像梯度而变得又慢又耗内存。
feature map上的框怎么对应上输入图像的框?实际上,就是很直接粗暴的方式:根据特征图和原图的比例,把特征图上的框按比例进行缩放。
参考https://blog.csdn.net/wopawn/article/details/52463853