R-CNN
R-CNN的全称是Region-CNN,是第一个成功将深度学习应用到目标检测上的算法。R-CNN基于卷积神经网络(CNN),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。
R-CNN经典论文《Rich feature hierarchies for Accurate Object Detection and Segmentation 》。Ross Girshick这篇paper,改变了图像领域检测物体的实现思路,以R-CNN为基点,紧随其后的SPPNet、Fast R-CNN、Faster R-CNN模型都是照着这个思路。
下面就在R-CNN的经典论文的基础上对R-CNN进行介绍:
在R-CNN模型出现之前,在权威数据集PASCAL上,物体检测的效果已经达到一个稳定水平。效果最好的方法是融合了多种低维图像特征和高维上下文环境的复杂融合系统。这篇论文提出了一种简单并且可扩展的检测算法,可以将mAP在VOC2012最好结果的基础上提高30%以上——达到了53.3%。
两个关键的因素:
- 在候选区域上自下而上使用大型卷积神经网络(CNNs),用以定位和分割物体。
- 当带标签的训练数据不足时,先针对辅助任务进行有监督预训练,再进行特定任务的调优,就可以产生明显的性能提升。
Introduction
R-CNN在物体检测上的具体步骤:
1.找出图片中可能存在目标的候选区域。
2.通过CNN对候选区域提取特征向量
3.在候选区域的特征向量上训练分类器,分类器用于判别物体,并得到bbox
4.修正bbox,对bbox做回归微调
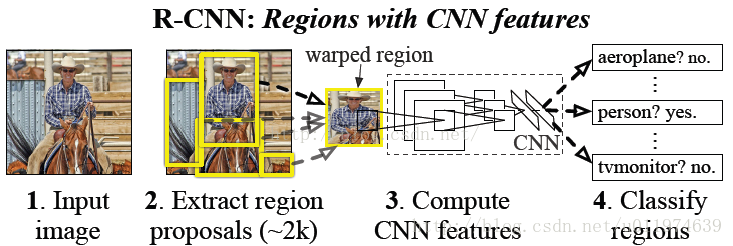

下面就对上面的4个步骤一一进行分析:
1.图片中目标的侯选区域获取
由于一张图片中存在的物体,大小/位置并不是固定的,如果我们用滑窗的方法去寻找可能存在物体,工作量非常大,且很难实现。R-CNN模型使用的方法是先使用“传统成熟”的方法找出一组图像中可能存在目标的侯选区域(region proposals),产生侯选区域的方案可减少在一张图片上寻找物体的复杂度,且很大可能的保存了图片上所有存在物体的区域。通过对常用候选区域方法性能的比较,R-CNN最终选择的产生候选区域产生的方法是selective search.
Selective Search
论文参考《Selective Search for Object Recognition》
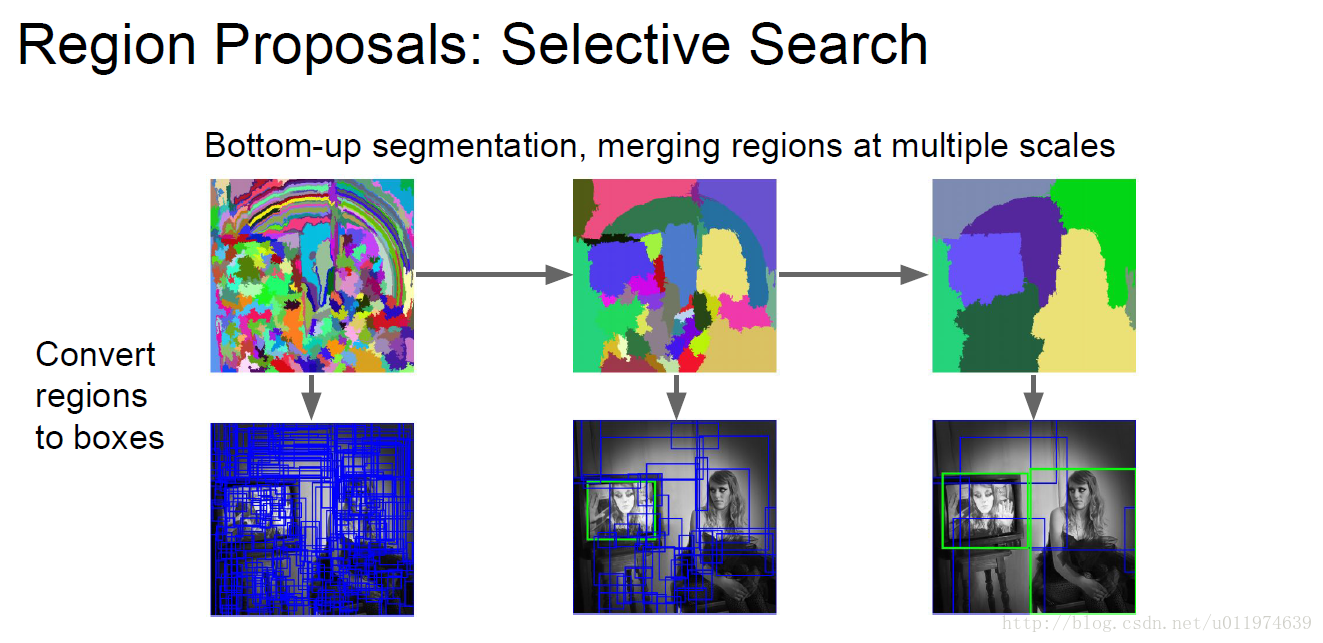
上图为selective search在图片上提取侯选区域的过程。
Selective Search在一张图片上提取出来2000个左右的侯选区域,这些候选区域的长宽并不是固定的。而在下一层使用CNN提取特征向量时,需要接受固定长度的输入(fc层要求),故我们需要对候选区域做一些长度上的修改。
对于候选区域的修改,论文主要提到两种方法:
1.各向异性缩放,即直接缩放到指定大小,这可能会造成不必要的图像失真
2.各向同性缩放,在原图上出裁剪侯选区域,在边界用固定的背景颜色(采用侯选区域的像素颜色均值)填充到指定大小
通过实验对比,最终采用了各项异性缩放。

2.通过CNN对候选区域提取特征向量
CNN的作用是在侯选区域的基础上提取出更高级、更抽象的特征,高级特征的作用是为下一步的分类器作为输入数据,分类器依据高级特征回归出物品的位置和种类。
网络的训练
CNN的训练分为以下几个过程:
1.step 1 :训练或下载一个训练好的图片分类器模型
一般的CNN模型层数多,模型的容量大,在标定数据少的情况下,这样的数据量是不够从新训练一个CNN模型的。故我们采用已训练好的AlexNet/VGG16模型的卷积层参数,使用这样已训练好的网络参数,可以较好的提取图片的特征。这样的操作有一个专业的名词-迁移学习。
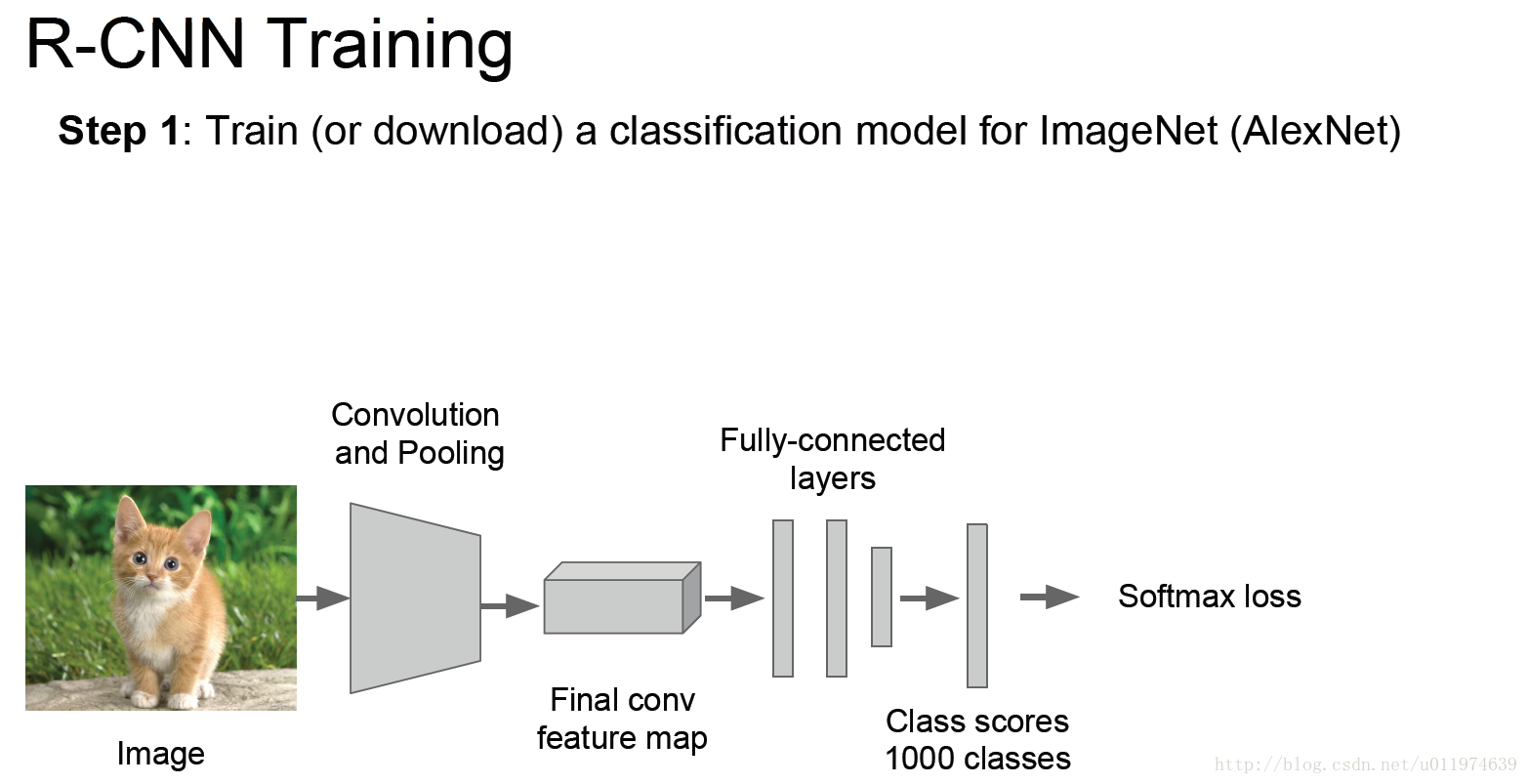
step2:fine-tuning
AlexNet是针对ImageNet训练出来的模型,AlexNet的卷积部分可以作为一个好的特征提取器,后面的全连接层可以理解为一个好的分类器。这里把AlexNet的softmax层替换为一个N+1神经元的输出层(N为存在物体的种类,即正样本;1为背景,即负样本)。然后做微调训练。
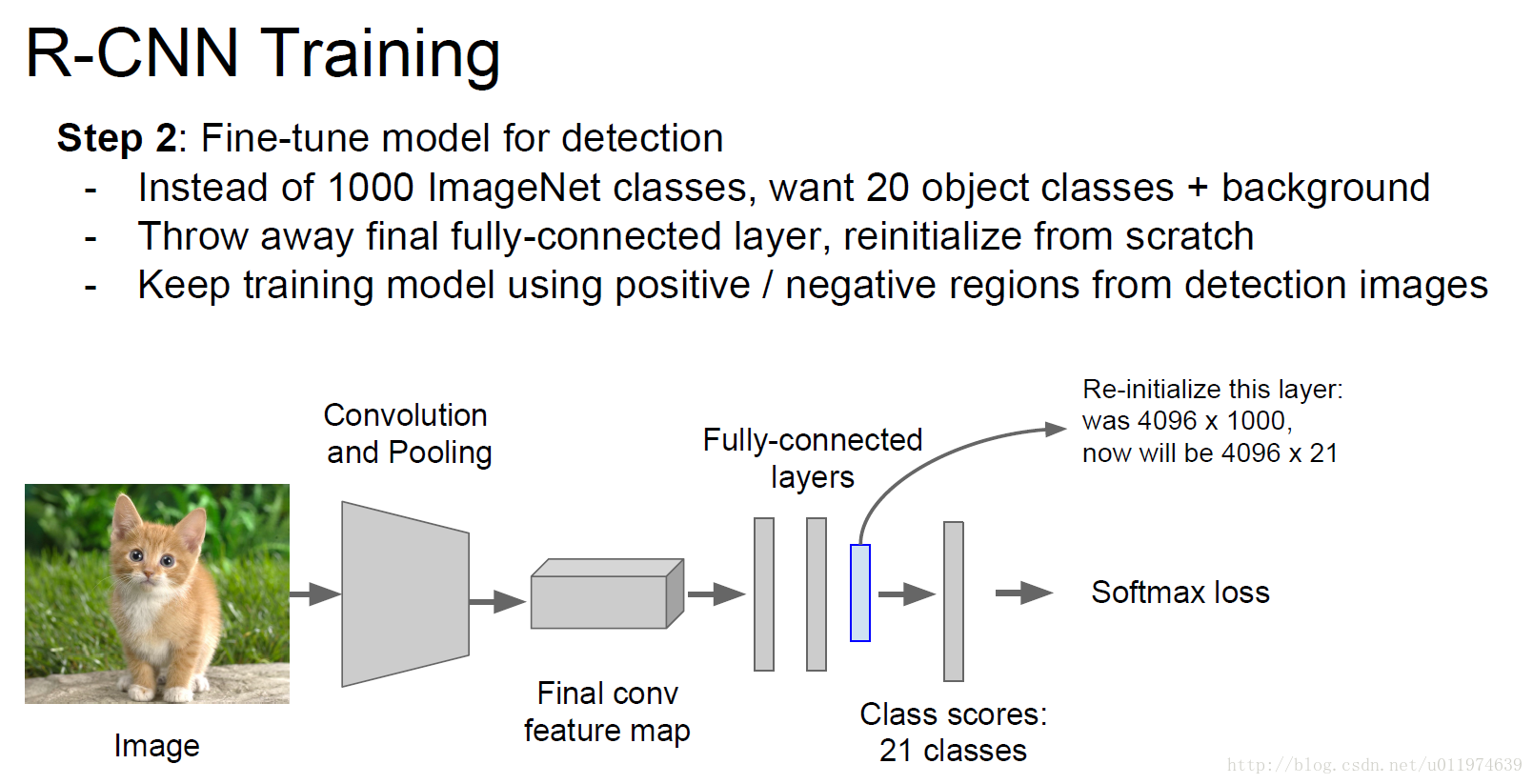
fine-tuning的训练细节:
原本ImageNet的输出类别有1000个,这里把1000个替换为21个(N=20,1为背景).使用的SGD,每个mini-batch取128.
正样本:候选区域与ground-truth(图片物体标注区域)的IoU>0.5 。数量:32
负样本:候选区域与ground-truth(图片物体标注区域)的IoU<0.5 。数量:96
IoU的阈值为0.5是因为CNN模型容量大,需要的数据多,故放宽限制,获取到更多的数据,防止模型过拟合。
需要注意的是,我们在训练CNN的时候会在网络的后面加上一个分类层,在训练完毕后,我们会移除最后的分类层,直接提取到前面的FC层,AlexNet的FC层为4096维。
对于一张图片,使用训练好的CNN基础上,将所有的图片的所有侯选区域塞到CNN里面,把得到的pool5 feature存到硬盘里面(这里一存,后面训练一取,非常耗费时间)
3.在候选区域的特征向量上训练分类器
前面的CNN在侯选区域上提取出了特征向量,例如2000个侯选区域,那么提取出来的就是2000*4096这样的特征向量(AlexNet的第一个FC层维度为4096,故pool5的输出为4096)。用这些特征向量训练同时训练N个二分类的SVM,SVM的权重矩阵为4096xN(N为分类种类)。由于选择的样本不够准确,所以采用svm.
在经过SVM分类后,会输出一堆的候选框得分(是一个2000x20的得分矩阵),这时候我们需要用的非极大值抑制得到想要的候选框了.大概步骤如下:
1.对矩阵按列从大到小排序
2.每列的最大值向下做非极大值抑制,遍历完所有列
3.依据阈值,得到候选区域的类型
4. 修正bbox,对bbox做回归微调
我们使用一个简单的bounding-box回归用于提高定位的表现。
参考资料:
