SSD(Single Shot MultiBox Detector)是ECCV2016的一篇文章,属于one - stage套路。在保证了精度的同时,又提高了检测速度,相比当时的Yolo和Faster R-CNN是最好的目标检测算法了,可以达到实时检测的要求。在Titan X上,SSD在VOC2007数据集上的mAP值为74.3%,检测速度为59fps。
SSD
SSD效果为什么这么好
SSD效果好主要有三点原因:
1.多尺度
2.设置了多种宽高比的default box(anchor box)
3.数据增强
下面对这几点分别进行分析:
1.多尺度
SSD架构如下:
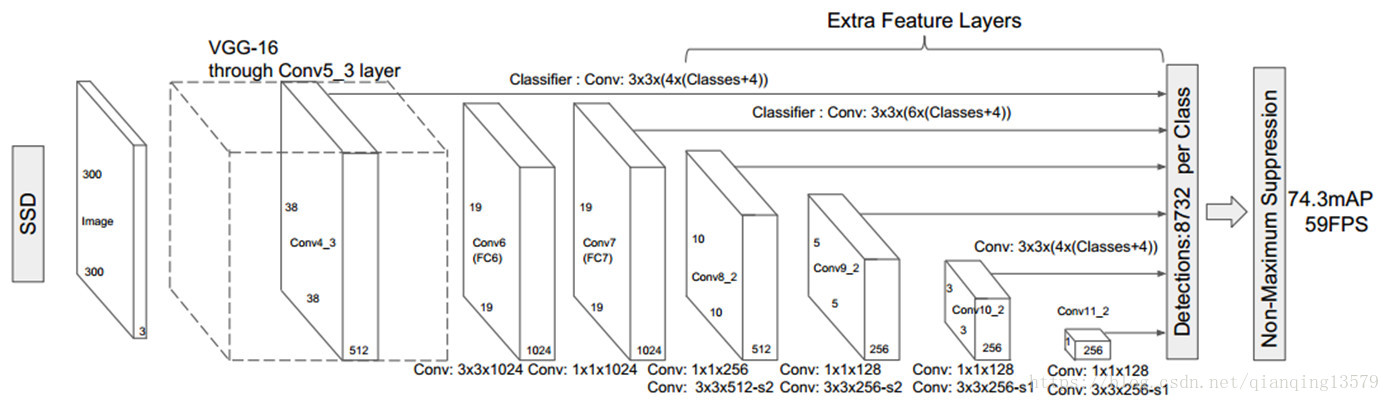
采用VGG16的基础网络结构,使用前面的五个CONV层作为特征提取,然后利用astrous 算法将FC6和FC7转化成CONV6和CONV7层。再增加3个卷积层,和一个average pool层。由SSD的网络结构可以看出,SSD使用6个不同特征图检测不同尺度的目标。低层预测小目标,高层预测大目标。

从上面的表格可以看出,采用6个特征图检测的时候,mAP为74.3%,如果只采用conv7做检测,mAP只有62.4%。
2.多种宽高比的default box
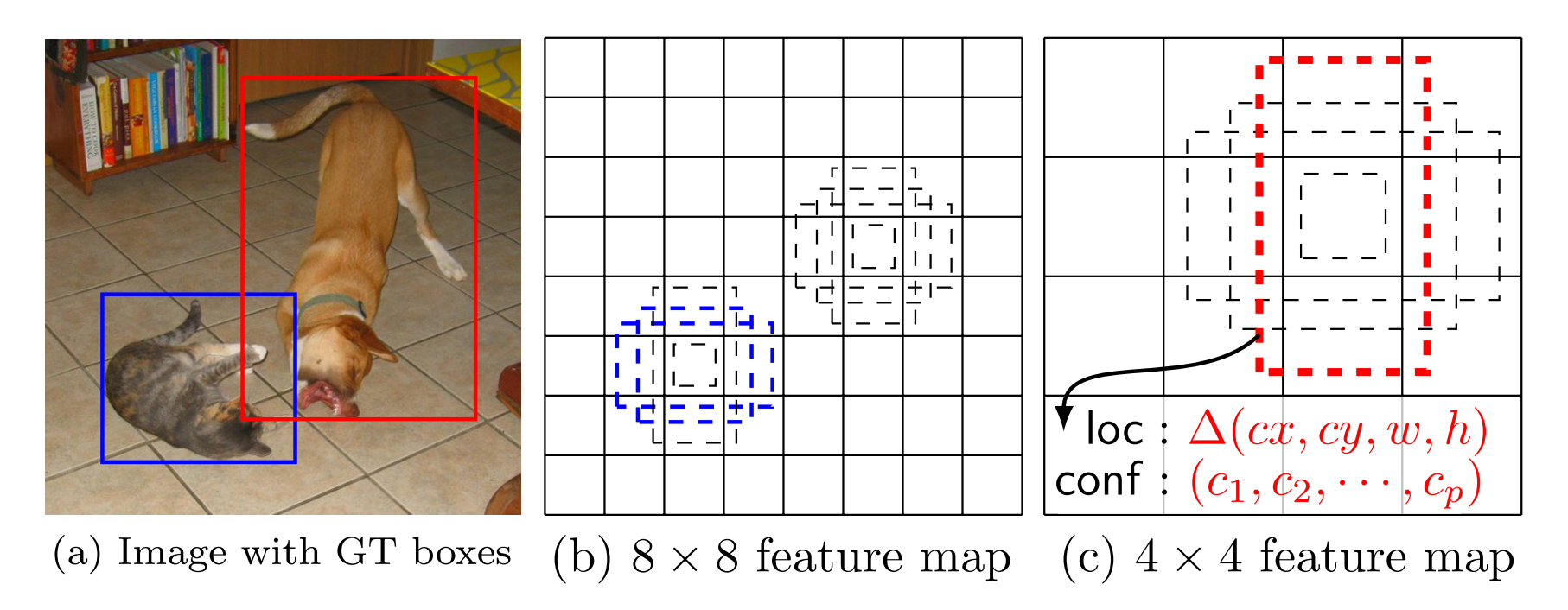
在特征图的每个像素点处,生成不同宽高比的default box(anchor box),论文中设置的宽高比为{1,2,3,1/2,1/3}。假设每个像素点有k个default box,需要对每个default box进行分类和回归,其中用于分类的卷积核个数为c*k(c表示类别数),回归的卷积核个数为4*k。
3.数据增强
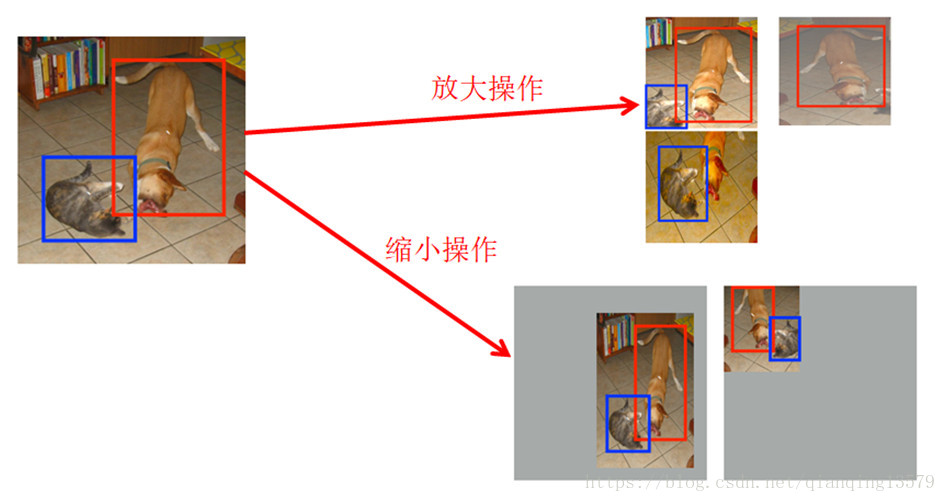
SSD中使用了两种数据增强的方式:
1.放大操作: 随机crop,patch与任意一个目标的IOU为0.1,0.3,0.5,0.7,0.9,每个patch的大小为原图大小的[0.1,1],宽高比在1/2到2之间。能够生成更多的尺度较大的目标
2.缩小操作: 首先创建16倍原图大小的画布,然后将原图放置其中,然后随机crop,能够生成更多尺度较小的目标.
SSD的缺点
SSD对小目标的检测效果一般
SSD的改进
1 增大输入尺寸
2使用更低的特征图做检测
3 设置default box的大小,让default box能够更好的匹配实际的有效感受野
参考链接:
https://blog.csdn.net/qianqing13579/article/details/82106664
https://blog.csdn.net/u011974639/article/details/78244674
https://blog.csdn.net/zj15939317693/article/details/80596870
