B站观众姥爷的评论及回复爬取及数据可视化
1. 前言
在昨天RNG和EDG的比赛中,RNG以2比1战胜了EDG,这是两队在今年第一次相遇,小狗和厂长都没在,所以被大家称为:新猪狗大战,所以吸引了许多粉丝的关注。

作为一个也有过LOL青春的老年人来说,只能说那种感觉又回来了。要说三场比赛中,最精彩的还是第三场,EDG领先1W经济,最后由于偷家和后期决策问题,导致被RNG翻盘,由于这局比赛打的过于激烈,在网上引起了剧烈的讨论。

这里就选取B站中官方上传的比赛视频RNG vs ENG下面的评论和回复,看一下观众姥爷们都在说什么,有什么经典的骚段子或者吐槽的问题
2. 评论和回复的数据爬取
2.1 视频基本情况查看
这里直接调用api接口进行查看,只需要输入视频的标识号即可,封装函数如下
import json,requests,time
import pandas as pd
def get_base_info(oid):
base_info_url = f'https://api.bilibili.com/x/web-interface/archive/stat?aid={oid}'
base_info = requests.get(base_info_url,headers = dic_header).json()['data']
#print(base_info) #可以输出转化为json形式的数据
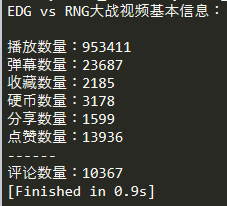
print('EDG vs RNG大战视频基本信息:\n')
print('播放数量:{}\n弹幕数量:{}\n收藏数量:{}\n硬币数量:{}\n分享数量:{}\n点赞数量:{}\n------\n评论数量:{}'.format(
base_info['view'],base_info['danmaku'],base_info['favorite'],
base_info['coin'],base_info['share'],base_info['like'],base_info['reply']
))
if __name__ == '__main__':
dic_header = {'User-Agent': 'Mozilla/5.0'}
oid = 370124445
get_base_info(oid)
→ 输出的结果为:(这里把评论信息突出,可以看出截止到目前已经差不多100w播放,超过1w条评论了,足见各位观众姥爷们的热情)
2.2 数据资源地址解析
2.2.1 评论数据资源url解析
打开官网视频后,首先是对网页进行解析,找到存放评论数据资源的接口(url)。操作步骤如下:【右键检查】 → 【Network】 → 【刷新】 → 【点击任意文件】 → 【Preview】 → 【找到数据所在的文件】 → 【Headers】 → 【资源url】
图示如下:(这里解析发现返回的数据都在reply?..等文件里面,所以直接就筛选这类的文件即可)
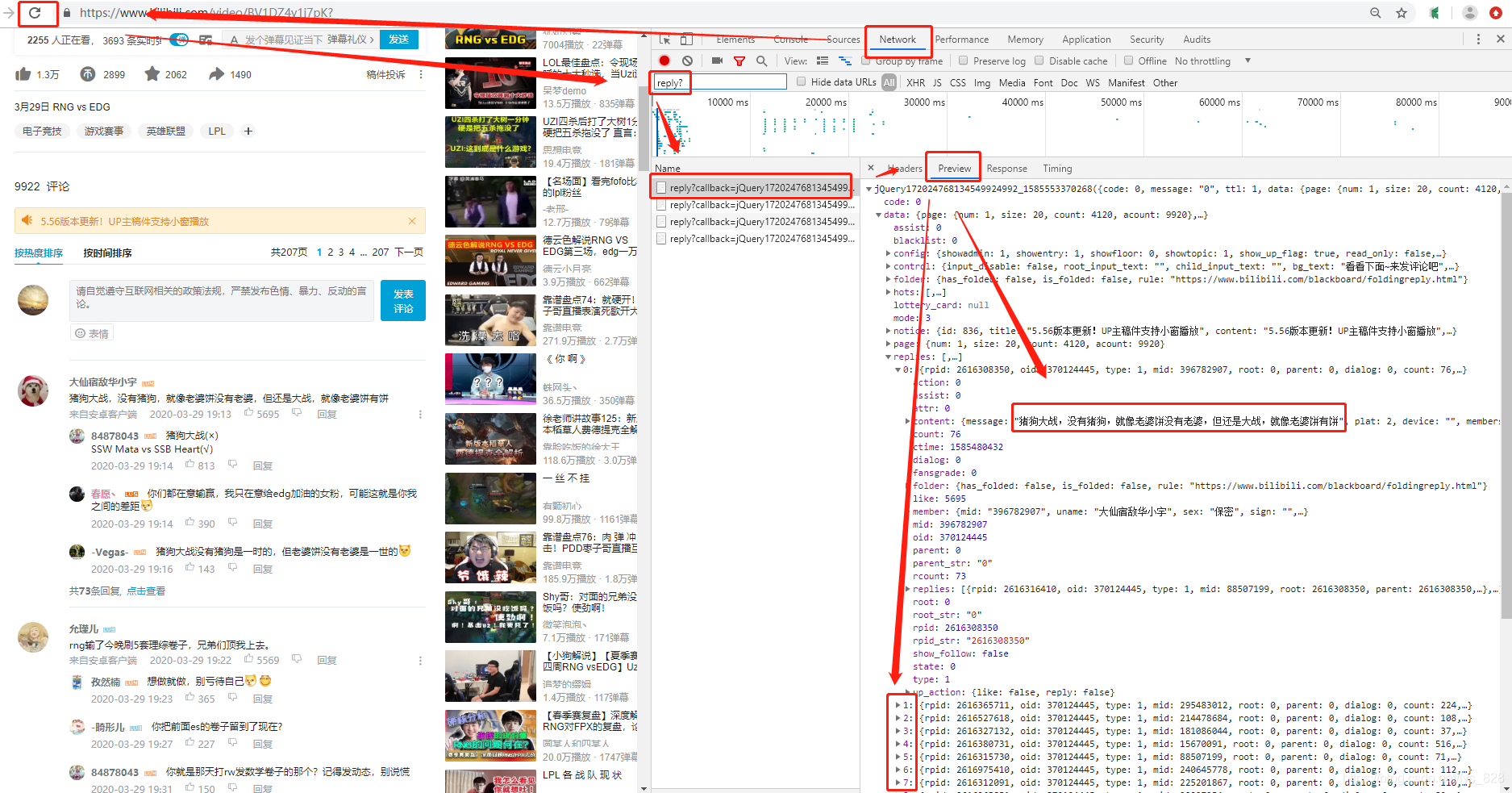
在上面的界面点击Preview旁边的Headers,就可以找到资源对应的url了,但是这个url并不是直接就可以用的(可以尝试一下直接复制这个url使用浏览器打开),需要进行简化一下,方便我们找到其中的规律,顺利进行数据的爬取,如下
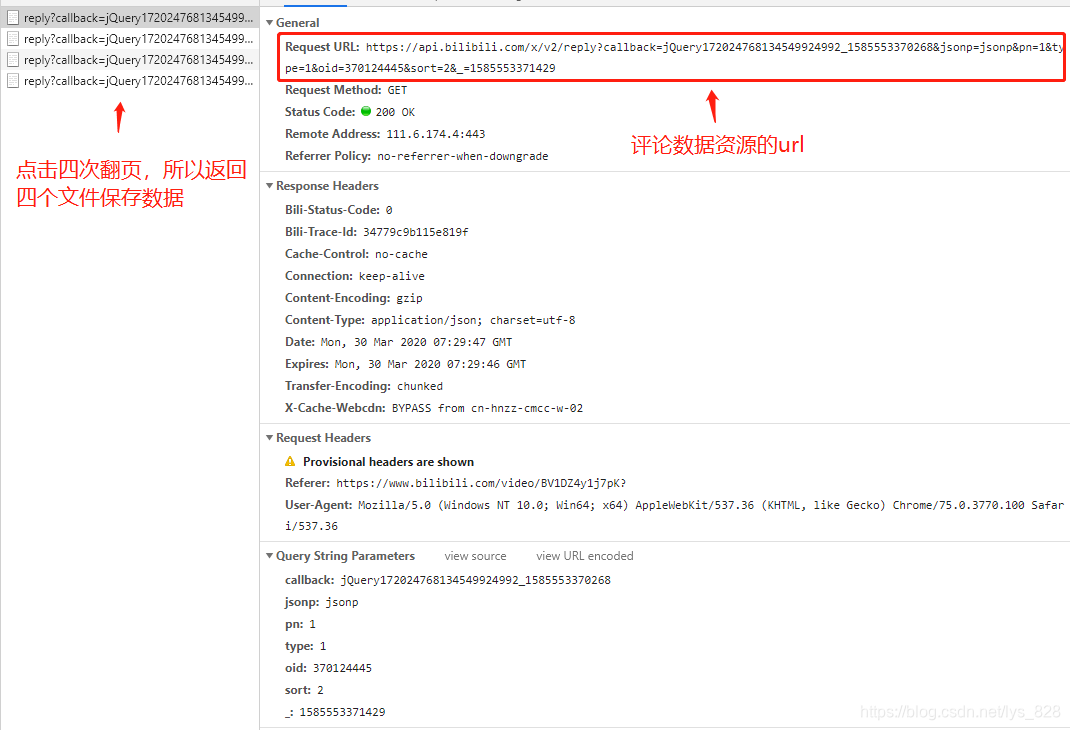
选取如上图的url,进行url‘瘦身’(有效成分进行提取),再经过几次测试之后,发现Query String Parameters中的参数只有部分是有效的,也就是pn,type,和oid有效。那么直接查看一下前五页的评论的有效url,如下,因此可以发现评论的数据资源url是有规律的。
conment_1 = https://api.bilibili.com/x/v2/reply?&pn=1&type=1&oid=370124445
conment_2 = https://api.bilibili.com/x/v2/reply?&pn=2&type=1&oid=370124445
conment_3 = https://api.bilibili.com/x/v2/reply?&pn=3&type=1&oid=370124445
conment_4 = https://api.bilibili.com/x/v2/reply?&pn=4&type=1&oid=370124445
conment_5 = https://api.bilibili.com/x/v2/reply?&pn=5&type=1&oid=370124445
2.2.2 回复数据资源url解析
这里以第一页的界面进行演示,点开下面的第一条评论,然后点击‘点击查看’,就会发现右侧多出来一个文件,点开后如下所示,第一页的回复数据(每页是10条)就出现在右侧了
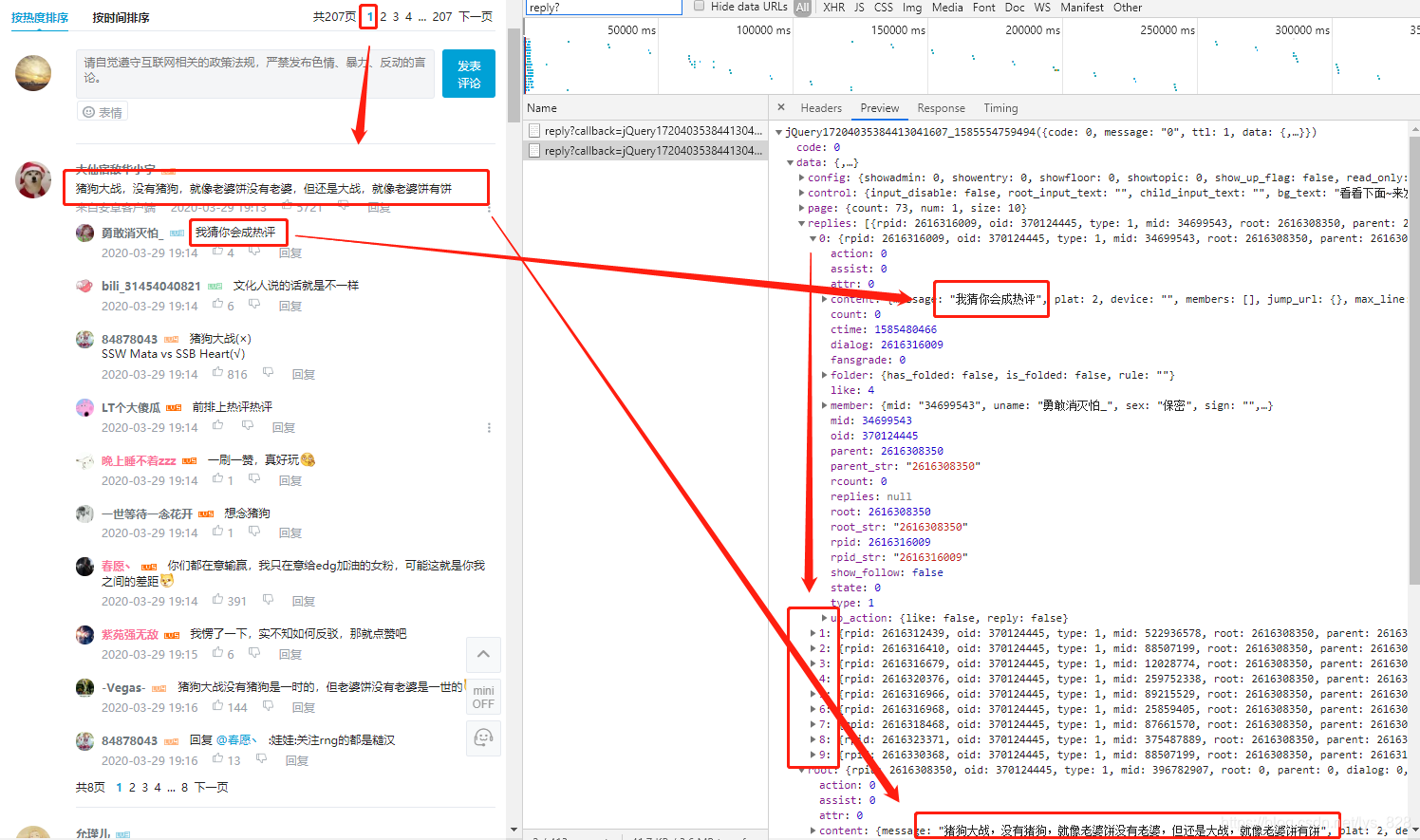
和上面的操作一样,找到这个数据资源的url进行‘瘦身’,经过测试发现其中的有效成分是:pn,type,oid和root,对比上面评论数据资源的url,发现这里多了一个root的参数,可以初步猜测应该是属于每个评论的识别的标识,那么尝试再评论数据上面找一下这个参数,可以发现上图中,评论数据就是在root这个参数下,具体的数值对应的就是这个评论的rpid,如下:
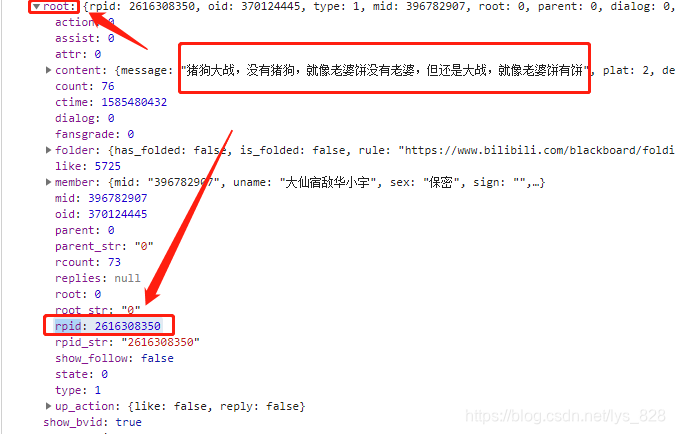
首先确定单条回复数据资源url的规律,那么后面的多条评论下回复数据的url规律就只需要把后面root对应的数值修改即可,这里还是以第一条评论下的多页回复数据的url为例,如下
reply_1 = https://api.bilibili.com/x/v2/reply/reply?&pn=1&type=1&oid=370124445&ps=10&root=2616308350
reply_2 = https://api.bilibili.com/x/v2/reply/reply?&pn=2&type=1&oid=370124445&ps=10&root=2616308350
reply_3 = https://api.bilibili.com/x/v2/reply/reply?&pn=3&type=1&oid=370124445&ps=10&root=2616308350
reply_4 = https://api.bilibili.com/x/v2/reply/reply?&pn=4&type=1&oid=370124445&ps=10&root=2616308350
reply_5 = https://api.bilibili.com/x/v2/reply/reply?&pn=5&type=1&oid=370124445&ps=10&root=2616308350
2.3 构造函数返回要爬取数据的url列表
2.3.1 生成评论数据资源url列表和对应的rpid
根据上面的分析可知,每页评论数据的url是有规律的,为了下一步获取评论对应的回复数据,因此除了返回评论数据的url列表,还要返回其对应的rpid数据(这里处理的方式是在函数内部直接调用爬取回复数据的函数,而没有麻烦的再返回rpid数据进行遍历循环输出),第一个函数封装如下,
def get_comment_datas(oid):
comment_url = 'https://api.bilibili.com/x/v2/reply'
comment_page = 1
comment_data_lst = []
while True:
try:
param = { 'callback': 'jQuery1720028589320105517402_' + str(now_time),
'jsonp': 'jsonp',
'pn': comment_page,
'type': '1',
'oid': oid,
'sort': '2',
'_': now_time }
html = requests.get(url=comment_url, headers=dic_header, params=param)
start = html.text.index('{')
end = html.text.index('})')+1
comment_data = json.loads(html.text[start:end])['data']['replies']
#print(comment_data) #成功的转换为json数据
print(f'当前正在爬取第{comment_page}页评论数据...')
for data in comment_data:
dic_coment = {}
dic_coment['member'] = data['member']['uname']
dic_coment['like'] = data['like']
dic_coment['comment'] = data['content']['message']
dic_coment['time'] = datetime.fromtimestamp(data['ctime'])
dic_coment['rpid'] = data['rpid_str']
comment_data_lst.append(dic_coment)
print('昵称: {}\n点赞数:{}\n'.format(dic_coment['member'],
dic_coment['like'] ))
#comment_data_lst.extend(get_reply_data(comment_page,dic_coment['rpid']))
#这个是下一步封装完爬取回复数据的函数后才添加的
time.sleep(1)
# if comment_page > 1:
# break
comment_page += 1
except Exception as Comment_Page_Error:
break
return comment_data_lst
提醒:
1)这里第一个函数获取评论数据资源的url使用了全部的参数(param),也可以使用简化后的url,下面爬取回复数据的爬取使用的就是简化的,这里提出两种方式进行数据的爬取
2)在进行代码完整性,测试能否正常输出的时候,建议将注释的内容(if判断结构)打开,这样看是否可以获取第一页的内容,如果可以的话再进行下一步函数的封装
3)最后全部函数封装完毕后,再将其注释掉,这样就可以爬取全部的数据了
2.3.2 生成回复数据资源url列表
1) 首先,大部分内容和上面的一样,但是这里使用的是简化版的url,结果是一样的,就没有必要再使用全部参数的url了
2) 其次也是相同的步骤,也拿第一页的回复数据进行试错,保证程序可以正常输出结果后再获取全部的数据
3)最后将函数插入到上方的注释处,由于返回的是列表数据,所以要使用列表的extend的方法
def get_reply_data(comment_page,rpid):
reply_page = 1
reply_data_lst =[]
while True:
print('正在爬取第{}页评论数据中的第{}页的回复数据......'.format(comment_page,reply_page))
reply_url = 'https://api.bilibili.com/x/v2/reply/reply?&pn={}&type=1&oid=370124445&ps=10&root={}'.format(reply_page,rpid)
html = requests.get(url=reply_url, headers=dic_header)
reply_data = html.json()['data']['replies']
try:
for data in reply_data:
dic_reply = {}
dic_reply['comment'] = data['content']['message']
dic_reply['member'] = data['member']['uname']
dic_reply['like'] = data['like']
dic_reply['time'] = datetime.fromtimestamp(data['ctime'])
reply_data_lst.append(dic_reply)
print('昵称: {}\n点赞数:{}\n'.format(dic_reply['member'],
dic_reply['like'] ))
# if reply_page > 1:
# break
reply_page += 1
except Exception as Reply_Page_Error:
break
return reply_data_lst
提醒:
1)为了可视化输出结果,判断程序的进行情况,设置了昵称和其对应评论点赞数对应的变量数据的输出
2)还有更直观的显示当前程序正在爬取多少页的评论数据中的多少页的回复数据(有点拗口,哈哈哈),如下图就懂了
2.4 输出结果
2.4.1 爬取第100页数据的截图
2.4.2 爬取第200页数据的截图
2.4.3 爬取所有的数据的截图(总共10086条数据,这就很‘移动’了)
3. 数据可视化
3.1 点赞量最高top20的‘经典’评论
data = pd.read_excel('b站.xlsx')
#加载数据
df = data.copy()
#为了防止原数据被破坏,操作之前备份
df = df.sort_values(by = 'like',ascending = False)
#按照点赞数进行排序,然后筛选前20条数据
df_top20 = df.iloc[:20]
x = df_top20['comment']
#作为x轴
y = df_top20['like']
#作为y轴
import pyecharts as pe
#使用的是0.5.11版本
bar = pe.Bar('猪狗大战B站评论及回复数据分析')
bar.add('骚话Top20', x, y, is_datazoom_show = True,
datazoom_range = [0,100], mark_line=[ "average"],
tooltip_axispointer_type = 'cross')
bar.render('1.html')
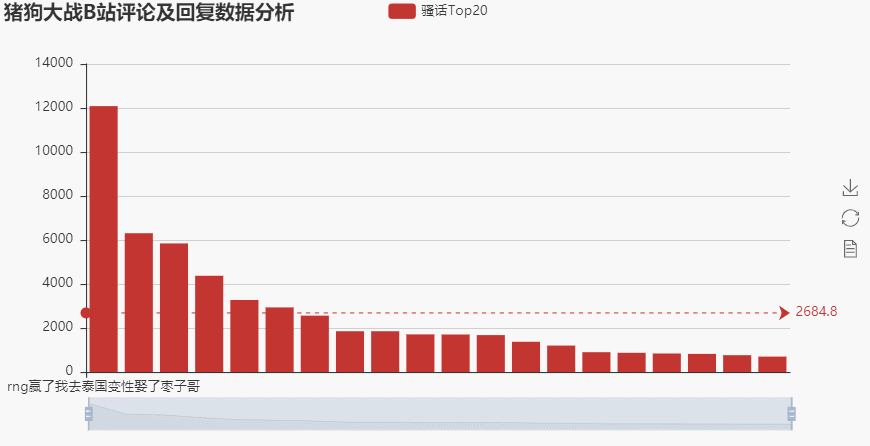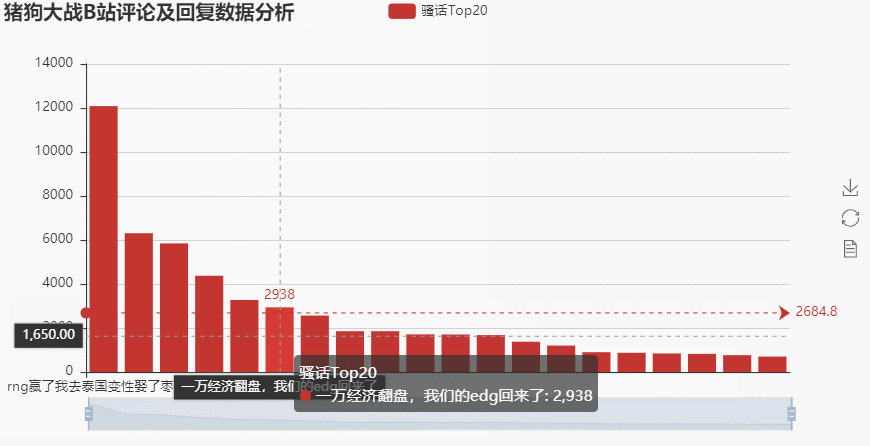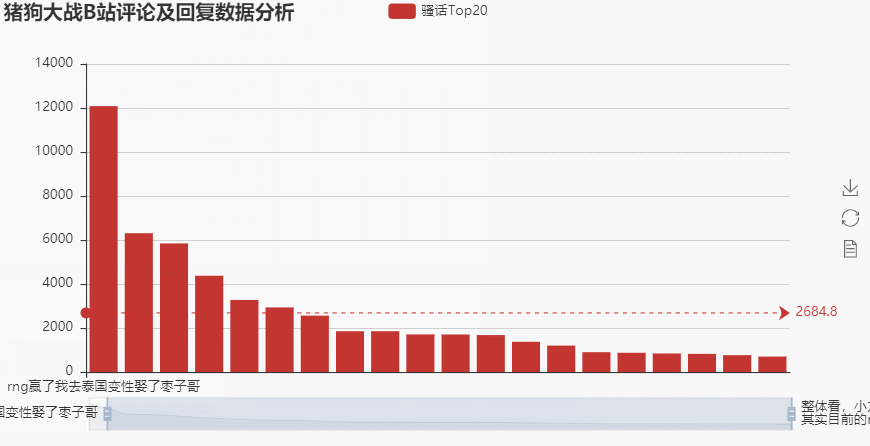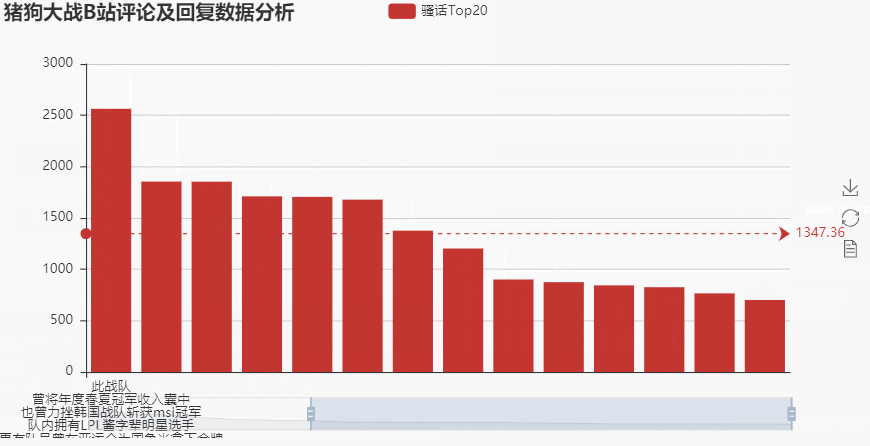
→ 输出的结果为:(点赞最多的话就是:rng赢了我去泰国变性娶了枣子哥,当时评论的时候还是两队没有结束战斗的时刻,这位大兄弟是真的有点骚呢)
3.2 数据词云展示
先采用jiaba分词,将数据进行拆分,然后剔除字符长度为1的数据,然后作为展示的数据,然后进行数据的清洗,和过滤词的设置,最后生成词云
import jieba
#导入jieba库
comment_str_all = ''
for comment in df['comment']:
comment_str_all += comment
comment_str_all = comment_str_all.replace('edg','EDG').replace('rng','RNG').replace('ig','IG').replace('一万','1w')
#把comment中的数据全部拼接成为字符串,然后在替换重复的数据
seg_list = jieba.lcut(comment_str_all)
#中文分词
keyword_count = pd.Series(seg_list)
#keyword_count.str.len()
#这里是查看切割数据后不同长度的情况
keyword_count = keyword_count[keyword_count.str.len()>1]
#剔除数据长度为1的数据
keyword_count.value_counts()
#进行数据排序,这一步就是为了下一步设置filter_words做的准备
filter_words = ['回复','不是','什么','真的','就是','这么','那么','怎么','现在','是的','这个','那个','这种','时候',
'什么','这部','没有','还有','觉得','什么','就是','没有','一个','不是','还是','最后','我们','但是',
'因为','真的','还是','现在 ','可能','可以','只是','其实','所以','这样','也许','一直','第一','为了','它们',
'看到','看过','自己','不会','一下','然后','真有','他们','已经']
keyword_count = keyword_count[~keyword_count.str.contains('|'.join(filter_words))]
#排除filters_word里面的数据
keyword_count = keyword_count.value_counts()[:100]
#选择前100个重要的词汇进行词云展示
wd = pe.WordCloud("关键词汇挖掘-词云图")
# 提取每个词
words = keyword_count.index.tolist()
# 提取每个词的词频
words_counts = keyword_count.values.tolist()
# 绘制图表
wd.add("词频", words, words_counts, shape = 'star',
word_size_range=[20, 100], rotate_step=10)
#生成图表
wd.render('2.html')
→ 输出的结果为:

1) 战队方面:可以发现,除了猪狗大战中两个关键词之外,竟然还有IG战队的出现,回想一下上一次2019年3月30号IG20滴血翻盘EDG,也刚好是一周年的时间,所以网友们都在说致敬当初的一周年
2)英雄人物方面:卡萨丁(小虎)、维鲁斯(Hope)、沙皇(小学弟),乌兹(uzi,永远的神),都在关键词中多次出现,主要是第三局中,小虎的后期卡萨丁给了队伍翻盘的希望,然后Hope的维鲁斯在赛场上也有很亮眼的表现,最后是uzi的解说以及网友的调侃,都使得只要有RNG的比赛,他(神一样的男人)都会出现在关键词的位置
3) 赛场因素:经济,1w,火龙(魂),远古+大龙(双龙会),指挥+运营(偷家失误)等,可以看出这些词汇大部分指向的都是EDG战队的战况,也把‘领先1W经济被翻盘’赛场情况体现的淋漓尽致
4) 观众方面:棺材,淀粉,下饭,失望,经典,大哭,doge等词汇,可以发现观众面对这场比赛有着两个方向的情感,一种是偏向的对过去‘领先1W经济被翻盘’赛事的致敬,比如下饭,经典;还有是作为双方粉丝之间的看比赛心情的反复横跳,比如棺材(我又起来了,我又躺下了…),淀粉(皇杂)等
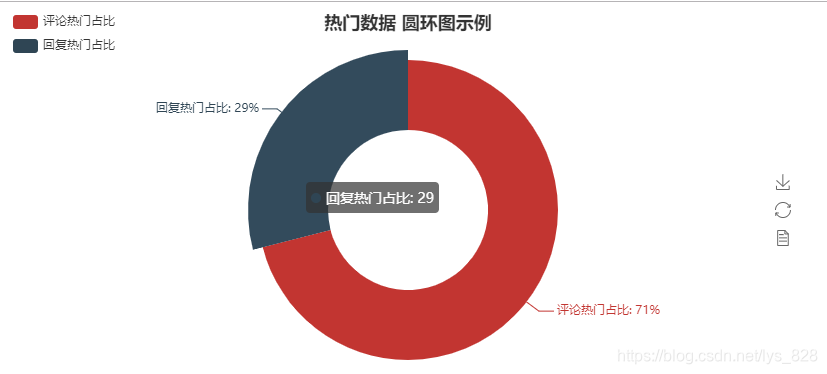
3.3 回复消息也能上热门吗?
这里抽空研究一下,有些人很喜欢评论(回复)已经上热门的评论,这样有可能自己的这条言论也会火起来,事实上是这样吗?下面就来以数据说话。
提醒: 在爬取回复数据的时候,是没有rpid的,因此很容易分辨出哪些是评论的数据,哪些是回复的消息
df_top100 = df.iloc[:100]
#选取前100条数据作为热门的评判标准
df_top100['is_reply'] =''
df_top100.loc[df_top100.rpid.notnull(),'is_reply'] = False
df_top100.loc[~df_top100.rpid.notnull(),'is_reply'] = True
#添加新字段,方便统计个数
df_top100 = df_top100['is_reply'].value_counts()
attr = ["评论热门占比", "回复热门占比"]
#因为只有两个数据,所以这里就直接命名了
v1 = df_top100.values.tolist()
#也可以只用这种方式直接生成数据
pie = pe.Pie("热门数据 圆环图示例", title_pos='center')
pie.add(
"",
attr,
v1,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
legend_orient="vertical",
legend_pos="left",
)
pie.render('3.html')
→ 输出的结果为:(可以发现,即使没有能够及时抢到评论的热门,通过回复,也能有30%左右的机会上热门呢,这也就解释了为什么有很多人倾向于回复热门的评论数据了)
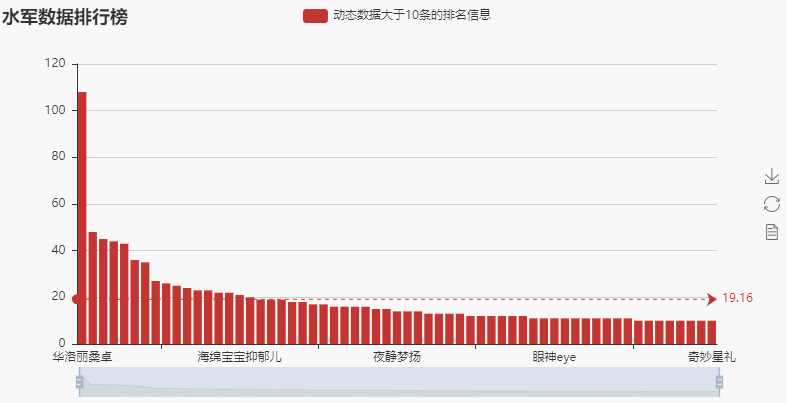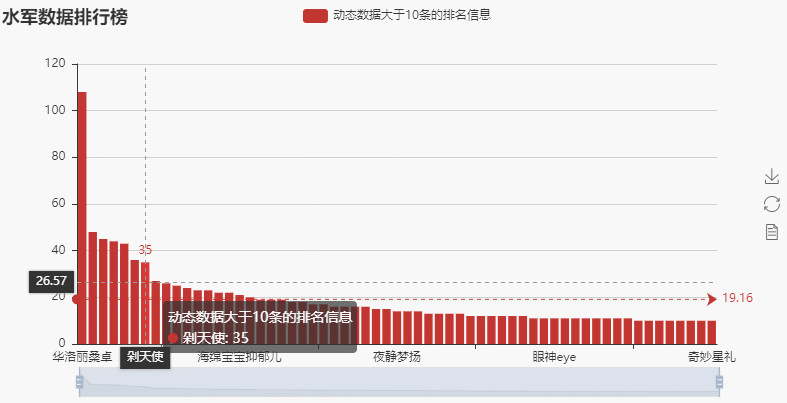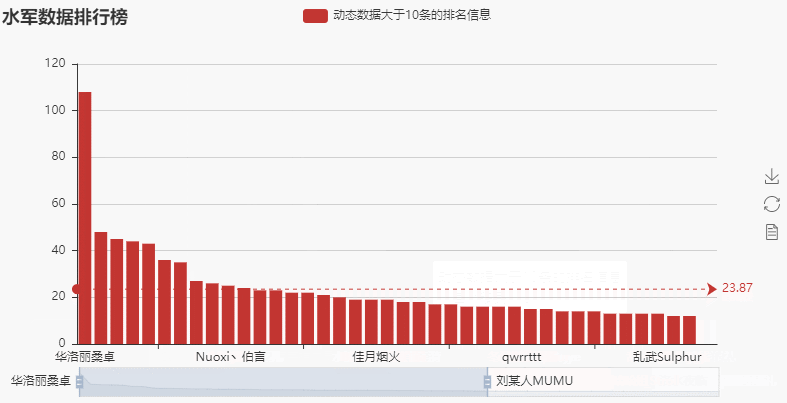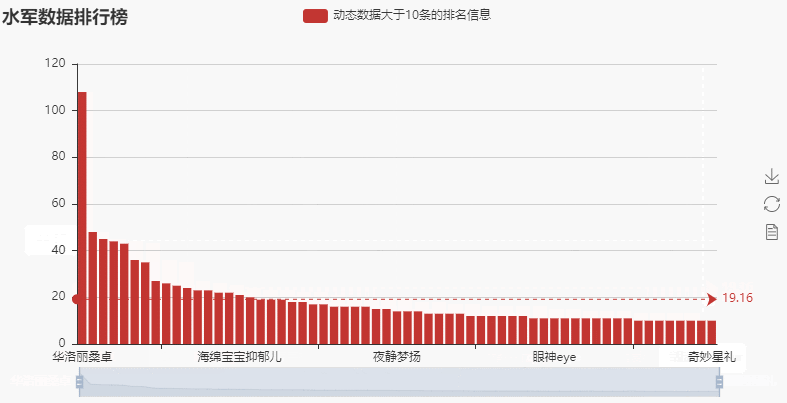
3.4 有水军吗?
这里可以看看是不是有评论的人故意刷评论或者回复呢?如果存在大量的同一个id发出的消息,那么极有可能属于水军(当然还有一种可能就是热门评论数据的观众姥爷们之间的互动,还有可能是‘键盘侠’)
df_shuijun = df[['member','comment']].groupby(by = 'member').count().sort_values(by = 'comment',ascending = False)
#进行分组计数,然后按照从大到小的顺序进行排列
#df[df['member'].str.contains('华洛丽桑卓')]
#这个是用来查找包含某个内容的原始数据
len(df_shuijun[df_shuijun['comment'] >= 10])
#查看一下动态超过10条的数据量,也就是下面61的依据
shuijun_data_over_10 = df_shuijun.iloc[:61]
x = shuijun_data_over_10.index.tolist()
y = shuijun_data_over_10['comment'].tolist()
#设置x,y数据
bar = pe.Bar('水军数据排行榜')
bar.add('动态数据大于10条的排名信息', x, y, is_datazoom_show = True,
datazoom_range = [0,100], mark_line=[ "average"],
tooltip_axispointer_type = 'cross')
bar.render('4.html')
→ 输出的结果为:(可以看到竟然有一个人动态数量达到了108条,这个明显属于异常数据)
查看一下这个异常数据对应的原始数据(使用同样的方法,就可以查看所有动态量大于10条所对应的的原始数据)
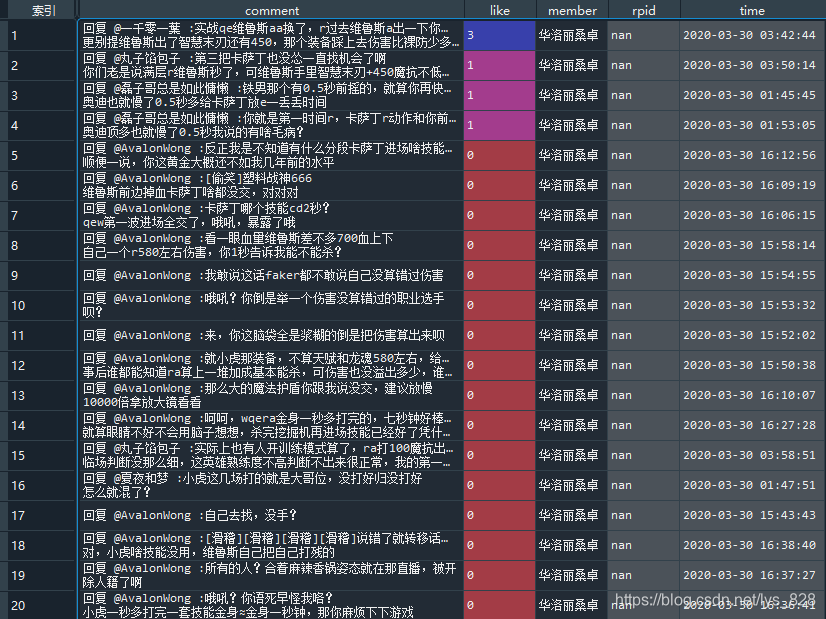
data_lsz_50 = df[df['member'].str.contains('华洛丽桑卓')].sort_values(by = 'rpid',ascending =False).head(20).set_index(np.arange(1,21))
→ 输出的结果为:(经过前20条数据中的content内容基本可以看出来,这个姥爷应该属于‘键盘侠’类的高手,至于其他的人员的数据也可以按照此方式进行数据的查看,最终可以确定是否真正的存在水军在水评论的现象)
4. 溜了
本想写一个爬虫的,结果发现到手了1w多条数据,忍不住就手贱了,非要分析一下,这么一整就凌晨两点半了,挺秃然的…

