我好久没来csdn写文章了,为什么呢?说句实话,其实不是自己不来写文章了,而是自己太关注形式化的东西了,有一段时间把文章写在github上面,感觉有自己的站点很特殊,很与众不同。其实用github来写文章确实是很不错的,使用mackdown标记语言给人一种高效编写的感觉。所以打算好好利用这两个平台,csdn的简洁性,可以让自己在使用windows系统时写一写技术文章同时很好地与他人进行评论交流。在使用linux系统时,可以利用终端的特性,使用git,写一写博客。行了,自己不在纠结了,就这么定了。编程练习固然重要,但是不总结也难以有收获。只希望把自己所遇、所悟、所感都记录成文字,这样一步一步积累,最终希望自己有一个质的蜕变。
————————————————————————————————————————————————————
下面介绍webmagic爬虫,爬取拉勾网的职位信息。
第一步:利用chrome和火狐检查链接
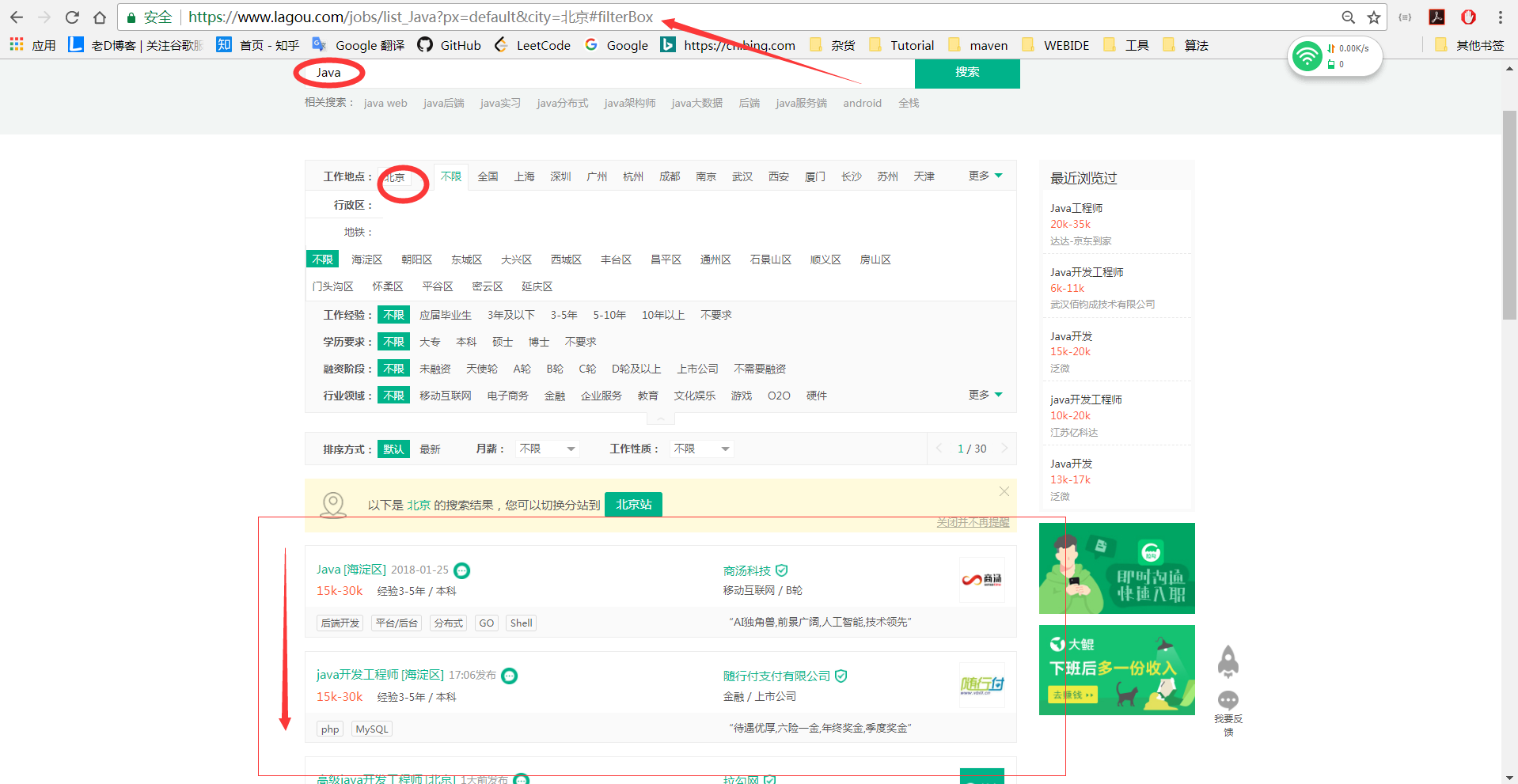
查看链接后,我们检查元素会发现这个链接不是我们需要的,因为类似于这种网站,数据的传输都是利用ajax的,所以进行第二步。
第二步:启用chrome调试,抓包分析
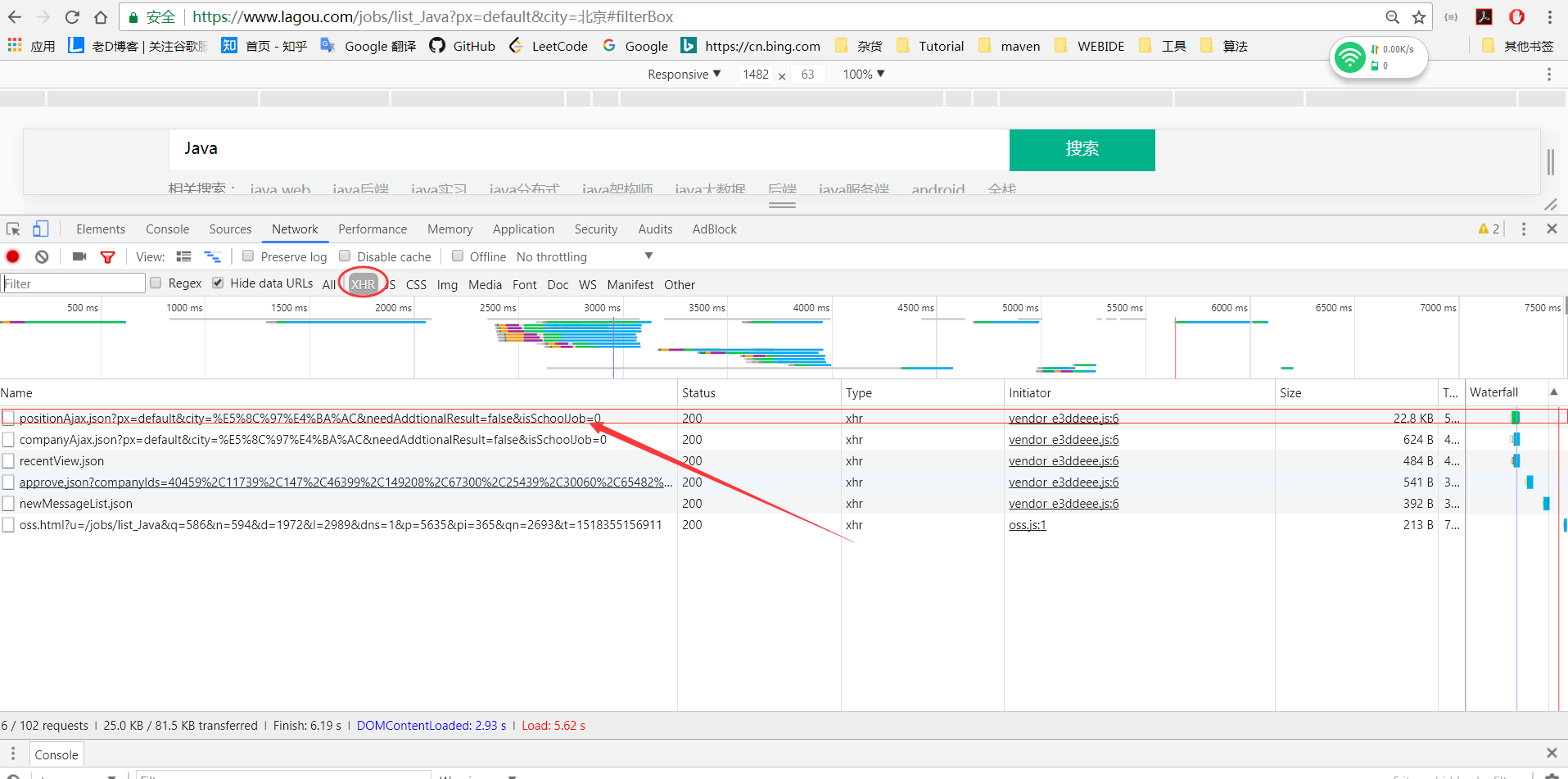
点击xhr(XmlHttpRequrest)F12后,可以看见以上ajax链接,从名字便可以看出来,第一个便是我们所需要的职位信息,点击链接查看详细信息。
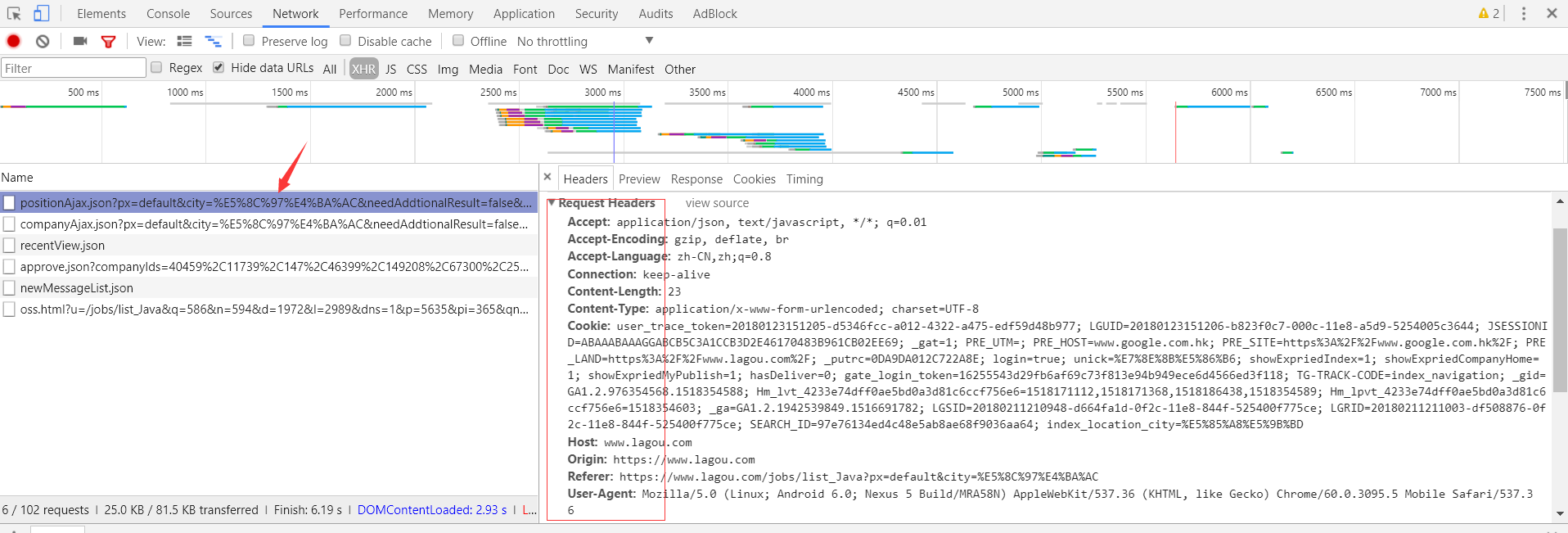
如上图所示,request-header信息全部显示在右侧,这个信息至关重要,因为这是你能够访问这个链接的重要认证。下面看一下此链接所传输的数据,点击Preview如下图所示:
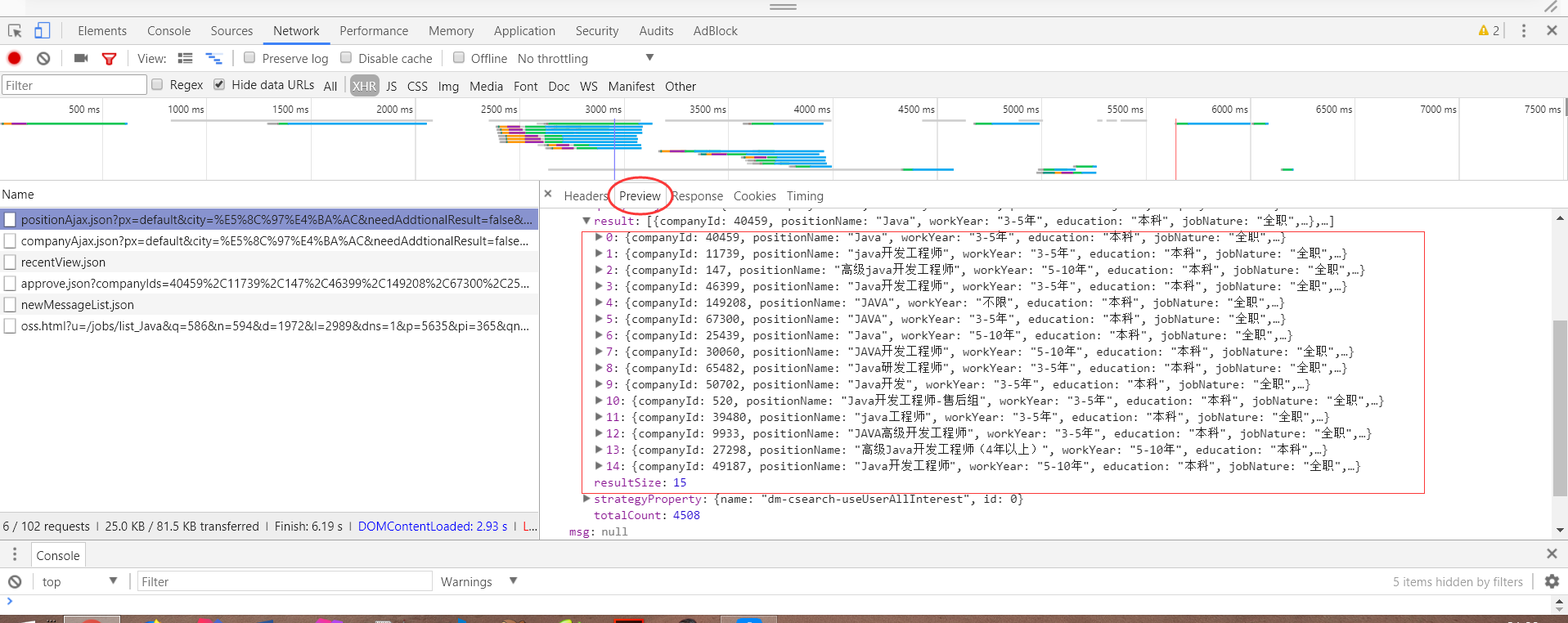
所有的职位信息都在这了,当然这也是固定页的职位信息,当页数不一样时,传递的职位信息不一样,这个需要考虑到post请求,后面会讲到。好,接下来,正式爬取。请看代码
private Site site = Site.me()
.setRetryTimes(3)
.setSleepTime(1000)
.addHeader("Accept","application/json, text/javascript, */*; q=0.01")
.addHeader("Accept-Encoding","gzip, deflate, br")
.addHeader("Accept-Language","zh-CN,zh;q=0.8")
.addHeader("Connection","keep-alive")
//.addHeader("Content-Length","23")
.addHeader("Content-Type","application/x-www-form-urlencoded; charset=UTF-8")
.addHeader("Cookie","Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1516684224,1516688332,1516708458,1517989813; _ga=GA1.2.803780703.1515996477; user_trace_token=20180115140756-6e315eee-f9ba-11e7-a353-5254005c3644; LGUID=20180115140756-6e316229-f9ba-11e7-a353-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; JSESSIONID=ABAAABAAADEAAFI7B8A950147564B82F61A115D162E1281; LGSID=20180207155015-888d0972-0bdb-11e8-bdd2-525400f775ce; LGRID=20180207163606-f07d2f3d-0be1-11e8-af98-5254005c3644; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1517992563; TG-TRACK-CODE=index_navigation; SEARCH_ID=ada31aea74d74f0ba5625adf851d1c6f; X_HTTP_TOKEN=4235610f3926fcdc9a4b942f0c350399; _putrc=0DA9DA012C722A8E; login=true; unick=%E7%8E%8B%E5%86%B6; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; gate_login_token=fc49718b5340e22bfe7adebb2937015b765f94906d1f154c; _gat=1")
.addHeader("Host","www.lagou.com")
.addHeader("Origin","https://www.lagou.com")
.addHeader("Referer","https://www.lagou.com/jobs/list_Java")
.addHeader("User-Agent","-Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3095.5 Mobile Safari/537.36")
.addHeader("X-Anit-Forge-Code","0")
.addHeader("X-Anit-Forge-Token","None")
.addHeader("X-Requested-With","XMLHttpRequest");这段代码,熟悉webmagic可以迅速看懂,设置site,这里建议大家写成这样,可以清楚地看出自己哪些请求头参数没有填写,重点讲解一下:
1.Cookie : 其实cookie便是模拟登陆的简单实现,也可以通过发送post请求,实现登录。请记住,此处的cookie一定是你登录后浏览这一页的时候的cookie
2.User-Agent :用户代理,这个并不是IP代理,而是一般网站的反爬机制。
3.Referer:这个东西是拉钩网目前为止的反爬机制,其实这个标记,它代表这你访问当前链接的上一个链接,就是你是在A页面点击跳转到B页面,那么B页面的Referer便是A链接。查看后,你会发现当前页面的referer链接为:
https://www.lagou.com/jobs/list_Java?px=default&city=%E5%8C%97%E4%BA%AC
你可能会问这么多参数,万一变化怎么办,其实都是骗人的,我们打开火狐浏览器检验一下:
点击编辑和重发
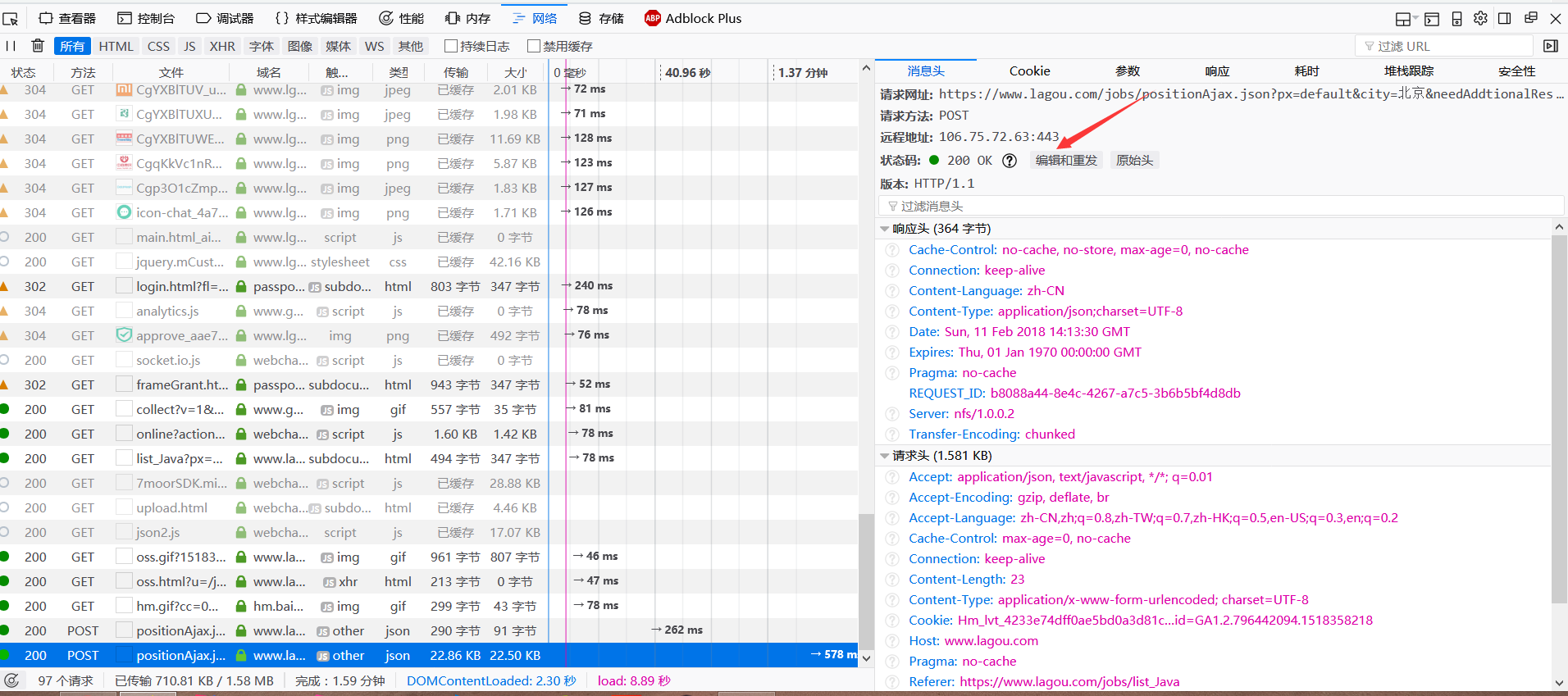
重新填写请求,将referer的链接参数去掉:
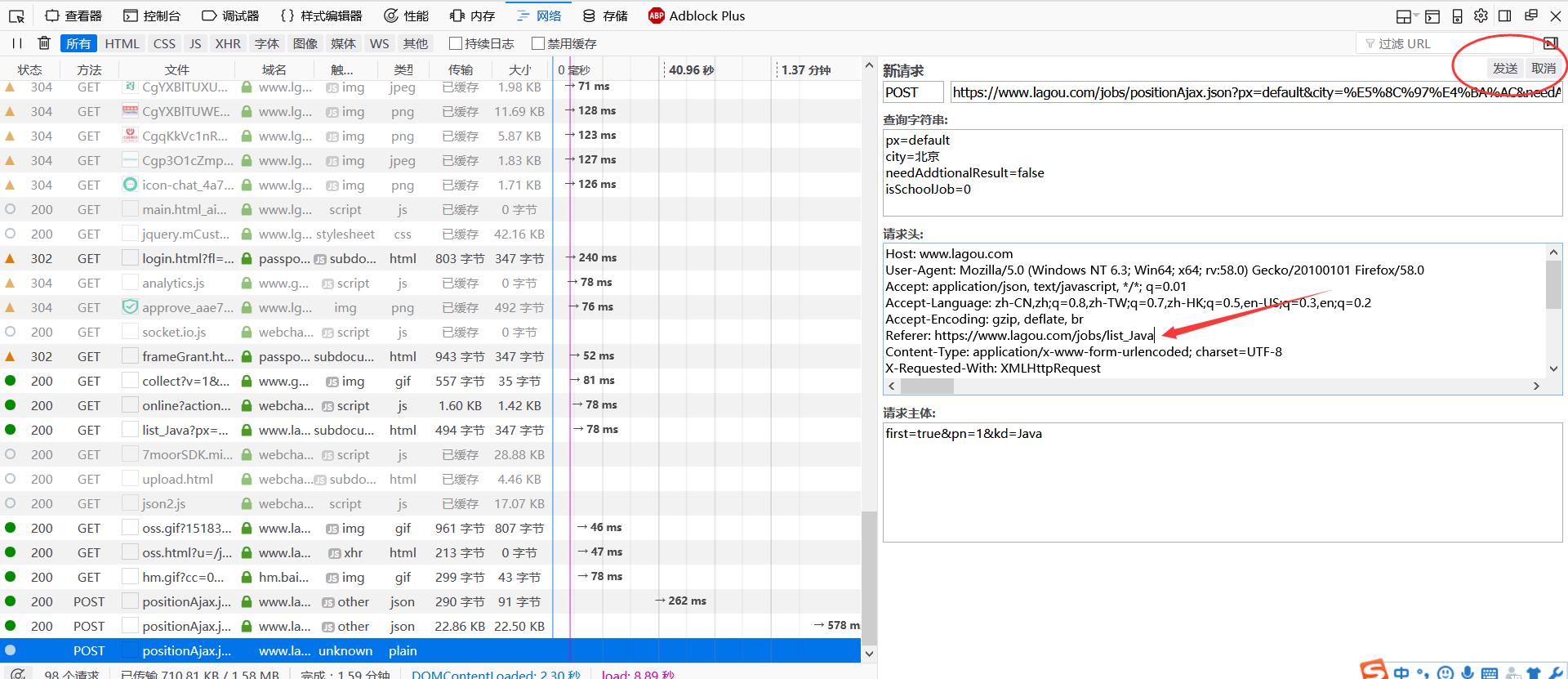
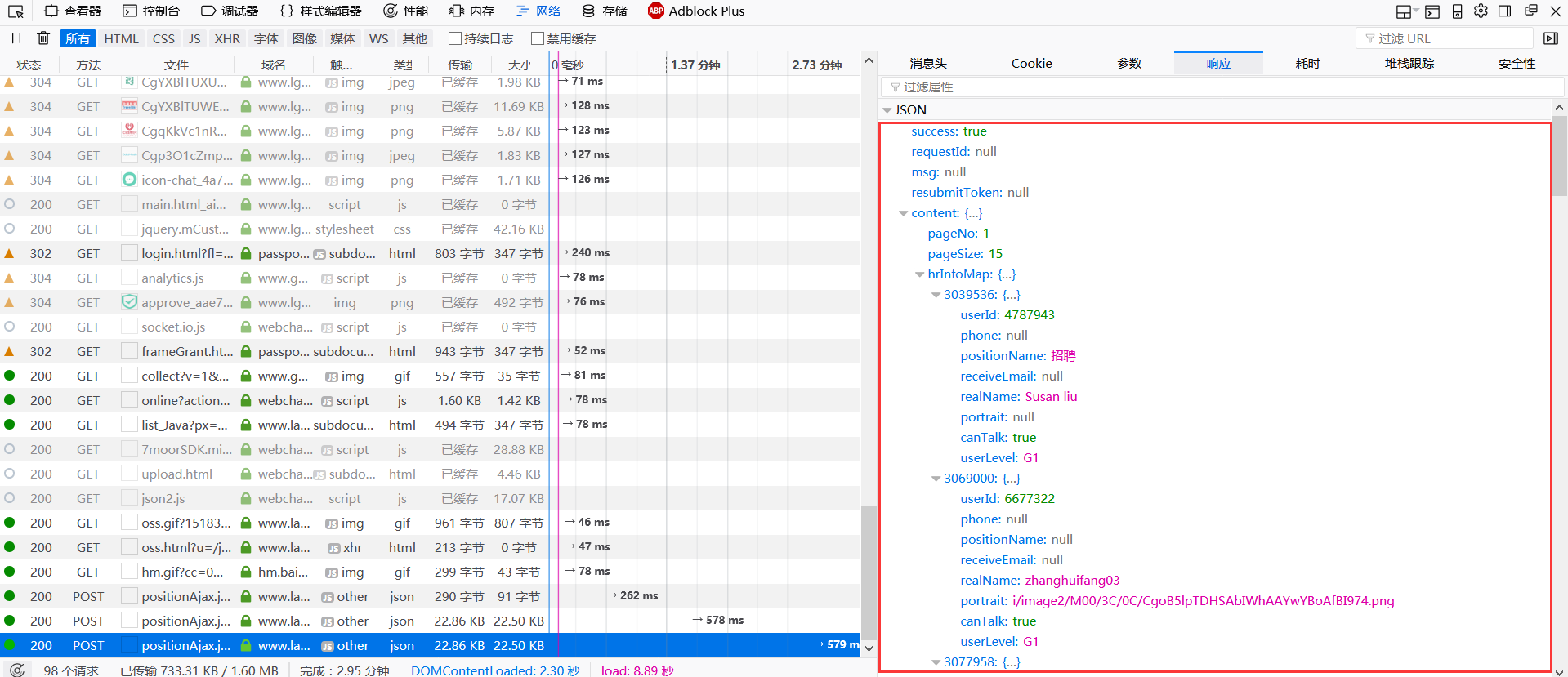
点击发送请求,查看显示JSON信息,可以看到,返回的JSON信息完全一样,可见参数不会影响。
4. Content-Length:可以看到这个属性注释掉了,为什么?请看google给出的解释:
content length是指报头以外的内容长度。 一般的服务器实现中,超过这个长度的内容将被抛弃。 不会产生新post。 如果短于内容长度,协议要求服务器返回400错误信息Bad Request(不正确的请求)的。
所以,一定要注释掉!
第三步:简单爬取JSON数据:
public void process(Page page)
{
// this.processBeiJing(page);
// this.processTianJin(page);
page.putField("position",new JsonPathSelector("$.content.positionResult.result[*].positionName").selectList(page.getRawText()));
}
public static void main(String []argv)
{
Spider.create(new LaGouSpider())
.addUrl("https://www.lagou.com/jobs/positionAjax.json?px=default&city=北京&needAddtionalResult=false&isSchoolJob=0")
.thread(2)
.run();
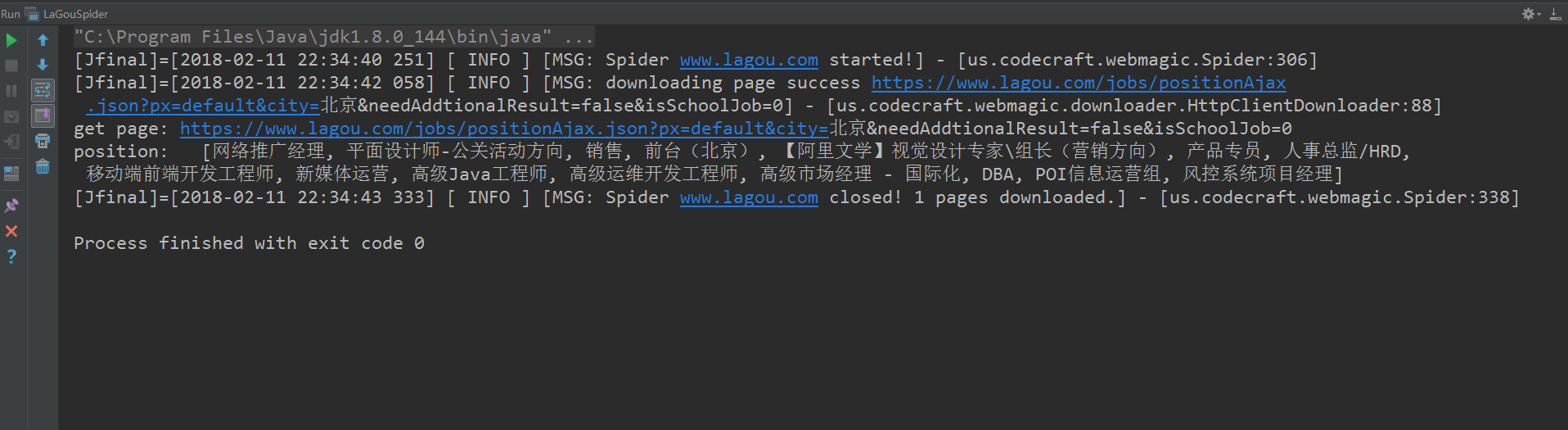
}写到这里,可以看出,爬虫重在分析!爬虫截图如下:
接下来,讲述一下发送post请求获取,分页的职位信息:
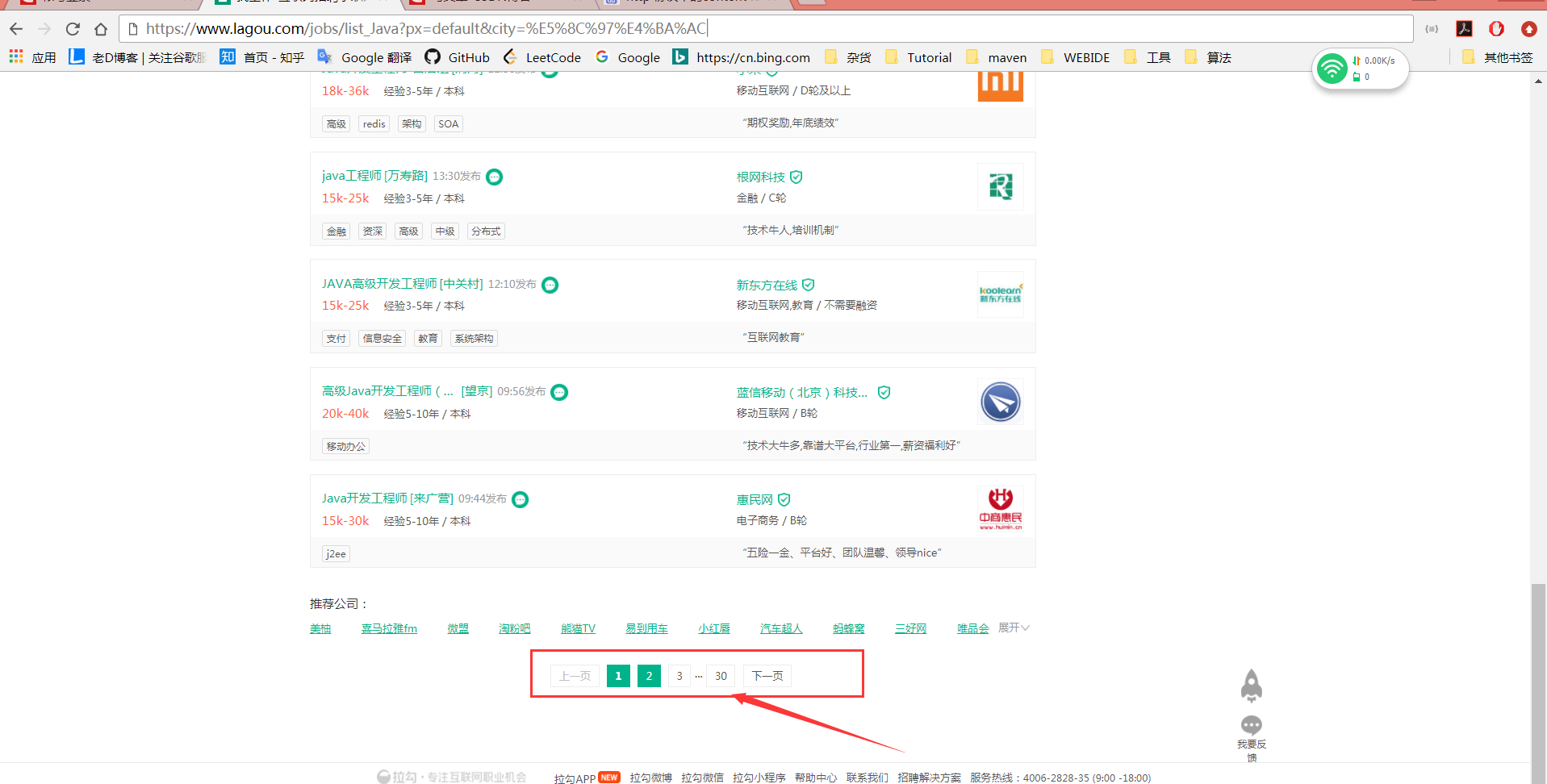
可以看到,这个页面共有30页,那每一页的链接又是怎么来的呢?请看下图:
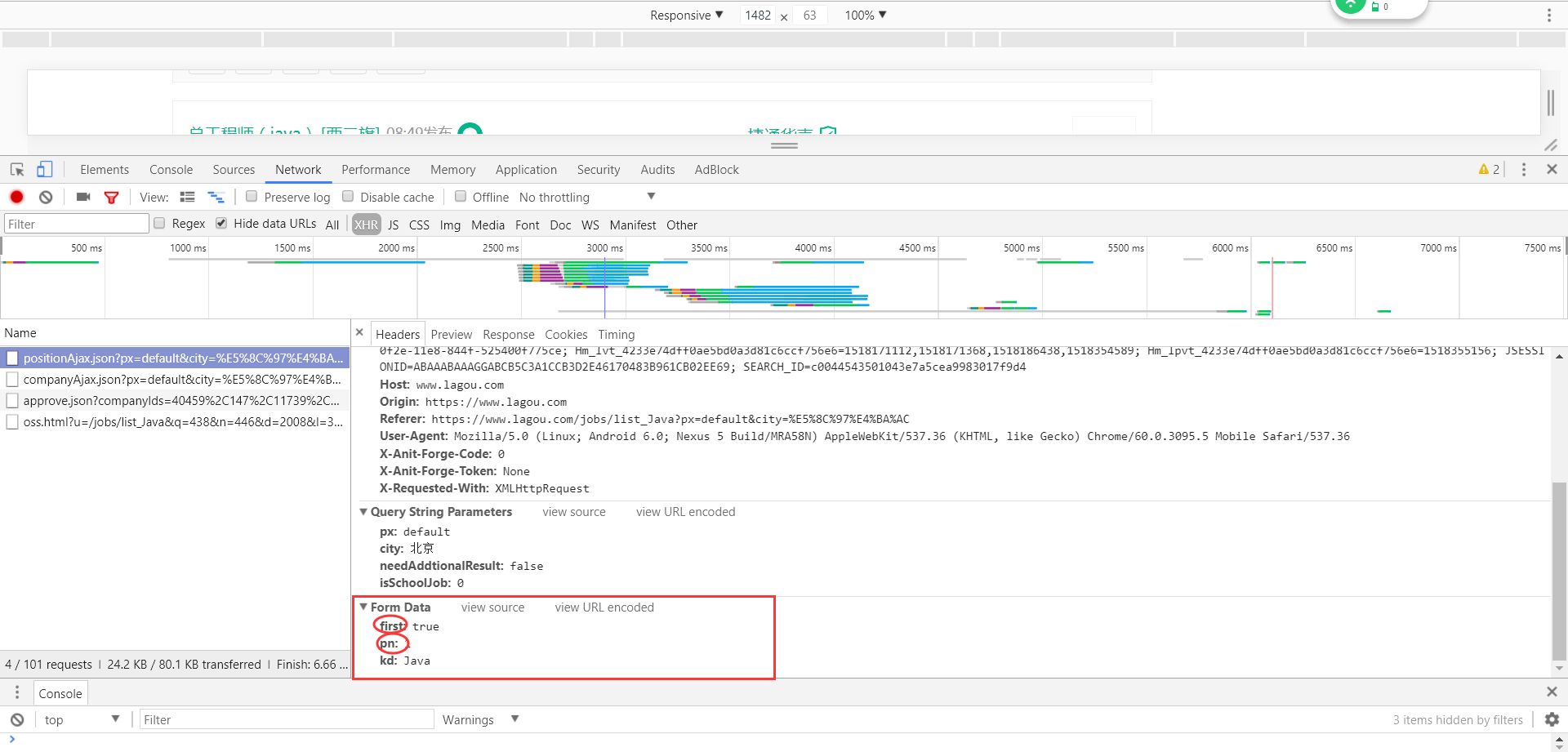
可以看到,first表示是否初次访问页面,pn表示页号,kd是关键字。那好了,我们只需要模拟发送30post请求,便可获取到不同页面的JSON信息。并且,webmagic提供了很好地POST方法,详情请看webmagic文档。代码如下:
public void processBeiJing(Page page)
{
if(flag==0)
{
Request [] requests = new Request[3];
Map<String,Object> map = new HashMap<String, Object>();
for(int i=0;i<requests.length;i++)
{
requests[i] = new Request("https://www.lagou.com/jobs/positionAjax.json?px=default&city=北京&needAddtionalResult=false&isSchoolJob=0");
requests[i].setMethod(HttpConstant.Method.POST);
if(i==0)
{
map.put("first","true");
map.put("pn",i+1);
map.put("kd","java");
requests[i].setRequestBody(HttpRequestBody.form(map,"utf-8"));
page.addTargetRequest(requests[i]);
}
else
{
map.put("first","false");
map.put("pn",i+1);
map.put("kd","java");
requests[i].setRequestBody(HttpRequestBody.form(map,"utf-8"));
page.addTargetRequest(requests[i]);
}
}
flag++;
}
}感觉代码还算清晰,稍做解释:
flag是标记,因为webmagic的post方法,队列中是不做去重处理的,也就是说,add方法没有办法检验队列中是否含有post请求,故会一直循环加入,无法停止。
好了,利用以上代码,便可怕取到1-30页的JSON信息。截图如下:
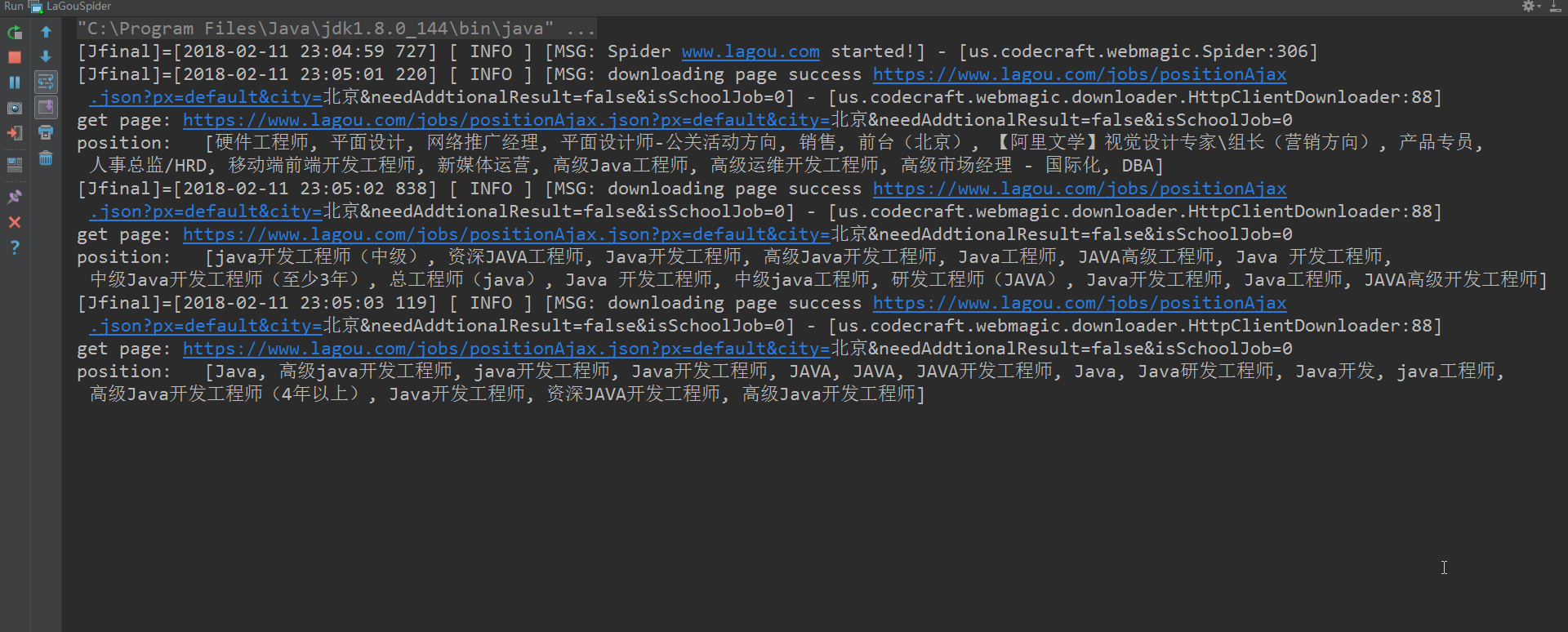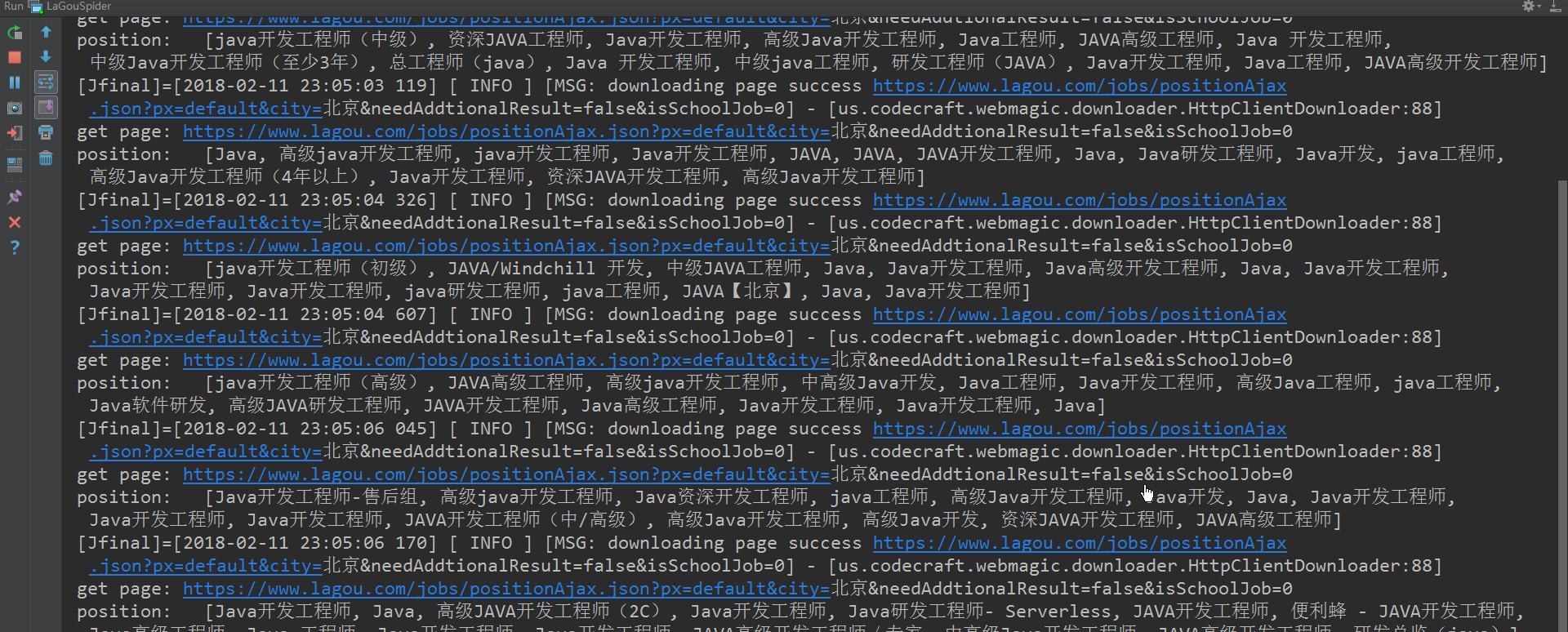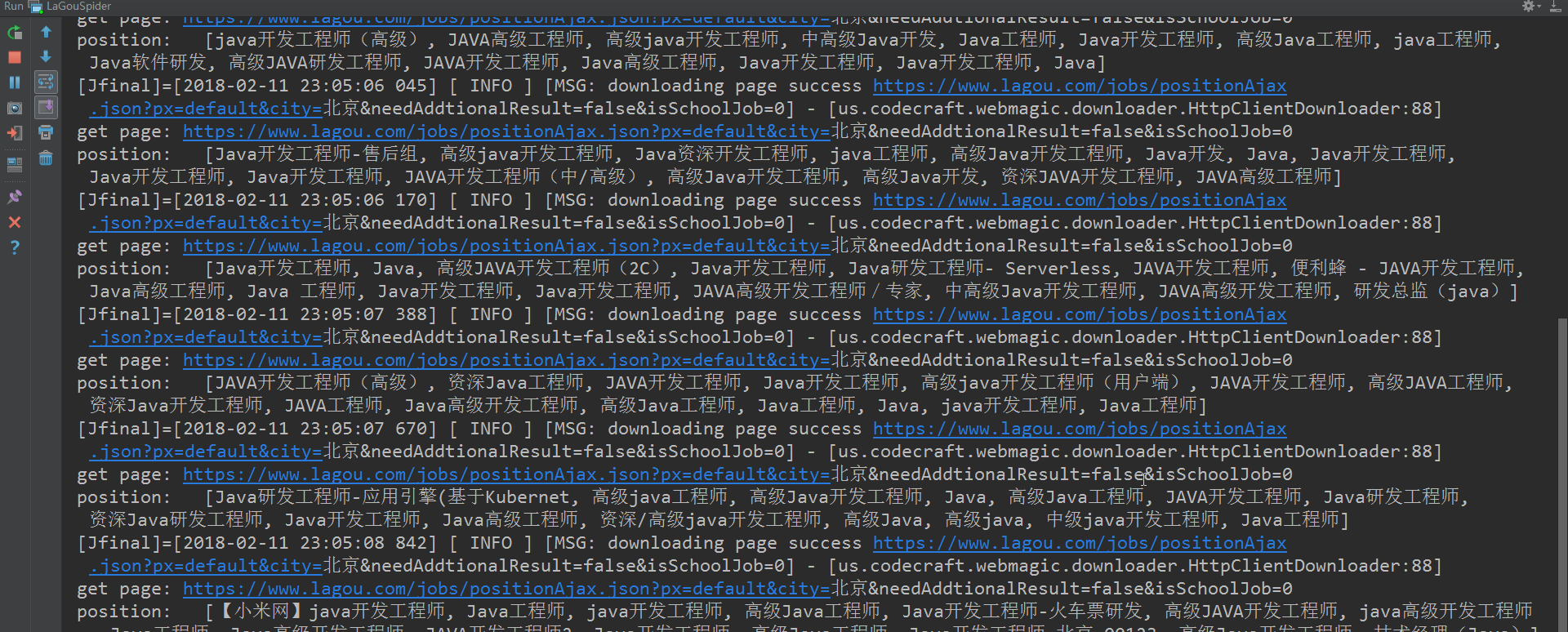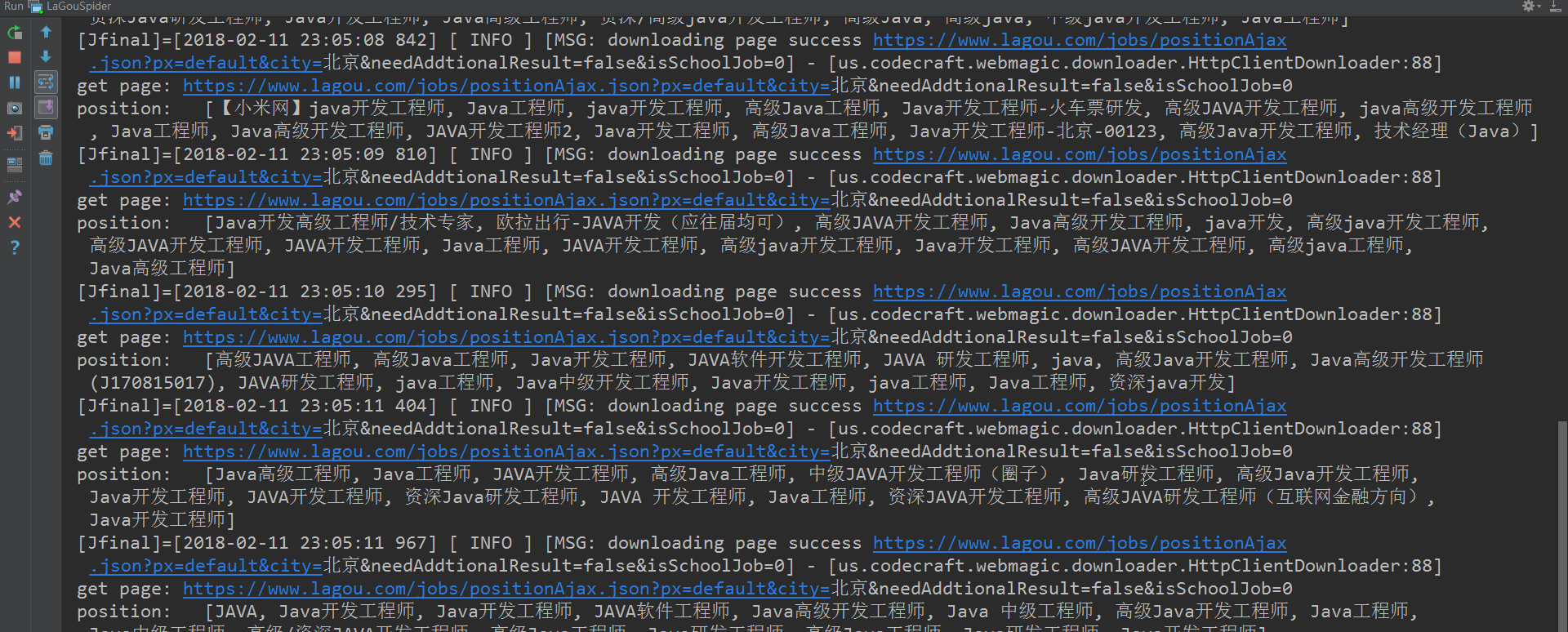
ok了,截止到现在,所有的步骤都已经讲解完成。代码文件已经上传至github点击打开链接(附带开源中国爬虫和哔哩哔哩视频爬虫源码),大家有问题可以留言交流,一起学习。
QQ:3091485316
微信:wangye889905