逻辑回归类似于多元线性回归,只是结果是二元的。它使用多种变换将问题转换成可以拟 合线性模型的问题。
概念/术语
- Logistic 函数
一种能将属于某个类的概率映射到 ±∞ 范围上(而不是 0 到 1 之间)的函数。(注意并不是最终的比例)
Logistic 函数 = 对数几率函数 - 几率
“成功”(1)与“不成功”(0)之间的比率。 - 结果变量:标签是 1 的概率 p(而不是简单二元标签)
结果变量 = 变量 y
假设函数
建模过程
首先,我们不能将结果变量简单看作二元标签,而应视为标签是 1 的概率 p。
若直接建模,并不能确保概率 p 位于 [0, 1] 区间内:
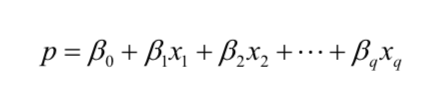
下面换一种做法。我们通过在预测因子中应用逻辑响应函数(逆逻辑回归函数)去建模p:
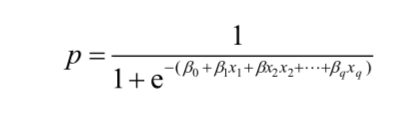
这一转换确保了 p 值位于 [0, 1] 区间内。
注意:
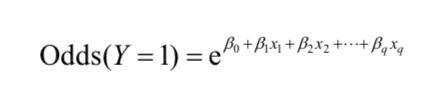
对等式两端取对数,得:
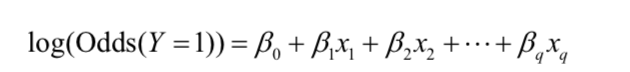
对数几率函数也称Logistic函数。
完成这样的转换过程后,我们就可以使用线性模型去预测概率。
逻辑回归模型
- 逻辑回归模型

- 逻辑函数
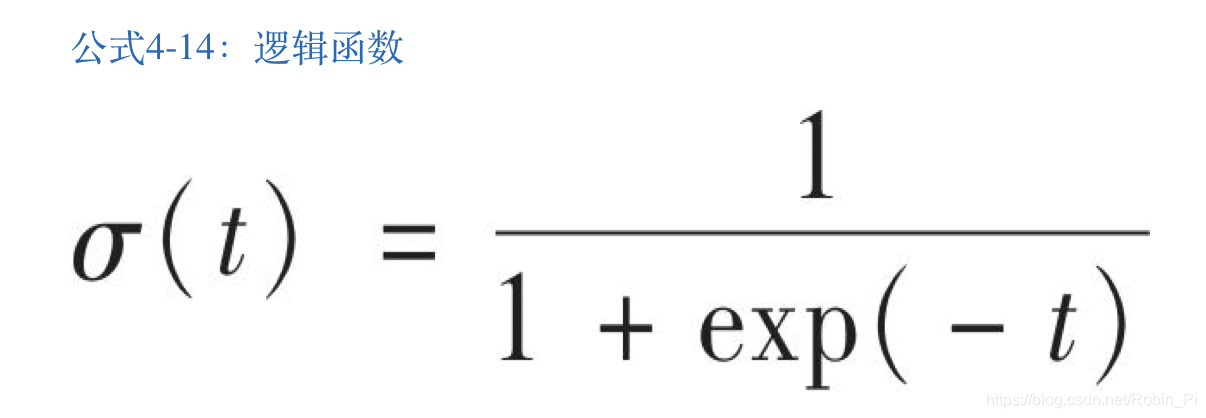
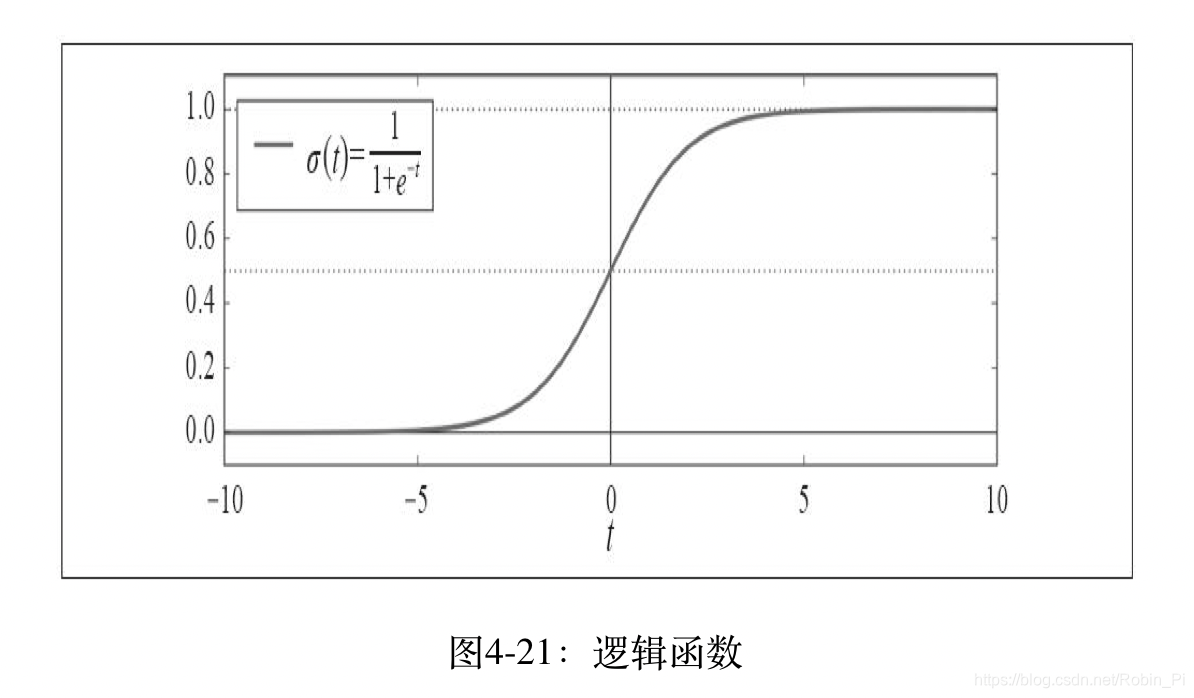
- 逻辑回归模型预测

损失函数
- 单个训练样本的损失函数

- 逻辑回归代价函数(log损失函数)
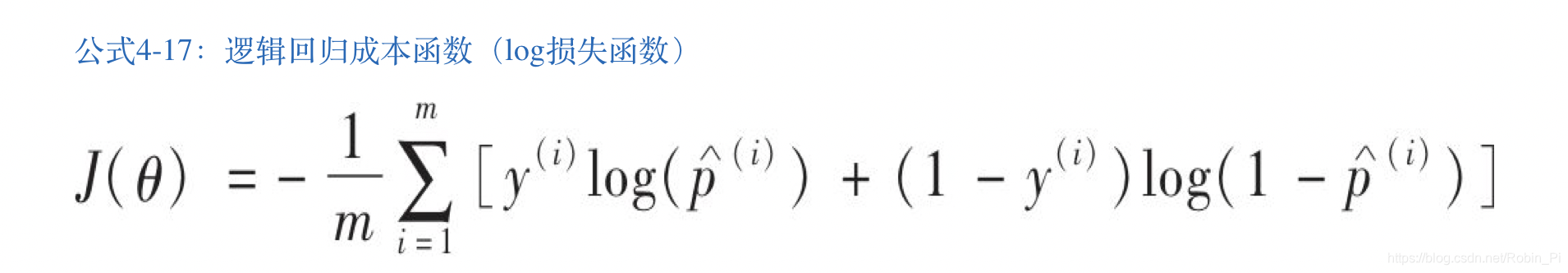
优化算法
逻辑回归代价函数没有已知的闭式方程(不存在一个标准方程的等价方程)来计算出最小化成本函数的θ值。但是,这是个凸函数,所以通过梯度下降(或是其他任意优化算法)保证能够找出全局最小值
代码实例
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
iris = datasets.load_iris()
list(iris.keys())
# 我们试试仅基于花瓣宽度这一个特征,创建一个分类器来检测Virginica鸢尾花。
X = iris["data"][:, 3:] # petal width
y = (iris["target"] == 2).astype(np.int) # 1 if Iris-Virginica, else 0
log_reg = LogisticRegression()
log_reg.fit(X, y)
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
y_proba = log_reg.predict_proba(X_new)
y_proba
plt.scatter(X, y)
plt.plot(X_new, y_proba)
# plt.plot(X_new, y_proba[:, 1], "g-", label="Iris-Virginica")
# plt.plot(X_new, y_proba[:, 0], "b--", label="Not Iris-Virginica")
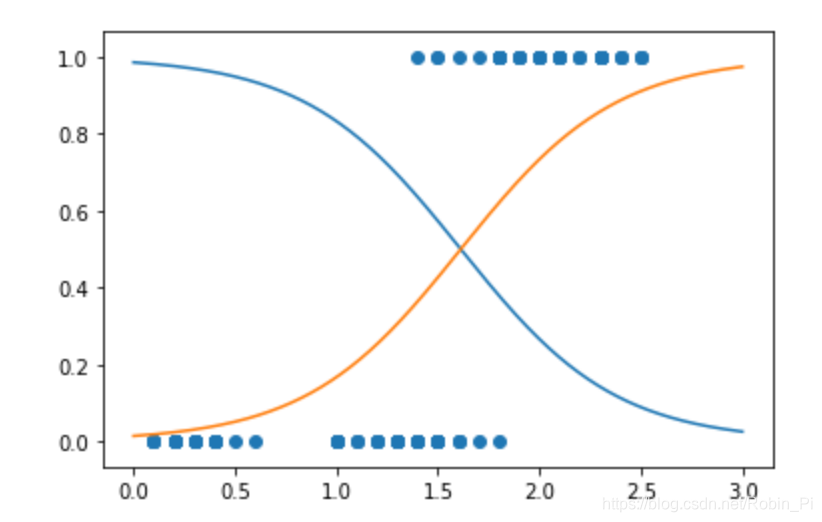
注意,这里有一部分重叠。在大约1.6厘米处存在一个决策边界,这里“是”和“不是”的可能性都是50%
