一:算法介绍
在前一篇文章中介绍了线性回归算法进行预测分析,但是实际生活中这个算法有它的局限性,比如对于分类问题,我们想要区分一个邮件是不是垃圾邮件,它只有两个可能的标签,0或者1,那么用回归算法来解决就不是那么明智了,因此今天我们介绍一种经典的分类算法,逻辑回归算法。它可以用来做分类,具体的说是二分类。
逻辑回归(Logistic)算法虽然名字里有回归两字,但是它并不是用来做回归的,而是一个分类算法,至于它为什么被称为回归,我学到的是历史原因
二:激活函数(sigmoid函数)
逻辑回归的前半部分其实和线性回归是一样的,他也是一个线性表达式:y = w * x + b;但是这样的话y的输出值的范围就很大了,为了把y的输出值变成0或者1,我们使用了一个很重要的函数,sigmoid函数,简称为S函数,他的公式是这样的:
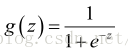
为什么它可以把y的输出值规范到0或者1呢,我们可以画出它的图像来看一下:

注意这里的h(x)就是一个线性表达式,从图像可以看出,即使S函数的输入的范围是负无穷到正无穷,函数的输出仍然在0到1之间,而且这个函数本身是光滑可导的,那么它就是可以求导的。这就为之后我们使用梯度下降法进行优化提供了方便。
当然能实现这个类似缩放功能的函数不止s函数,但s函数的确是比较好的选择,注意在机器学习中这类函数有一个统一的名字,叫做激活函数。
当然还有最后一步,为了让y的值离散化,我们会以0.5为界限,小于0.5的划为0,大于或者等于0的划为1。
三:代价函数:
我们可不可以使用我们在线性回归中定义的代价函数呢?答案是否定的,原因是这会得到一个非凸函数,通简单说就是有很多局部最优值,无法得到全局最优解。因此有人提出了另一种代价函数,如果你看过Andrew Ng的机器学习视频,那么他是这样描述的:

其中:
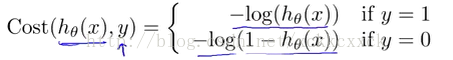
为什么这个代价函数比较好呢,我们可以从它的图像进行分析:
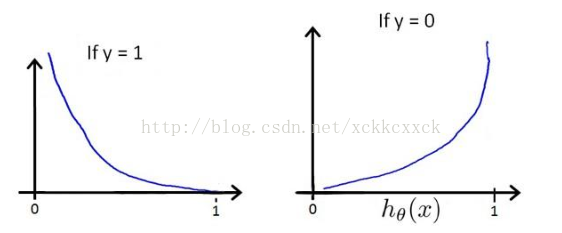
从图中可以看出,当y=1时,h=1,如果h不为1时误差随着h的变小而增大;同样,当y=0时,h=0,如果h不为0时误差随着h的变大而增大。
四:梯度下降法:
Ng给出了这个函数的梯度下降方式。

对于以上的代价函数,其实是可以利用极大似然估计推导出来的,但是我暂时没有掌握这个,梯度下降的公式也可以推导出来,这里就不记录了。
五:总结:
以上介绍了机器学习中的逻辑回归算法,我在我的github上写了一个算法的python的实现。感兴趣的可以看一下。