1.逻辑回归(Logistics Regression),简称LR。它的特点是能够使我们的特征输入集合转化为0和1这两类的概率。
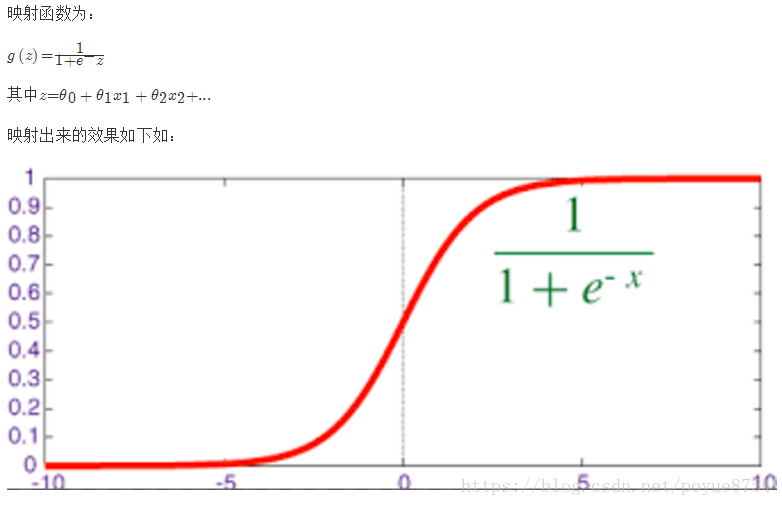
2.良/恶性肿瘤预测:
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.metrics.classification import classification_report
from sklearn.model_selection._split import train_test_split
from sklearn.preprocessing.data import StandardScaler
import numpy as np
import pandas as pd
def logistic():
#逻辑回归做二分类进行癌症预测(根据细胞的属性特征)
#构造标签名字
column = ['Sample code number','Clump Thickness', 'Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class']
#读取数据
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",names = column)
#print(data)
#缺失值进行处理
data = data.replace(to_replace='?',value=np.nan)
data = data.dropna()
#进行数据的分割
x_train,x_test,y_train,y_test = train_test_split(data[column[1:10]],data[column[10]],test_size=0.25)
#进行标准化处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
#逻辑回归预测
lg = LogisticRegression(C=1.0)
lg.fit(x_train,y_train)
y_predict = lg.predict(x_test)
print(lg.coef_)
print("准确率:",lg.score(x_test,y_test))
print("召回率:",classification_report(y_test,y_predict,labels=[2,4],target_names=["良性","恶性"]))
return None
if __name__=="__main__":
logistic()运行结果为:
