文章目录
1 摘要
随着CNN的不断发展,涌现了很多深度较深的CNN如ResNet系列,它们非常适合用于完成稠密分割任务,如语义分割。但是由于CNN需要反复地进行下采样,这样导致了图像分辨率不断地降低,容易丢失了图像的一些空间信息,这样对于一些高分辨率的图像就非常不友好了。针对这个问题,作者提出一种RefineNet,引入了残差卷积模块(Residual Convolution Unit)、多分辨率融合模块(Multi-Resolution Fusion)和串联残差池化模块(Chained Residual Pooling)等结构,非常有效地对空间分辨率进行恢复,在7个数据集中均达到SOTA。
2 亮点
在当时,DeepLab是表现最好的网络,但是作者指出有两点缺陷:
① 在高分辨率图像中,存在高维特征,会使得DeepLab消耗大量计算资源。
② DeepLab使用空洞卷积虽然能够获得更大的感受野,但是这样会使得高分辨率图像的一些空间信息丢失,使图像变得粗糙。作者提出的RefineNet主要通过使用三大模块去避免这些问题。
2.1 残差卷积模块(RCU)
作者提出的RCU模块参考了ResNet的残差块,在模块内分成两条线路,如下图:
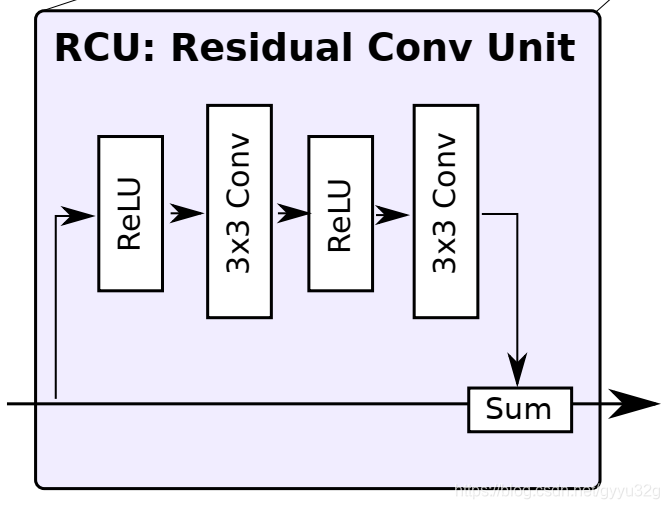
主干线为图像直接的输入,而支线的图像先经过ReLU、3x3卷积、ReLu、3x3卷积,再与主干线路进行特征融合叠加,残差卷积部分可以理解为对特征图进行信息的补充,使得图像信息更加丰富。
2.2 多分辨率融合模块(MRF)
图像通过残差卷积模块以后便要进入MRF模块,MRF模块主要是对不同尺度的图像进行特征提取和上采样到同样的分辨率,最后进行融合,如下图:
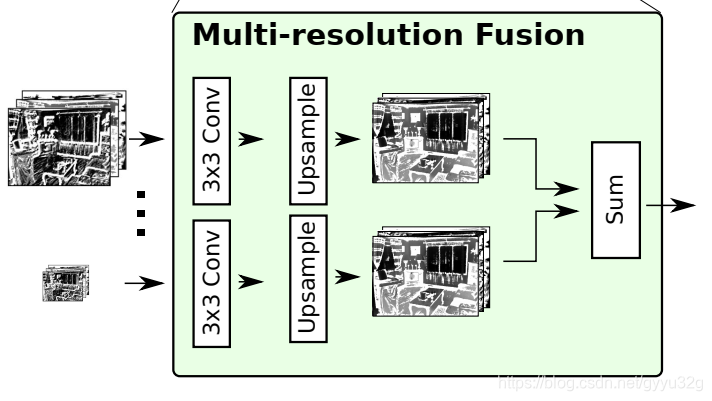
不同尺度的图像都进入对应的通道进行3x3卷积,再进行一个双线性插值法的上采样,不同通道的图像最终都上采样成同一分辨率的图像,最终进行融合叠加,将结果送往下一层。
2.3 串联残差池化模块(CRP)
MRF的下一层便是CRP模块了,可以说前面两个模块的作用都是通过将不同分辨率的图像信息进行融合,而CRP模块的作用主要是捕获背景信息,将图像背景信息丰富,如下图:
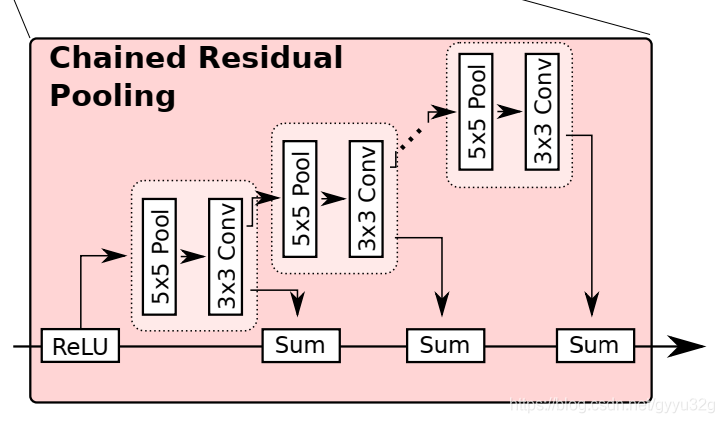
输入图像经过ReLU再经过第一个池化卷积模块得到的结果与直接经过ReLU的图像进行融合;后面的池化卷积模块层层级联进行同样的操作,作者提出,池化卷积模块不是每次进行sum以后重新开始池化卷积而进行层层级联,这样有利于它学习到更加深层的信息,更有利于对整体结果的校正与补充。
2.4 RefineNet模块结构
标题之所以称RefineNet模块结构,是因为醉作者再在RefineNet总体结构中又包含了下图这个模块。
而上图这个模块整体就是由残差卷积模块(RCU)、多分辨率融合模块(MRF)、串联残差池化模块(CRP)三个模块进行拼凑起来,最后经过1个RCU模块平衡所有的权重,最终得到与输入空间尺寸相同的分割结果。所以说其实RefineNet也算是一个模块,这个模块类似于一个将输入图像进行稠密特征提取的模块(整体上看类似与一个带填充的卷积模块,只不过这个卷积模块效果很好,可以提取到很完整的特征信息)。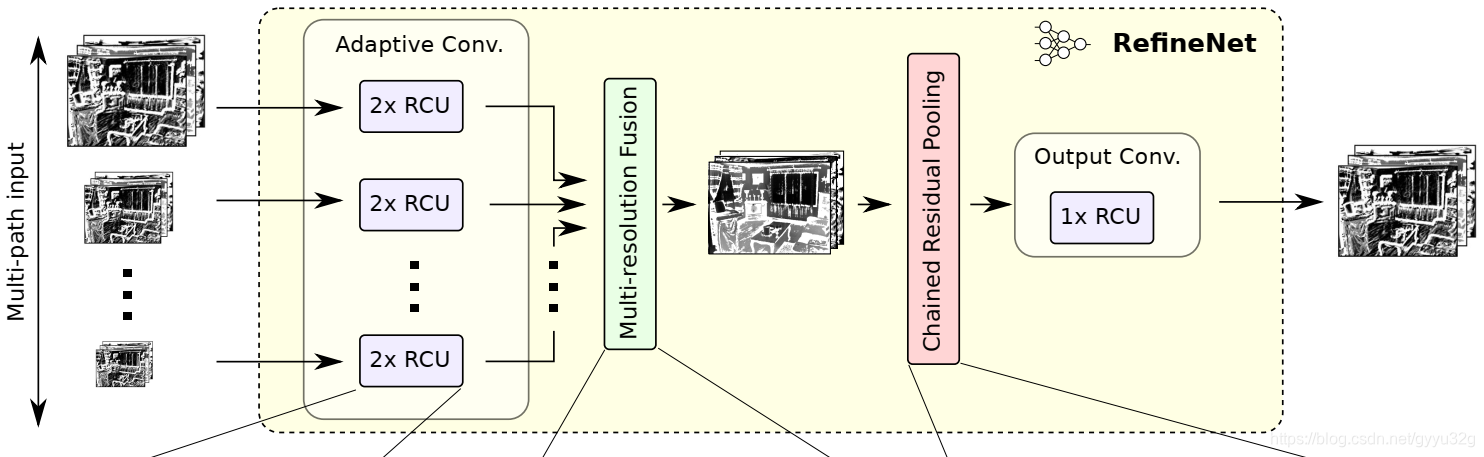
2.5 RefineNet整体网络结构
在介绍RefineNet总体网络结构以前,作者先对ResNet和空洞卷积网络结构进行了分析,其如下图:
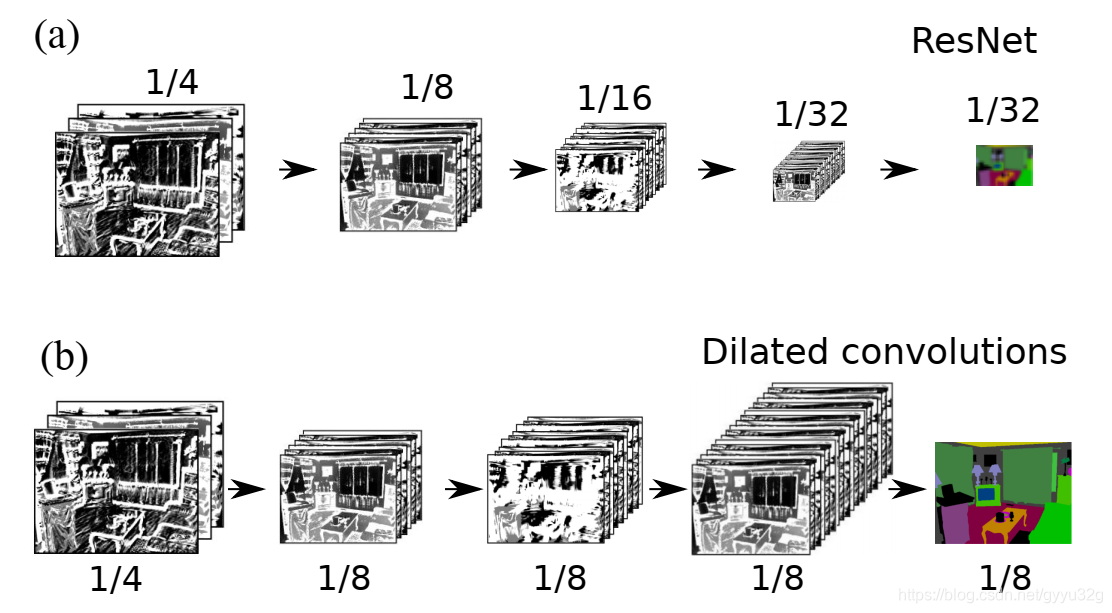
(a)中为ResNet结构,由于连续不断的池化,图像从输入1/4到最终输出已经变成1/32,图像的很多重要信息已经丢失了。而(b)中虽然使用空洞卷积代替了池化操作,但是由于空洞卷积没有缩小图像尺寸,所以参数量大,需要花费大量的计算资源。于是,作者提出(c),如下图:
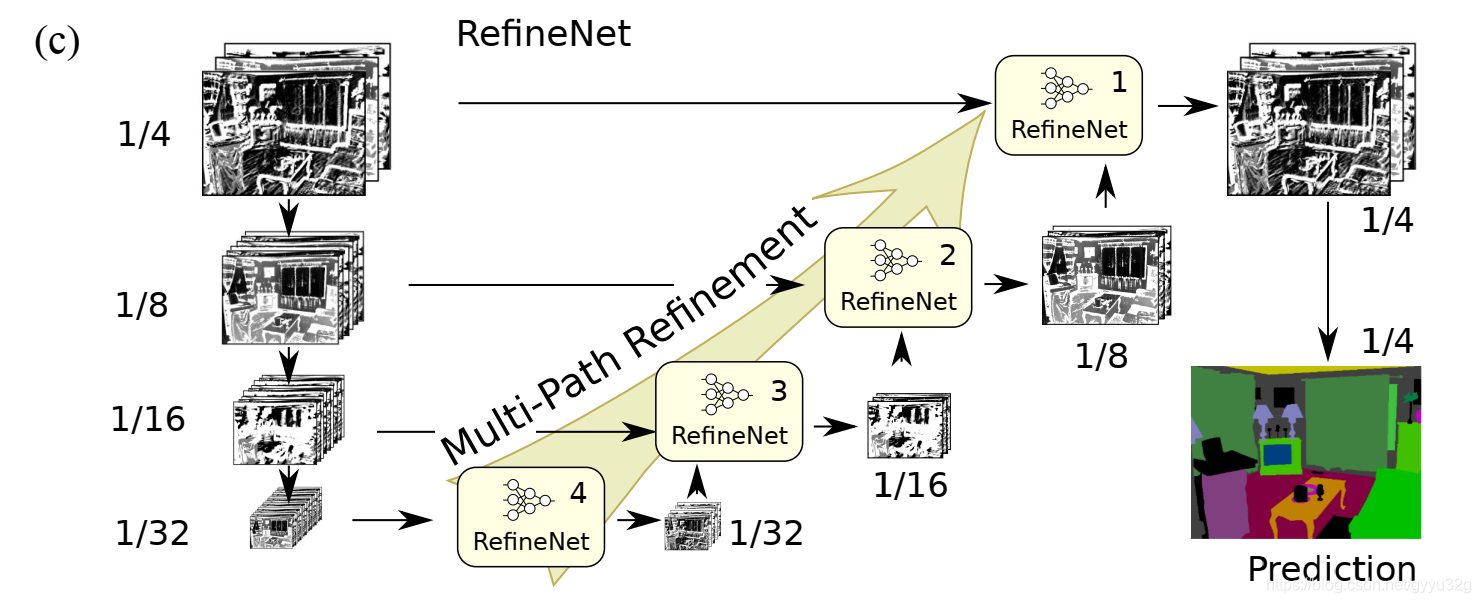
通过对图像的不同大小经过RefineNet模块(就类似于卷积的作用提取高分辨率特征)再层层融合,这样既能保证图像信息较为完整而且参数量较小,没有花费大量计算资源。可以看到,这个网络的整体结构非常类似U-Net,增添了RefineNet模块进行高分辨率的特征提取,U-Net结构如下图:
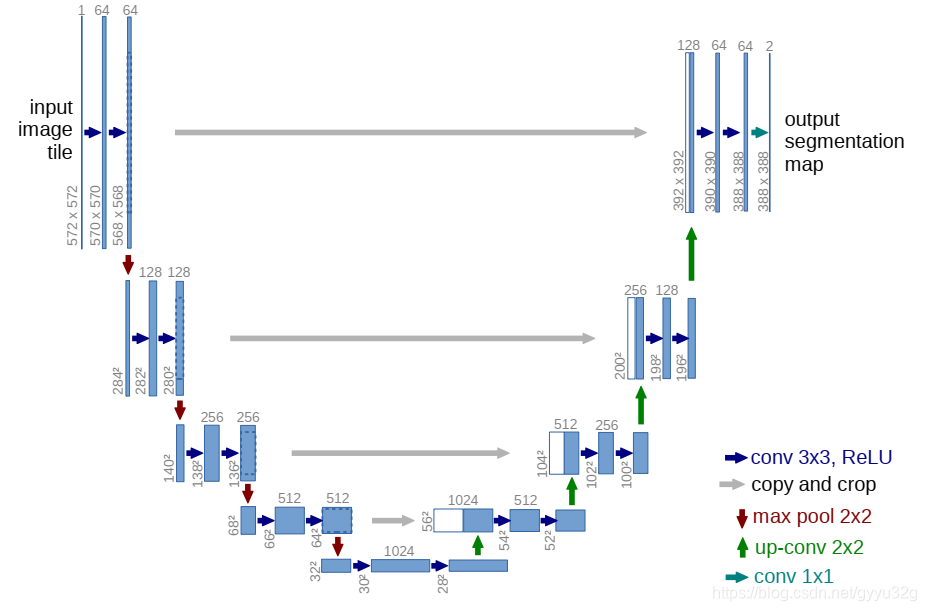
2.6 RefineNet变种结构
作者提出,RefineNet可以通过使用RefineNet模块进行不同的变种来适应不同的场合,如:
① 变种1:
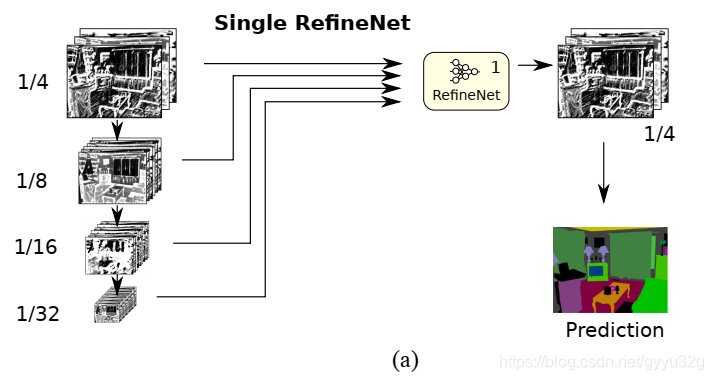
为仅仅使用一个RefineNet模块的结构。
② 变种2:
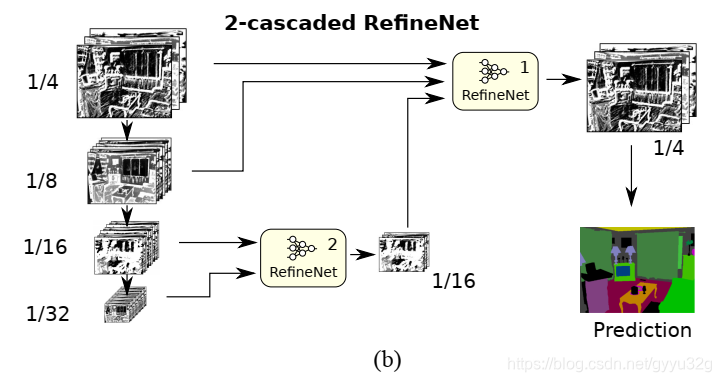
为使用两个RefineNet模块的结构。
③ 变种3:
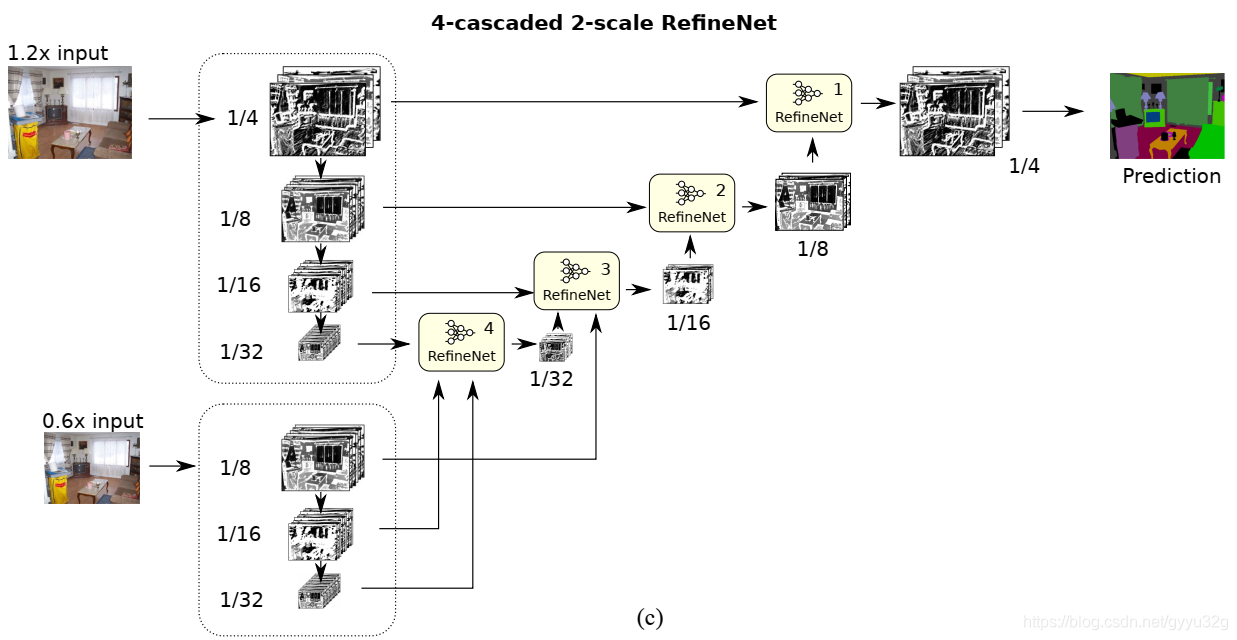
这个结构引入了两个尺度的图像,一个为1.2倍的输入图像,另一个为0.6倍的图像。0.6倍的图像处理最后作为辅助的融合信息传给1.2倍的子操作中。这样构成了两个尺度的RefineNet网络结构,微微比一个尺度的输入图像的结构准确率高。
3 部分效果
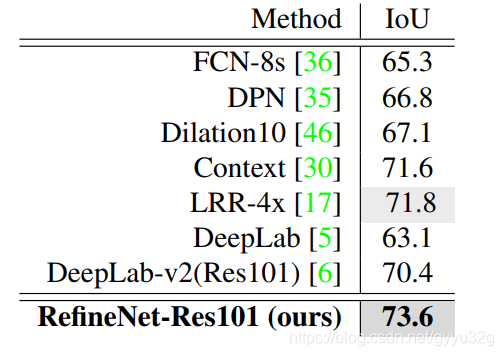
上图为各网络在Cityscapes测试集的IoU结果。

上图为不同变种网络在NYUDv2数据集中的对比,可见RefineNet模块越多,尺度越多,准确率越高。

该网络用在目标解析方面表现很好,上图为RefineNet在Person-Parts数据集上的效果,看起来非常不错。
4 结论
本文提出的RefineNet,其通过使用多分辨率图像的融合,能够有效地提取图像的丰富的特征信息,是不同于SPP、ASPP等解决多尺度问题的又一种方法。
5 参考文献
(1)RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
(2)【图像分割模型】多分辨率特征融合—RefineNet
