From:CVPR2019
Note data:2019/07/17
Abstract:引入一种CANet,一个类不可知的分割网络,可以对新类进行几次分割,只有少量带注释的图像。
Code :暂未开源
目录

5.2 Iterative Optimization Module
5.3 Attention Mechanism for k-shot Segmentation
1 Abstract
论文提出一种基于新的Senmantic segmentation模型CANet
网络结构:一个双分支密集比较模块,同时引入了注意力机制
创新:考虑到语义分割网络训练模型只局限于既定类别的问题,提出了新的分割思路,提出了CANet模型。
动机:像素分割的数据标记既有成本又有成本,已训练模型只能在一组预定义的类中进行预测。
在本文中,我们介绍了CANet,这是一个类不可知的分割网络,可以对新类进行几次分割,只有少量带注释的图像。 网络包括一个双分支密集比较模块,它执行支持图像和查询图像之间的多级特征比较,以及迭代优化模块,迭代地优化预测结果。 此外,引入了一种注意机制,以在k-shot学习的设置下有效地融合来自多个支持示例的信息。

2 Introduction
在以往的语义分割任务中使用大量的标注数据进行训练,同时训练模型的泛化能力也很差。在这篇论文中仅仅使用一些带标注的图像对新类进行分割。
先前的一些工作中采用双分支结构设计,包括支持分支和查询分支。支持分支目的从支持数据集中提取信息以指导查询分支中的分段。这篇论文采用相同的双分支设计来解决少数分割问题。
网络包括一个双分支密集比较模块,其中共享特征提取器从查询集和支持集中提取表示进行比较。密集比较模块的设计从图像分类任务的度量学习中获取灵感,其中距离函数评估图像之间的相似性。然而与每个图像具有标签的图像分类不同,图像分割需要具有结构化表示的数据进行预测。很难将度量学习应用于密集预测。
一种解决的方法就是在所有的像素对之间进行比较,然而造成巨大的计算成本。相反,我们目标是从支持图像中获取全局表示进行比较。为了只关注指定的类别,我们使用前景区域上的全局平均池化来过滤不相关的信息。然后将全局特征与查询分支中的每个位置进行比较,这可以看作是度量学习方法的密集形式。在少数设置下,网络应该能够处理在训练期间从未见过的新类。因此,我们的目标是从CNN中挖掘可转移的表示进行比较。
如在特征可视化文献中观察到的,较低层中的特征涉及低级线索,例如边缘和颜色,而较高层中的特征涉及诸如类别的对象级概念。我们专注于可能构成由看不见的类共享的对象部分的中间级功能。例如,如果CNN在类车上训练模型时学习与车轮相关的特征,则这种特征对于新车类(例如卡车和公共汽车)的特征比较也是有用的。我们在CNN中提取多个级别的表示以进行密集比较。
由于同一类别中的外观存在差异,因此来自同一类别的对象可能只共享一些类似的特征。密集特征比较不足以指导整个对象区域的分割。然而,这给出了对象所在位置的重要线索。在半自动分割文献中,弱类注释用于类不可知分割,例如,使用点击或涂鸦注释的交互式分割和具有边界框或极点前体的实例分割。在训练过程中学习定位对象区域的可传递知识。受半自动分割任务的启发,我们希望在将密集比较结果作为先验的情况下逐渐将对象与背景区分开来。我们提出一个迭代
优化模块(IOM),学习迭代地细化预测结果。细化以循环形式执行,密集比较结果和预测掩模被发送到IOM以进行优化,并且输出被反复发送到下一个IOM。经过几次细化迭代后,我们的密集比较模块能够生成细粒度的分割图。在每个IOM内部,我们采用残余连接以在最后的迭代步骤中有效地合并预测的掩模。

用于k-shot分割的先前方法基于1-shot模型。他们使用不可学习的融合方法融合单个1-shot结果,例如平均1-shot预测或中间特征。相反,我们采用注意机制来有效融合来自多个支持示例的信息。
为了进一步减少针对少数镜头分割的标注工作,我们探索了一种新的测试设置:我们的模型使用边界框注释支持集来在查询图像中执行分割。我们对PASCAL VOC 2012数据集和COCO数据集进行了全面的实验,以验证我们网络的有效性。
本文的主要贡献概括如下。
- 开发了一种新颖的双分支密集比较模块,该模块有效地利用来自CNN的多级特征表示来进行密集的特征比较。
- 提出迭代优化模块,以迭代方式改进预测结果。迭代细化的能力可以推广到具有少量镜头学习的看不见的类,以生成细粒度图。
- 采用注意机制有效地融合来自k-shot设置中的多个支持示例的信息,其优于单次结果的不可学习的融合方法。
- 证明给定的支持集具有弱注释,即边界框,我们的模型仍然可以获得与昂贵的像素级注释支持集的结果相当的性能,这进一步减少了新类别对于少数镜头分割的标记工作量。
- PASCAL VOC 2012数据集的实验表明,我们的方法实现了单次分割的IOU得分为55.4%,5次分割得分为57.1%,其显着优于14.6%和13.2的最新结果。
3 Related Work
论文从小样本学习介绍相关的一些工作。few-shot旨在学习可转换的知识,这些知识可以推广到具有稀缺标记的训练数据的新课程。在few-shot中存在许多公式,包括具有记忆的RNN,细粒度模型,网络参数预测和度量学习。基于度量学习的方法在少数few-shot中实现了最先进的性能,并且具有快速和以前馈方式预测的特性。我们的工作与关系网络有很大关系。关系网络元学习深度距离度量以比较图像并计算分类的相似性得分。该网络包括生成图像表示的嵌入模块和比较嵌入并输出相似性得分的关系模块。我们网络中的密集比较模块可以看作是密集形式的关系网络的扩展,以解决分割任务。
few-shot语义分割。完全监督的语义分割是将图像中的每个像素分类为一组预定义类别的任务。另一方面,少数几个语义分段旨在将分割能力推广到任何新类别,只有几个带注释的label。以前关于few-shot语义分割的工作采用了双分支结构。首先采用语义分割的few-shot学习。支持分支直接预测查询分支中最后一层的权重以进行分段。支持分支生成嵌入,该嵌入与查询分支融合为附加特征。我们的网络也遵循双分支设计。但是,与以前两个分支具有不同结构的工作不同,我们网络中的两个分支共享相同的骨干网络。之前方法中的模型侧重于单次拍摄设置,当将1-shot延伸到k-shot时,他们将1-shot独立应用于每个支持示例,并使用不可学习的融合方法融合图像中的各个预测结果级别或功能级别。平均嵌入在由不同支持示例生成的支持分支中。相反,我们通过注意机制采用可学习的方法来有效融合来自多个支持示例的信息。
4 Task Description
假设我们的模型是在C_train数据集上进行训练,我们的目标是使得训练的模型在新的C_test上依然可以进行预测分割,其中只有少数的label可以使用。训练模型后参数固定后,新的数据集无需优化便可以测试新的类。这其中涉及一些K-shot的一些公式。我们将训练和测试与情节范式结合起来,以处理少数几个场景。 具体地,给定k-shot学习任务,每个片段通过样本1)支持(训练)集![]() 进行采样来构建的。
进行采样来构建的。
5 Method
论文提出了一个新的框架来解决小样本语义分割问题。 我们首先在1-shot设置中首先说明我们的模型而不失一般性。 我们的网络由两个模块组成:
- 密集比较模块(DCM) ,DCM在支持示例和查询示例之间执行密集特征比较
- 迭代优化模块(IOM),IOM执行预测结果的迭代细化
为了概括我们的网络从1-shot到k-shot学习,我们采用了一种注意机制来融合来自不同支持示例的信息。 此外,提出了一种新的测试设置,该设置使用带有边界框注释的支持图像进行few-shot分割,随后将对此进行描述。

5.1 Dense Comparison Module
双分支密集比较模块,它将查询图像中的每个位置与支持示例进行密集比较,如图2(b)所示。该模块由两个子模块组成:
- 提取表示的特征提取器
- 执行特征比较的比较模块。

特征提取器
特征提取器从CNN收集不同级别的表示以进行特征匹配。我们使用ResNet-50 作为特征提取器的主干。正如之前的few-shot分割工作所做的那样,骨干模型在Imagenet上进行了预训练。较低层中的特征通常涉及低级提示,例如边缘和颜色,而较高层中的特征涉及诸如对象类别的对象级概念。在少数几个场景中,我们的模型应该适应任何看不见的类。因此,我们不能假设在训练期间学习对应于看不见的类别的特征。相反,我们专注于可能构成由看不见的类共享的对象部分的中间级功能。 ResNet中的层基于空间分辨率被划分为4个块,其自然对应于4个不同的表示级别。我们选择block2和block3生成的特征进行特征比较,并在block3之后放弃图层。我们在块2之后的层中使用扩张卷积来维持特征映射的空间分辨率。在block2之后的所有特征映射具有输入图像的1/8的固定大小。块2和块3之后的特征被连接并通过3×3卷积编码为256维。支持分支和查询分支使用相同的特征提取器。我们在训练期间将ResNet中的权重保持固定。
密集的比较
由于支持图像中可能存在多个对象类别和杂乱背景,因此我们希望获取仅与目标类别对应的嵌入以进行比较。在这里,论文使用前景区域上的全局平均池来将特征映射压缩为特征向量。全局图像特征在分割任务中很有用,这可以通过全局平均合并来轻松实现。对前景区域的特征进行平均以过滤掉不相关的区域。在从支持集获得全局特征向量之后,我们将向量与查询分支生成的特征映射中的所有空间位置连接起来。此操作旨在将查询分支中的所有空间位置与来自支持分支的全局特征向量进行比较。然后,级联特征映射通过另一个卷积块与256个3×3卷积滤波器进行比较。
首先将二进制支持掩码双线性地下采样到特征映射的相同空间大小,然后将元素乘法与特征映射一起应用。 结果属于背景区域的特征变为零。 然后我们采用全局和池并将得到的矢量除以前景区域以获得平均特征向量。 我们将向量上采样到查询要素的相同空间大小,并将它们连接起来进行密集比较。
5.2 Iterative Optimization Module
由于在同一类别中存在外观差异,因此密集比较只能匹配对象的一部分,这可能不足以精确地分割图像中的整个对象。我们观察到初始预测是关于物体粗略位置的重要线索。我们提出了迭代优化模块来迭代地优化预测结果。结构如图2(c)所示。

模块的输入是密集比较模块生成的特征映射和上次迭代的预测掩码。直接连接具有预测掩模的特征图作为附加通道导致与特征分布不匹配,因为没有预测的第一前向通过的掩模。相反,我们建议将预测的掩模合并为残留形式:
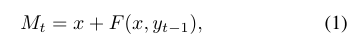
其中x是密集比较模块的输出特征; y_t-1是来自最后一次迭代步骤的预测掩模,并且M_t是残余块的输出。函数F(·)是特征x和预测掩模y_t-1的串联,接着是两个具有256个滤波器的3×3卷积块。然后我们添加两个具有相同数量的卷积滤波器的残余块。使用Deeplab V3 中提出的Atrous空间金字塔池模块(ASPP)来捕获多尺度信息。传送门!该模块由四个并行分支组成,包括三个3×3卷积,其中的空洞率为6,12,和18 分别和1×1卷积。
1×1卷积在图像级特征上操作,该特征通过全局平均合并来实现。然后将得到的矢量双线上采样到原始空间大小。来自4个分支的输出特征被连接并由另外的1×1卷积与256个滤波器融合。最后,我们使用1×1卷积生成最终的掩码,其中包括背景掩码和前景掩码。我们使用softmax函数来标准化每个位置的得分,从而输出前景和背景的置信度图。然后将置信图馈送到下一个IOM以进行优化。我们的最终结果是通过双线性地将置信度图上采样到查询图像的相同空间大小并根据置信度图对每个位置进行分类来实现。在训练时,为了避免迭代优化模块过度拟合预测的掩模,我们交替使用最后一个时期的预测掩模和空掩模作为IOM的输入。预测的掩模t-1被重置为空掩模,概率为pr 。这可以看作是整个掩模的丢失,是标准丢失的扩展。与先前的迭代细化方法相比,我们的方法将细化方案集成到具有剩余连接的模型中,以便整个模型可以运行以前馈的方式进行端到端的培训。
5.3 Attention Mechanism for k-shot Segmentation
为了有效地合并k-shot设置中的信息,我们使用注意机制来融合由不同支持示例生成的比较结果。 具体来说,我们在DCM中添加一个与密集比较卷积平行的注意模块(参见图3)。

注意分支由两个卷积块组成。
第一个有2563×3filters,接着是3×3maxpooling。
第二个有一个3×3卷积,然后是全局平均池。 从意图分支中得出的重量为λ。 然后,通过softmax函数对来自所有支持示例的权重进行归一化:
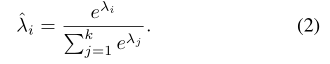
最终输出是不同支持样本生成的特征的加权和。
5.4 Bounding Box Annotations
由于我们的密集比较模块的本质是将查询图像中的每个位置与支持示例提供的全局表示进行密集比较,因此我们探索了一种使用边界框的支持集注释的新形式。 与逐像素注释相比,边界框注释使用矩形框来表示对象区域,该对象区域通常用于对象检测任务。 标记边界框注释比按像素标记便宜得多。 我们通过将整个边界框区域视为前景来放松支撑集。 我们在此设置下测试我们的模型以评估我们框架的功能。 两种测试设置的比较如图4所示。

6 Experiments
实验细节
| 项目 | 属性 |
| 数据集 | PASCAL VOC 2012 / COCO |
| 损失函数 | cross-entropy loss |
| 优化器 | SGD |
| 学习率 | 0.0025 |
| mini-batch | 4(Pacal) / 8(coco) |
| 实现工具 | pytorch |
评估指标
我们为分析实验选择了meanIoU评估指标,原因如下:
1)不同类别的测试样本数量不均衡(例如,49只类羊与378名类人)。忽略图像类别可能会导致对具有更多图像的类的偏向结果。此外,我们可以使用meanIoU评估指标观察我们的模型在不同类别中的有效性。
2)由于大多数对象相对于整个图像较小,即使模型无法分割任何对象,背景IoU仍然可能非常高,因此无法反映模型的能力。
3)前景IoU更常用于二进制分割文献(例如,视频分割和交互式分割)。
尽管如此,我们仍然将我们的结果与两项评估指标下的先前工作进





7 Conclusion
我们已经介绍了CANet,这是一种新颖的类不可知的分割网络,具有小样本学习能力。 密集比较模块利用CNN中的多个级别的特征来执行密集特征比较,并且迭代优化模块学习迭代地细化预测结果。 我们解决k-shot问题的注意机制比不可学习的方法更有效。 综合实验表明了我们框架的有效性,并且性能明显优于以前的所有工作。
