哪些是序列数据

2. 符号表示
例子:从一句话中识别出名字(named-entity recognization problem,搜索引擎中比如找出新闻人物、时间等应用),输出的0、1表示是否是名字
X是输入,x<t>表示输入的第t个值,y是输出,也有对应的位置。Tx表示输入的长度,Ty表述输出的长度。x(i)<t>表示第i个样本的第t个值

怎么表示输入
建立一个字典dictionary,一般30,000-50,000个,按序排列单词。如下,字典为10,000个词,对于输入,每个词用一个10000维的向量表示。如单词为a,a在字典第一个位置,则向量第一个值为1,其他为0,也称为one-shot

3. RNN模型
为什么不用标准的网络来处理这个问题(每个值分别作为网络的输入):
输入和输出的结果长度不一定相同; 结果不能很好地共享,比如第一个词学到peter为人名,当学到第三个位置也是peter时如果能获得第一个位置的结果也很有用

recurrent neural network模型
从左到右读取输入,把x<1>输入到网络的第一个隐藏层,然后识别出结果y hat,并输出激活值a<1>,当读取到x<2>时,它会利用输入的x<2>以及第一个time-step时间步的结果a<1>来预测结果
右侧的图一般在论文什么中会使用
waa表示:用来计算a,且需要乘以a
wax:用来计算a,后面需要乘以x
RNN的一个缺点:可能只利用前面的信息并不能得出正确的结果,比如第二句话,he said后,并不能很好地判断Teddy是否人名,所以有BRNN

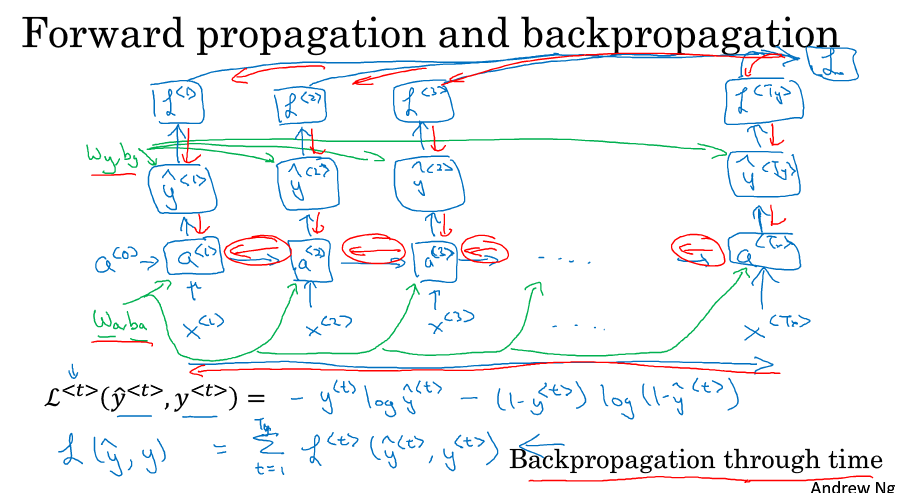
前向传播
一般用tanh激活函数,计算a和y使用的激活函数是不同的。只是一般不特意用不同的符号区分

简化符号表示:把向量堆叠

5. 反向传播

loss函数定义,反向传播backpropagation through time红色的部分
5. RNN不同结构类型
one-to-one:基本的结构
many-to-many:长度相同的
many-to-many:长度不同的,先读入所有输入,然后输出,如机器翻译
one-to-many:序列生成,如输入一个音符,然后输出一串音乐,把中间时间步的输出作为下一步的输入
many-to-one:情感分析,根据一句话来分析他的情感分类,比如好、不好等。所有输入后,最后输出一个结果来判断等级

6. 语言模型
什么是语言模型:判断出输入是某一句话的概率,这里的概率计算为什么用P(y<1>..),而不是用P(x<1>。。)?后面会说

数据的表示:训练集:corpus of english text
建立一个字典,把单词符号化,每个单词为y<t>,对于未知的用UNK表示,结束用EOS表示

第一个输入x<1>为空,输出为P(a), P(ab)...,也就是字典中任一单词为首个单词的概率,用softmax
第二个输入x<2>=y<1>:当正确的首个单词为cats时,第二个单词是任一个的概率,这里用了条件概率P(average|cats)
最后,P(y<1>, y<2>,y<3>) 是各个输出的乘积。所以前面为什么不用x?用y的话会表示前面的输出吧,x只能表示输入?
这里也定义了Loss函数

7. 对新序列进行采样
看看RNN学出了什么,对训练的结果进行采样
采样:对y hat输出根据概率分布随机采样得到一个结果,把采样的结果作为下个的输入。如何判断结束:EOS或规定步数

基于字符的语言模型
每个单词都是识别成字符,上面是基于词汇的语言模型
字符的缺点:数据大,单词间的联系不好

8. 梯度消失问题
比如上面的句子,cat和后面的单复数was是有影响的,如果网络层数很多,就很难影响到
还有梯度消失问题,比较难解决
梯度爆炸问题,可以用梯度剪枝来解决,当判断梯度到一定阈值时就进行调整

8. GRU gated recurrent unit
一个RNN单元

简化的GRU
c 表示memory cell,是记忆细胞,比如记住cat是单/复数
C~<t>是用来更新c<t>人候选值
下面一个是用来更新的门,u表示更新
在下是更新的计算公式
因为tanh有两个部分取值趋近于-1/1,所以不容易出现梯度消失的问题

完整的GRU:
增加一个参数r,来表示c~<t>和c<t-1>之间的关系读

9. LSTM long short term memory
与GRU相比,它有3个门,更加复杂,现在一般做为默认的选择。GRU更简单,更容易建立复杂的网络,速度更快

peephole connection:除了a和x,上一个c<t-1>也会对门值产生影响
这里不再像GRU,c和a不再相等

10. BRNN bidirection RNN双向RNN
例:要判断Teddy是否为人名,不仅要前面的信息,也需要后面的信息

标准的BRNN结构
有从左向右的计算,也有从右向左的计算,构成一个Acyclic graph无环图,最后y hat结果是通过两个方向的激活值来得到
中间的单元可以是标准的RNN,也可以是GRU/LSTM单元
一般NLP问题会使用LSTM单元的BRNN结构
BRNN需要一个完整的句子,如果用于语音识别,就需要等一个人把话都说完才可以。所以这个标准的结构更适合于NLP问题

10. 深层循环神经网络
在原来的时间序列上叠加几层,一般层数不会太多,但是一个时间步中可以有多层,只是水平方向不链接
