目录
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~
0. 前言
循环神经网络 RNN(Recurrent Neural Network)是一类专门用于处理序列数据的神经网络。
标准的神经网络无法适应不同长度的输入和输出, 没有共享参数,无法泛化文本不同位置的同个词。
RNN 在几个时间步内共享参数,使得模型可以扩展到不同长度的序列样本进行泛化,不需要分别学习句子每个位置的规则。
RNN 减少参数付出的代价是优化参数困难。
用一个识别是否是人名的例子,初始定义符号如下:
- 输入
:“Harry Potter and Hermione Granger invented a new spell.”
- 输出
:“110110000”
表示
个输入,例如
表示 Harry
表示
表示 1
表示
表示
- 当
时,
也表示序列长度
对于自然语言处理(Natural Language Processing),构建一个词汇表,对于一个输入
1. RNN 计算图
对于一个输入
每次计算不仅输入 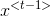
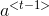
如下图所示(图源:吴恩达深度学习):

2. RNN 前向传播
在 RNN 中,隐藏单元激活函数多采用 tanh 。
初始 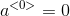
按照深度学习花书中的符号表示(

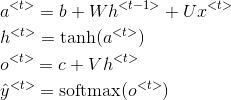
按照吴恩达深度学习的符号表示(
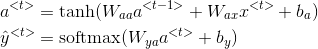
对上式子进行修改可简化参数:
![\begin{align*} & a^{<t>}=\textup{tanh}(W_a[a^{<t-1>}; x^{<t>}]+b_a)\\ & \hat{y}^{<t>}=\textup{softmax}(W_ya^{<t>}+b_y)\\ \end{align*}](https://img-blog.csdnimg.cn/20181225122443698)
其中,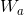
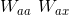
![[a^{<t-1>}; x^{<t>}]](https://img-blog.csdnimg.cn/20181222215907563)
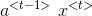
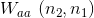
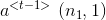
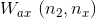
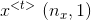
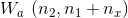
![[a^{<t-1>}; x^{<t>}]\ (n_1+n_x,1)](https://img-blog.csdnimg.cn/20181221194718901)
前向传播的运行时间是 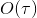
前向传播中各个状态必须保存,直到它们反向传播中再次被使用,因此内存代价也是
3. RNN 反向传播
反向传播不仅仅通过每个单词的输出路径,而且还通过每个激活函数的传递路径。
RNN 反向传播通常也称为穿越时间的反向传播 BPTT(back propagation through time)。
代价函数根据输出的情况,可以采用 logistic regression loss 或者最大对数似然。
总的代价函数为各时间
这里使用深度学习花书上的符号表示反向传播:
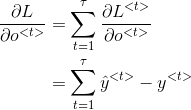
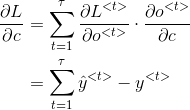
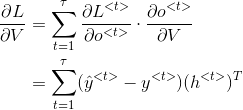
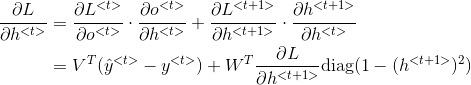
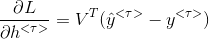
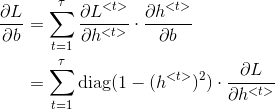
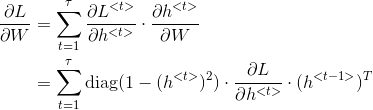
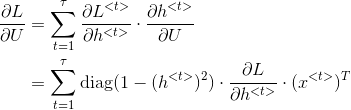
4. 导师驱动过程(teacher forcing)
由上一个
训练时,无论输出 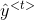
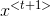
如下图所示(图源:吴恩达深度学习):

采样时(即模型部署后),真正的输出通常是未知的,我们用模型输出近似正确的输出。
每一次输入不是
如下图所示(图源:吴恩达深度学习):

满足 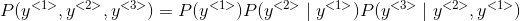
如果模型仍存在外界的输入,则可将正确的输出
如下图所示(图源:深度学习):

5. 不同序列长度的 RNN
根据输入序列和输出序列的长度,可以分为如下几种:
one to one,即 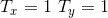

one to many,即 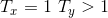

还有一种设计模式,是将

这类 RNN 适用于很多任务,例如单个图像作为模型的输入,产生描述图像的词序列。
many to one,即 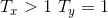

many to many(相等),即 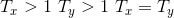

还有一种设计模式,是由输出反馈至下一个隐藏单元,而不是隐藏单元至隐藏单元(图源:深度学习):

这种 RNN 并没有那么强大,输出
many to many(不相等),即 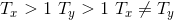

将输入序列映射到不一定等长的输出序列,如语音识别、机器翻译等。
编码器(encoder)RNN 处理输入序列,输出上下文 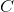
解码器(decoder)RNN 以固定长度的向量为条件产生输出序列。
此架构的一个明显不足是
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~