版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zhq9695/article/details/85193649
目录
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~
0. 前言
标准的 RNN 每次的输出,都与附近的几次输入、隐藏单元激活函数值相关。
而与很久之前的输入关联性较差,会遗忘较早的信息,缺乏长期依赖。
本篇介绍为解决这个问题而修改的 RNN 模型。
- 长短期记忆 LSTM(Long Short-Term Memory)
- 门控循环单元 GRU(Gated Recurrent Unit)
1. 长短期记忆 LSTM
LSTM (Long Short-Term Memory)使得自循环的权重视上下文而定,而不是固定的。
参数 
LSTM 定义如下:
![\begin{align*} &\tilde{c}^{<t>}=\textup{tanh}(W_c[a^{<t-1>};x^{<t>}]+b_c)\\ &\Gamma_u=\sigma(W_u[a^{<t-1>};x^{<t>}]+b_u)\\ &\Gamma_f=\sigma(W_f[a^{<t-1>};x^{<t>}]+b_f)\\ &\Gamma_o=\sigma(W_o[a^{<t-1>};x^{<t>}]+b_o)\\ &c^{<t>}=\Gamma_u * \tilde{c}^{<t>}+\Gamma_f*c^{<t-1>}\\ &a^{<t>}=\Gamma_o * \textup{tanh}\ c^{<t>}\\ \end{align*}](https://img-blog.csdnimg.cn/20181222085416138)
其中,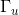
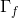

LSTM 比简单的循环架构更易于学习长期依赖。
2. 门控循环单元 GRU
GRU(Gated Recurrent Unit)和 LSTM 的主要区别是 GRU 通过单个门控同时控制更新操作和遗忘操作。
GRU 定义如下:
![\begin{align*} &\tilde{c}^{<t>}=\textup{tanh}(W_c[\Gamma_r * c^{<t-1>};x^{<t>}]+b_c)\\ &\Gamma_u=\sigma(W_u[c^{<t-1>};x^{<t>}]+b_u)\\ &\Gamma_r=\sigma(W_r[c^{<t-1>};x^{<t>}]+b_r)\\ &c^{<t>}=\Gamma_u * \tilde{c}^{<t>}+(1-\Gamma_u)*c^{<t-1>}\\ &a^{<t>}=c^{<t>}\\ \end{align*}](https://img-blog.csdnimg.cn/20181222085416396)
其中,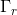
简单版本的 GRU 可以通过去掉复位门
GRU 的优点是模型比 LSTM 简单,可以训练更大的网络,只有两个门控,可以更快的训练。
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~