这个单子不太难用的还是学弟的爬虫,但是有个地方就是地图可视化,库太难装了,还是靠杨晨帮我,没有他这个单子就黄了,大佬就是大佬,一定要注意版本匹配问题
模块1:数据抓取
#我们使用了 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) 这条语句,伪装成了火狐浏览器
#使用time.sleep(1) 这条语句,将程序暂停1s,降低对网站的访问频率
import requests
from lxml import etree
import re
import xlwt
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Host': 'lz.ganji.com/'
}
# 创建excel表格
f = xlwt.Workbook(encoding='utf_8')
sheet01 = f.add_sheet(u'sheet1', cell_overwrite_ok=True)
sheet01.write(0, 0, '名称')
sheet01.write(0, 1, '厅室')
sheet01.write(0, 2, '面积')
sheet01.write(0, 3, '朝向')
sheet01.write(0, 4, '楼层')
sheet01.write(0, 5, '小区')
sheet01.write(0, 6, '联系人')
sheet01.write(0, 7, '价格')
sheet01.write(0, 8, '单价')
num = 1
for x in range(1, 5):
url = 'http://sh.ganji.com/chongming/ershoufang//pn%d/' % x
response = requests.get(url, headers)
result = response.text
html = etree.HTML(result, etree.HTMLParser())
# 获取所有二手房的div标签
divs = html.xpath("//div[@class='f-list js-tips-list']/div[contains(@class,'ershoufang-list')]")
# 遍历每个标签,拿到需要的数据
for div in divs:
title = div.xpath(".//dd[contains(@class,'title')]/a/@title")[0]
print(title)
# info = div.xpath(".//dd[contains(@class,'size')]")
# rooms = info[1]
# area = info[4]
# orientation = info[7]
# floor = info[10]
rooms = div.xpath(".//dd[contains(@class,'size')]//span[1]/text()")[0]
area = div.xpath(".//dd[contains(@class,'size')]//span[3]/text()")[0]
orientation = div.xpath(".//dd[contains(@class,'size')]//span[5]/text()")[0]
floor = div.xpath(".//dd[contains(@class,'size')]//span[7]/text()")[0]
address = "".join(div.xpath(".//a[contains(@class,'address-eara')]//text()"))
address = re.sub("\s", "", address)
host = "".join(div.xpath(".//dd[contains(@class,'address')][2]//text()"))
host = re.sub("\s", "", host)
price = "".join(div.xpath(".//dd[contains(@class,'info')]/div[@class='price']/span/text()"))
unit_price = div.xpath(".//dd[contains(@class,'info')]/div[@class='time']/text()")[0]
#数据保存
sheet01.write(num, 0, title)
sheet01.write(num, 1, rooms)
sheet01.write(num, 2, area)
sheet01.write(num, 3, orientation)
sheet01.write(num, 4, floor)
sheet01.write(num, 5, address)
sheet01.write(num, 6, host)
sheet01.write(num, 7, price)
sheet01.write(num, 8, unit_price)
num = num + 1
time.sleep(1) # 设置延时
f.save("崇明" + '.xls')度假,养老好房来啦送90平大花园50平菜地价格还
城桥南门首付8万可买的豪装两房房东搬迁急售外地人
崇明融创中式合院 南北双院落 轨交19号线赠送地
叠加,联排,独栋别墅 带花园 带露台 带车库 送
火暴降30万跪求出售上海70年产权住宅房外地人可
长兴岛19号线地铁口50米o首付可买外地人可落户
壹街区50平电梯房 楼层好 户型正气
首付10万即可入住(单身可买,无需社保)地铁口旁
装修好的,带阁楼,拎包即住 家电家具全送
!!稀,缺合院别墅!!送150平大花园!!送车位
崇明岛新海二村 房东置换买上海房子 现降价出售
外地人可买,首付10万,精装两房送车位,带家具家
崇明生态岛精装修一房家具家电齐全可随时看房65
外地人可买(2房只卖1房价格送88平米菜地)送产
外地人 无需社保可买 一年前的精装修 看中价格可
崇明岛当地中介10年老店!新海镇两室一厅 精装修
19号线已经动工(首付仅8万)花博会的主办地 未
(原价95万降到45万)来电立减5万送豪装车位无
上海产证可落户 均价不到1W就可在上海买房 精装
!!崇明低总价别墅!!送200平花园!!送4车位
崇明岛上海产权房 真实实拍!!现仅需42W就可在
售价39万!!崇明岛新海镇上海产权房 有直达上海
(拒绝假房源!!)真保房源 东风农场近东平森林公
本周必卖!房东降价3万 置换上海房子 底楼带15
84精装修住宅满五无税家具家电齐全可随时看房
崇明岛本地中介 本周必卖!! 底楼带大天井 小房
崇明生态岛丨外地人可买精装修两房丨上海70年产权
本地中介!!崇明岛二手房3楼精装修 58平米3室
崇明岛二手房热门小区!本地中介 底楼精装修 附赠
地铁300米~急卖300万~临河别墅~独门独院~
崇明岛二手房 底楼精装修带15平米大天井 适合养
!急卖价格可谈!精装修拎包入住!可落户上学方便!
急急急售 (只需30万 只卖3天)送20平阳台不
崇明岛本地中介推荐 养老好房源 底楼精装修 家具
外地人可买难以想象的便宜 (地铁0距离)首付10
(房东连夜降价50万 还送40万精装修)地铁口1
崇明岛东平镇中心房源 2021年花博会的主办地
崇明岛地铁19号线已经动工!!上海产权房 底楼精
有赠送面积 赠送家具家电 可落户上学 无需税费
拒绝假房源!崇明岛上海产权房,小户型住宅房 售价
外地人可买丨送20平储藏室丨精装修两房70年产权
急急急丨房东急售50万一口价丨外地人可买丨精装修
本地中介新推出花博会旁双南双天井的好房子!
本地中介新推出跃进新村双南的两房!
三湘森林海尚,大花园连排边套,中心景观位置,无遮
本地中介!!崇明岛热门小区!周边配套设施齐全 交
一梯两户双南全明的两房只有33万哦!
崇明岛热门小区 新苑新村位于新海镇中心 2楼精装
走过几个农场以后你会觉得还是这里好,长江农场场部
崇明本地中介 真实实拍 实地能看到实房 底楼精装
总价100万以内买上海产权大三房(送50万精装修
本地中介!!真实实拍 均价不到1W就可在上海买房
(夫妻分割财产降价40万)精装修两房 通地铁可迁
崇明岛上海产权落户口 精装修小户型 过渡期与养老
崇明东风农场靠近东平国家森林公园!一梯两户!房龄
(年租金9万写入合同)送硬装12万,找不到第二套
无社保可落户(送精装修41万送88平米大菜地)送
外地人可买上海住宅,房东挥泪降4万,精装修全送,
先后爬取浦东、闵行、松江、宝山、嘉定、徐汇、青浦、静安、普陀、杨浦、奉贤、黄浦、虹口、金山、崇明等其他15个区,保存在原始文件中
#我们使用了 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) 这条语句,伪装成了火狐浏览器
#使用time.sleep(1) 这条语句,将程序暂停1s,降低对网站的访问频率
import requests
from lxml import etree
import re
import xlwt
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Host': 'lz.ganji.com/'
}
# 创建excel表格
f = xlwt.Workbook(encoding='utf_8')
sheet01 = f.add_sheet(u'sheet1', cell_overwrite_ok=True)
sheet01.write(0, 0, '名称')
sheet01.write(0, 1, '厅室')
sheet01.write(0, 2, '面积')
sheet01.write(0, 3, '朝向')
sheet01.write(0, 4, '楼层')
sheet01.write(0, 5, '小区')
sheet01.write(0, 6, '联系人')
sheet01.write(0, 7, '价格')
sheet01.write(0, 8, '单价')
num = 1
for x in range(1, 5):
url = 'http://sh.ganji.com/jinshan/ershoufang//pn%d/' % x
response = requests.get(url, headers)
result = response.text
html = etree.HTML(result, etree.HTMLParser())
# 获取所有二手房的div标签
divs = html.xpath("//div[@class='f-list js-tips-list']/div[contains(@class,'ershoufang-list')]")
# 遍历每个标签,拿到需要的数据
for div in divs:
title = div.xpath(".//dd[contains(@class,'title')]/a/@title")[0]
print(title)
# info = div.xpath(".//dd[contains(@class,'size')]")
# rooms = info[1]
# area = info[4]
# orientation = info[7]
# floor = info[10]
rooms = div.xpath(".//dd[contains(@class,'size')]//span[1]/text()")[0]
area = div.xpath(".//dd[contains(@class,'size')]//span[3]/text()")[0]
orientation = div.xpath(".//dd[contains(@class,'size')]//span[5]/text()")[0]
floor = div.xpath(".//dd[contains(@class,'size')]//span[7]/text()")[0]
address = "".join(div.xpath(".//a[contains(@class,'address-eara')]//text()"))
address = re.sub("\s", "", address)
host = "".join(div.xpath(".//dd[contains(@class,'address')][2]//text()"))
host = re.sub("\s", "", host)
price = "".join(div.xpath(".//dd[contains(@class,'info')]/div[@class='price']/span/text()"))
unit_price = div.xpath(".//dd[contains(@class,'info')]/div[@class='time']/text()")[0]
#数据保存
sheet01.write(num, 0, title)
sheet01.write(num, 1, rooms)
sheet01.write(num, 2, area)
sheet01.write(num, 3, orientation)
sheet01.write(num, 4, floor)
sheet01.write(num, 5, address)
sheet01.write(num, 6, host)
sheet01.write(num, 7, price)
sheet01.write(num, 8, unit_price)
num = num + 1
time.sleep(1) # 设置延时
f.save("金山" + '.xls')模块2:数据处理
!pip install wordcloudimport matplotlib.pyplot as plt
import pandas as pd
import re
import codecs
import pickle
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
import jieba
%matplotlib inline
import seaborn as sns#浦东、闵行、松江、宝山、嘉定、徐汇、青浦、静安、普陀、杨浦、奉贤、黄浦、虹口、长宁、金山、崇明
test_1=pd.read_excel('原始数据/浦东.xls')
test_2=pd.read_excel('原始数据/闵行.xls')
test_3=pd.read_excel('原始数据/松江.xls')
test_4=pd.read_excel('原始数据/宝山.xls')
test_5=pd.read_excel('原始数据/嘉定.xls')
test_6=pd.read_excel('原始数据/徐汇.xls')
test_7=pd.read_excel('原始数据/青浦.xls')
test_8=pd.read_excel('原始数据/静安.xls')
test_9=pd.read_excel('原始数据/普陀.xls')
test_10=pd.read_excel('原始数据/杨浦.xls')
test_11=pd.read_excel('原始数据/奉贤.xls')
test_12=pd.read_excel('原始数据/黄浦.xls')
test_13=pd.read_excel('原始数据/虹口.xls')
test_14=pd.read_excel('原始数据/长宁.xls')
test_15=pd.read_excel('原始数据/金山.xls')
test_16=pd.read_excel('原始数据/崇明.xls')test_all=pd.concat([test_1,test_2,test_3,test_4,test_5,test_6,test_7,test_8,test_9,test_10,test_11,test_12,test_13,test_14,test_15,test_16])test_all.head()test_all['面积']=test_all['面积'].str.split('㎡').str[0]
test_all['楼层']=test_all['楼层'].str.split('(').str[0]
test_all['价格']=test_all['价格'].str.split('万').str[0]
test_all['单价']=test_all['单价'].str.split('元').str[0]
test_all['面积']=test_all['面积'].astype('float')
test_all['价格']=test_all['价格'].astype('float')
test_all['单价']=test_all['单价'].astype('float')缺省值
#名称 由于名称太过复杂,就先不进行处理
#厅室,朝向,楼层,是离散变量
#面积去掉单位
train_missing = (test_all.isnull().sum()/len(test_all))*100
train_missing = train_missing.drop(train_missing[train_missing==0].index).sort_values(ascending=False)
miss_data = pd.DataFrame({'缺失百分比':train_missing})
miss_data| 缺失百分比 |
|---|
异常值
test_all['楼层'].unique()array(['中层', '低层', '高层', '共1层', '共4层', '共5层', '共3层', '共2层', '地下'],
dtype=object)
flor={
"共1层":'低层',"共4层":'中层',"共3层":'中层','共5层':'中层','共2层':'低层','中层':'中层','低层':'低层','高层':'高层','地下':'地下'
}
test_all['楼层']=test_all['楼层'].map(flor)test_all.head()| 名称 | 厅室 | 面积 | 朝向 | 楼层 | 小区 | 联系人 | 价格 | 单价 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 16号线地铁旁。临港自贸区,学,区房 | 3室2厅2卫 | 96.0 | 南 | 中层 | 浦东 | 中原地产-周保友 | 245.0 | 25520.0 |
| 1 | 70年产权,外地可买,近16号线地铁,南北户型, | 2室2厅2卫 | 78.0 | 南北 | 低层 | 浦东 | 中原地产-刘林娟 | 75.0 | 9615.0 |
| 2 | 金沁苑丨小区第二排丨电梯12楼丨25万精装丨不靠 | 3室2厅1卫 | 97.4 | 南 | 高层 | 浦东 | 齐星地产-落丁瑞 | 280.0 | 28747.0 |
| 3 | 临港滴水湖地铁1公里!现房叠加别墅(可公积金贷款 | 4室2厅2卫 | 117.0 | 南北 | 低层 | 浦东 | 上海锦镓房地产经纪事务所-饶帅 | 288.0 | 24615.0 |
| 4 | 外地人可买挑高5米通燃气地铁口800米首付10万 | 2室2厅1卫 | 45.0 | 南北 | 中层 | 浦东 | 中原地产-陈治刚 | 70.0 | 15555.0 |
名称
# test_all['名称'].to_csv('名称.txt', sep='\t', index=False)
# fin = codecs.open('名称.txt',mode = 'r', encoding = 'utf-8')
# print (fin.read())
# #第一次运行程序时将分好的词存入文件
# text = ''
# with open('名称.txt',encoding = 'utf-8') as fin:
# for line in fin.readlines():
# line = line.strip('\n')
# text += ' '.join(jieba.cut(line))
# text += ' '
# fout = open('text.txt','wb')
# pickle.dump(text,fout)
# fout.close()fr = open('text.txt','rb')
text = pickle.load(fr)
#print(text)
backgroud_Image = plt.imread('house1.jpg')
wc = WordCloud( background_color = 'white', # 设置背景颜色
mask = backgroud_Image, # 设置背景图片
max_words = 200, # 设置最大现实的字数
stopwords = STOPWORDS, # 设置停用词
font_path = 'simfang.ttf',# 设置字体格式,如不设置显示不了中文
max_font_size = 200, # 设置字体最大值
random_state = 8, # 设置有多少种随机生成状态,即有多少种配色方案
)
wc.generate(text)
image_colors = ImageColorGenerator(backgroud_Image)
wc.recolor(color_func = image_colors)
plt.figure(figsize=(80,40))
plt.imshow(wc)
plt.axis('off')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-45Bh7D9t-1574604502716)(output_19_0.png)]
厅室
housetype = test_all['厅室'].value_counts()from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#设置画布
asd,sdf = plt.subplots(1,1,dpi=100)
#获取排前10条类型
housetype.head(10).plot(kind='bar',x='housetype',y='size',title='户型数量分布',ax=sdf)
plt.legend(['数量'])
plt.show()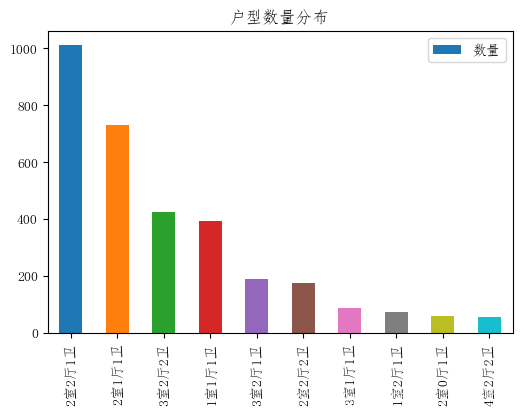
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C0MBzv7x-1574604502718)(output_22_0.png)]
面积
plt.clf()
fig,axs=plt.subplots(1,2,figsize=(14,4))
axs[0].scatter(x=test_all.loc[:,'面积'],y=test_all.loc[:,'价格'])
axs[1].scatter(x=test_all[test_all.loc[:,'面积']<400].loc[:,'面积'],y=test_all[test_all.loc[:,'面积']<400].loc[:,'价格'])
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kicDAqVo-1574604502719)(output_24_1.png)]
朝向
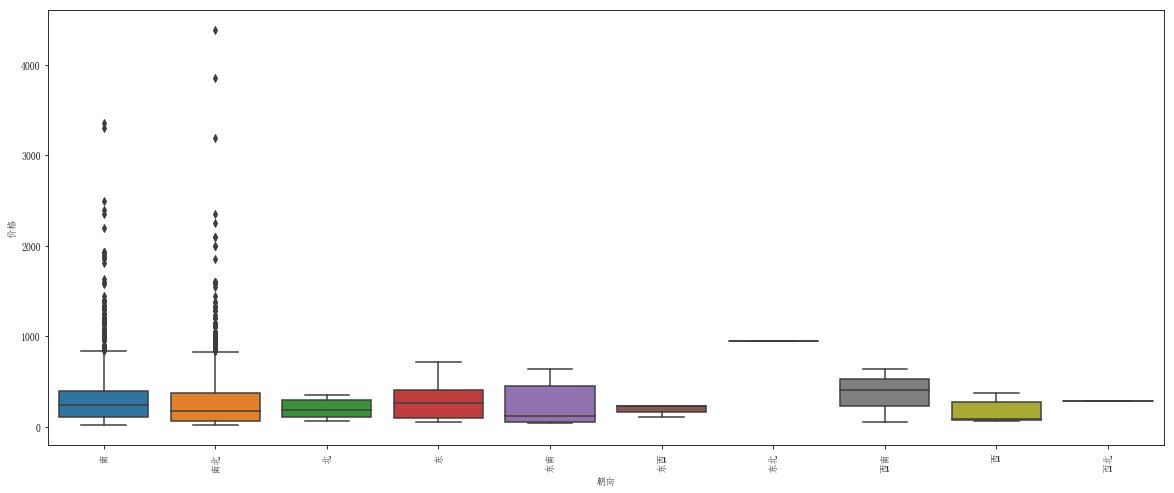
print(test_all.loc[:,['朝向','价格']].groupby(['朝向']).agg(['mean','std']).sort_values(by=('价格','mean'),ascending=False).head(10))
plt.clf()
plt.figure(figsize=(20,8))
sns.boxplot(x='朝向',y='价格',data=test_all)
plt.xticks(rotation='90')
plt.show() 价格
mean std
朝向
东北 950.000000 NaN
西南 370.000000 297.026935
南 316.668045 314.883343
东 293.118750 226.812284
西北 283.000000 NaN
南北 275.903380 326.926596
东南 232.563846 232.682809
北 193.944444 107.077788
东西 189.666667 69.859383
西 172.454545 124.390806
<Figure size 432x288 with 0 Axes>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bpmuej27-1574604502719)(output_26_2.png)]
楼层
print(test_all.loc[:,['楼层','价格']].groupby(['楼层']).agg(['mean','std']).sort_values(by=('价格','mean'),ascending=False).head(10))
plt.clf()
plt.figure(figsize=(20,8))
sns.boxplot(x='楼层',y='价格',data=test_all)
plt.xticks(rotation='90')
plt.show() 价格
mean std
楼层
地下 421.000000 22.627417
高层 387.022996 369.748033
低层 318.662349 280.024954
中层 249.461442 303.147513
<Figure size 432x288 with 0 Axes>

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TSBcmIrX-1574604502719)(output_28_2.png)]
小区
test_all['单价']=test_all['单价'].astype('float')from pyecharts import options as opts
from pyecharts.charts import Map, Page
from pyecharts.faker import Collector, Faker
m = Map()
m.add("Show", [list(z) for z in zip(
["松江区","浦东区","宝山区","嘉定区","闵行区","青浦区","金山区","徐汇区","普陀区","虹口区","崇明区","静安区","杨浦区","奉贤区","黄浦区","长宁区"],[21530,36338,31733,26651,38861,23836,15195,63344,46531,56534,12597,54703,55846,18312,66790,48981])], "上海")
m.set_global_opts(title_opts=opts.TitleOpts(title="Map-上海地图"),visualmap_opts=opts.VisualMapOpts())
m.render_notebook()
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-38-f324f2791869> in <module>()
----> 1 from pyecharts import options as opts
2 from pyecharts.charts import Map, Page
3 from pyecharts.faker import Collector, Faker
4 m = Map()
5 m.add("Show", [list(z) for z in zip(
ModuleNotFoundError: No module named 'pyecharts'
单价
#上海各区域二手房平均单价
groups_unitprice_area = test_all['单价'].groupby(test_all['小区'])
mean_unitprice=groups_unitprice_area.mean()fig = plt.figure(figsize=(12,7))
ax = fig.add_subplot(111)
ax.set_ylabel("单价(元/平米)",fontsize=14)
ax.set_title("上海各区域二手房平均单价",fontsize=18)
mean_unitprice.plot(kind="bar",fontsize=12)
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xmv2yc2s-1574604502720)(output_34_0.png)]
#上海各区域二手房平均单价
count_region = test_all['单价'].groupby(test_all['小区']).count()data={
'单价':mean_unitprice,
'数量':count_region
}merge=pd.DataFrame(data)merge.colmnus=['单价','数量']D:\anaconda\lib\site-packages\ipykernel_launcher.py:1: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access
"""Entry point for launching an IPython kernel.
merge['单价']小区
嘉定 26651.748000
奉贤 18312.919355
宝山 31733.589147
崇明 12597.977376
徐汇 63344.400000
普陀 46531.785408
杨浦 55846.924528
松江 21530.938628
浦东 36338.821818
虹口 56534.632035
金山 15195.854772
长宁 48981.969231
闵行 38861.384000
青浦 23836.793388
静安 54703.986364
黄浦 66790.753247
Name: 单价, dtype: float64
fig, ax = plt.subplots()
ax.plot(merge['单价'],label='单价')
ax.plot(merge['数量'], label='数量')
ax.set(ylabel='Temperature (deg C)', xlabel='Time', title='A tale of two cities')
ax.legend()
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TfjErukH-1574604502720)(output_40_0.png)]
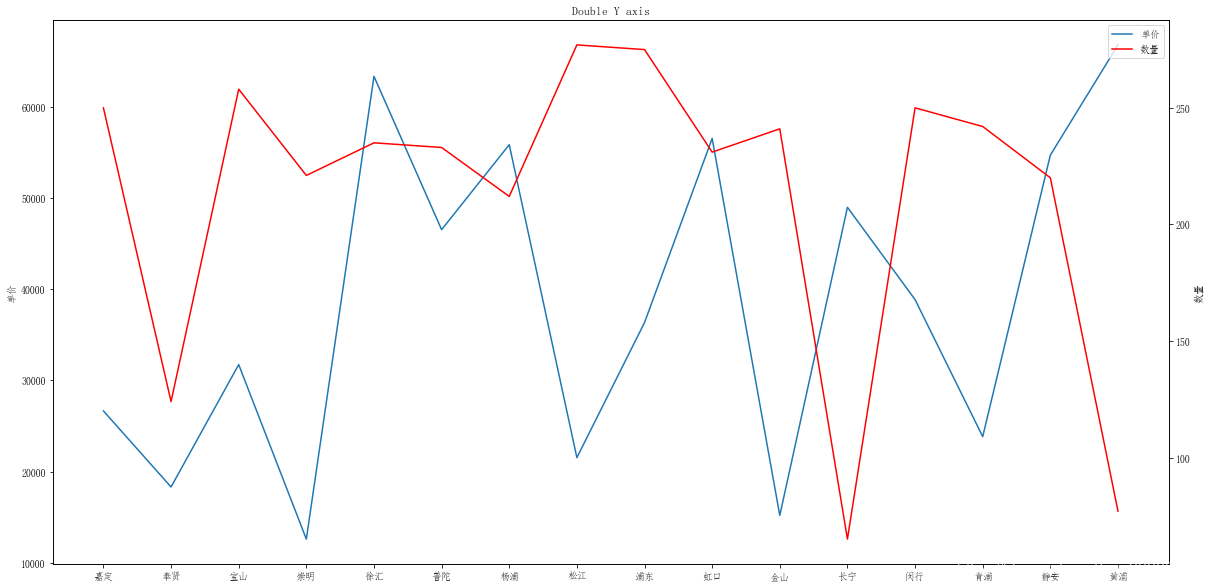
fig = plt.figure(figsize=(20,10))
ax1 = fig.add_subplot(111)
ax1.plot(merge['单价'],label=u"单价")
ax1.set_ylabel('单价')
ax1.set_title("Double Y axis")
ax2 = ax1.twinx() # this is the important function
ax2.plot(merge['数量'],'r',label=u"数量")
ax2.set_ylabel('数量')
handles1, labels1 = ax1.get_legend_handles_labels()
handles2, labels2 = ax2.get_legend_handles_labels()
plt.legend(handles1+handles2, labels1+labels2, loc='upper right')<matplotlib.legend.Legend at 0x1910f6ddb70>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fzmS24oC-1574604502721)(output_41_1.png)]
fig, ax = plt.subplots()
ax.plot(, [10, 20, 25, 30], label='Philadelphia')
ax.plot([1, 2, 3, 4], [30, 23, 13, 4], label='Boston')
ax.scatter([1, 2, 3, 4], [20, 10, 30, 15], label='Point')
ax.set(ylabel='Temperature (deg C)', xlabel='Time', title='A tale of two cities')
ax.legend()
plt.show() File "<ipython-input-48-8a0b8f078298>", line 2
ax.plot(, [10, 20, 25, 30], label='Philadelphia')
^
SyntaxError: invalid syntax
import jieba.posseg as psg
# 请在这里输入你的代码
# 1-6行提取全部的中文词汇
fr = open('text.txt','rb')
text = pickle.load(fr)
# 建立两个空的List,用来储存名词性单词以及动词性单词
NwordList, VwordList = [], []
# 此处的psg为,jieba库的posseg方法,用来进行分词,返回两个对象x.flag为词性,x.word为单词本身
for x in psg.cut(text):
# 筛选名词性单词
if str(x.flag).split()[0] == 'n':
NwordList.append(x.word)
# 筛选动词性单词
elif str(x.flag).split()[0] == 'v':
VwordList.append(x.word)
# 此处运行需要花一点时间,请耐心等待
print('筛选出名词:', len(NwordList))
print('筛选出动词:', len(VwordList))# from collections import Counter
# # 名词词云
# keys, values = Counter(NwordList).keys(), Counter(NwordList).values()
# wordcloud = WordCloud('名词词性词云',width=900,height=620)
# wordcloud.add("二手房信息词汇词频----名词",list(keys),list(values),word_size_range=[10, 100])
# wordcloud# # 动词词云
# # 动词词云
# # 去除{是 位于 到 有}这些实际含义不明确的词汇
# VwordList = [item for item in VwordList if item not in ['是', '位于', '到', '有']]
# keys, values = Counter(VwordList).keys(), Counter(VwordList).values()
# wordcloud = WordCloud('动词词性词云', width=900, height=620)
# wordcloud.add("二手房信息词汇词频----动词", list(keys), list(values), word_size_range=[20, 100])
# wordcloud# 请从这里输入代码
import numpy as np
region_sh = list(set(test_all['小区']))
region_sh
city_value = []
for city in region_sh:
mean_price = np.mean(test_all[test_all['小区']== city]['单价'])
if mean_price >= 0:
city_value.append((city, mean_price))
city_value[('青浦', 23836.793388429753),
('杨浦', 55846.92452830189),
('松江', 21530.938628158845),
('金山', 15195.854771784232),
('虹口', 56534.632034632035),
('宝山', 31733.58914728682),
('黄浦', 66790.75324675324),
('嘉定', 26651.748),
('奉贤', 18312.91935483871),
('静安', 54703.986363636366),
('崇明', 12597.977375565612),
('长宁', 48981.96923076923),
('闵行', 38861.384),
('普陀', 46531.78540772532),
('徐汇', 63344.4),
('浦东', 36338.821818181816)]
# # 请在这里输入你的代码
# # 创建Pyecharts Geo 地理坐标对象
# import pickle
# from pyecharts.charts import Geo
# geo = Geo(
# "上海各区平均房价渲染图", # title
# title_color="#fff", # 标题颜色
# title_pos="center", # 标题位置
# width=960, # 图片宽度
# height=600, # 图片长度
# background_color="#404a59", # 背景颜色
# )
# condition = True
# while condition:
# try:
# attr, value = geo.cast(city_value) # 解析数据组
# geo.add(
# "",
# attr,
# value,
# # type="heatmap", # 图片的样式,这里渲染的这张图为数据点图,也可以选择热力图
# visual_range=[min(value), max(value)*0.2], # 点的颜色代表销量数值,此参数规定了颜色数值范围
# visual_text_color="#fff",
# symbol_size=15, # 数据点的大小
# is_visualmap=True, # 是否显示调节数据点的bar
# )
# condition = False
# except Exception as e:
# city = str(e).split('for ')[-1]
# for item in city_value:
# if item[0] == city:
# city_value.remove(item)
# print('\r 未找到城市 %s ,删除此城市,重新渲染' % city, end='')
# geo # 最终渲染图片
test_all.head()
test_ana2=test_all[test_all['小区']=='奉贤']
test_ana2.head()| 名称 | 厅室 | 面积 | 朝向 | 楼层 | 小区 | 联系人 | 价格 | 单价 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 临港自贸区192万74平只此一套,精装修,S3出 | 2室1厅1卫 | 74.0 | 北 | 中层 | 奉贤 | 上海锦镓房地产经纪事务所-易杨成 | 192.0 | 25945.0 |
| 1 | 急售首付30万不限购地铁5号线现房拎包入住送车位 | 2室2厅1卫 | 70.0 | 南北 | 中层 | 奉贤 | 中原地产-冯明发 | 160.0 | 22857.0 |
| 2 | 奉贤品质小高层,自带20万方商业体,现房精装交付 | 2室2厅1卫 | 70.0 | 南 | 中层 | 奉贤 | 中原地产-李芹芹 | 160.0 | 22857.0 |
| 3 | 奉贤地铁5号线!首付15万!外地人!精装修!随时 | 2室2厅2卫 | 45.0 | 南 | 中层 | 奉贤 | 中原地产-周秀娟 | 45.0 | 10000.0 |
| 4 | 临港自贸区 精装样板房售 地铁8号线总价219万 | 3室2厅1卫 | 89.0 | 南 | 高层 | 奉贤 | 中原地产-王红霞 | 219.0 | 24606.0 |
from sklearn.datasets import load_boston
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# x = list(set(test_ana3['面积']))
# y = list(set(test_ana3['单价']))
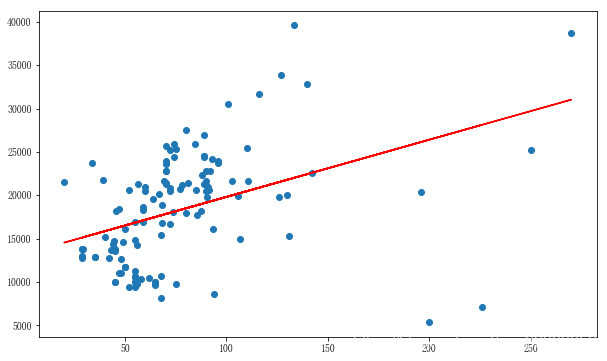
#强制转化类型
test_ana2['面积']=test_ana2['面积'].astype('float')
test_ana2['单价']=test_ana2['单价'].astype('float')
x = test_ana2['面积']
y = test_ana2['单价']
lineR = LinearRegression()
lineR.fit(x.values.reshape(-1, 1), y)
w = lineR.coef_ # x前的系数
b = lineR.intercept_ # 截距
print(w)
print(b)
from matplotlib import pyplot as plt
plt.figure(figsize=(10, 6))
plt.scatter(x, y)
plt.plot(x, float(w) * x + float(b) , 'r')
plt.show()
D:\anaconda\lib\site-packages\ipykernel_launcher.py:8: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
D:\anaconda\lib\site-packages\ipykernel_launcher.py:9: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
if __name__ == '__main__':
[65.99685955]
13230.032835868691
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pTIuwcVK-1574604502721)(output_49_2.png)]
test_all.head()| 名称 | 厅室 | 面积 | 朝向 | 楼层 | 小区 | 联系人 | 价格 | 单价 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 16号线地铁旁。临港自贸区,学,区房 | 3室2厅2卫 | 96.0 | 南 | 中层 | 浦东 | 中原地产-周保友 | 245.0 | 25520.0 |
| 1 | 70年产权,外地可买,近16号线地铁,南北户型, | 2室2厅2卫 | 78.0 | 南北 | 低层 | 浦东 | 中原地产-刘林娟 | 75.0 | 9615.0 |
| 2 | 金沁苑丨小区第二排丨电梯12楼丨25万精装丨不靠 | 3室2厅1卫 | 97.4 | 南 | 高层 | 浦东 | 齐星地产-落丁瑞 | 280.0 | 28747.0 |
| 3 | 临港滴水湖地铁1公里!现房叠加别墅(可公积金贷款 | 4室2厅2卫 | 117.0 | 南北 | 低层 | 浦东 | 上海锦镓房地产经纪事务所-饶帅 | 288.0 | 24615.0 |
| 4 | 外地人可买挑高5米通燃气地铁口800米首付10万 | 2室2厅1卫 | 45.0 | 南北 | 中层 | 浦东 | 中原地产-陈治刚 | 70.0 | 15555.0 |
test_ana3=test_all.drop(['名称','小区'],axis=1)test_ana3.head()| 厅室 | 面积 | 朝向 | 楼层 | 联系人 | 价格 | 单价 | |
|---|---|---|---|---|---|---|---|
| 0 | 3室2厅2卫 | 96.0 | 南 | 中层 | 中原地产-周保友 | 245.0 | 25520.0 |
| 1 | 2室2厅2卫 | 78.0 | 南北 | 低层 | 中原地产-刘林娟 | 75.0 | 9615.0 |
| 2 | 3室2厅1卫 | 97.4 | 南 | 高层 | 齐星地产-落丁瑞 | 280.0 | 28747.0 |
| 3 | 4室2厅2卫 | 117.0 | 南北 | 低层 | 上海锦镓房地产经纪事务所-饶帅 | 288.0 | 24615.0 |
| 4 | 2室2厅1卫 | 45.0 | 南北 | 中层 | 中原地产-陈治刚 | 70.0 | 15555.0 |
#强制转化类型
test_ana3['面积']=test_ana3['面积'].astype('float')
test_ana3['价格']=test_ana3['价格'].astype('float')
test_ana3['单价']=test_ana3['单价'].astype('float')import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
test_ana2.hist(figsize=(20, 10))array([[<matplotlib.axes._subplots.AxesSubplot object at 0x000001910FA3C358>,
<matplotlib.axes._subplots.AxesSubplot object at 0x00000191119A52E8>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x00000191122C4048>,
<matplotlib.axes._subplots.AxesSubplot object at 0x000001910F62ADD8>]],
dtype=object)
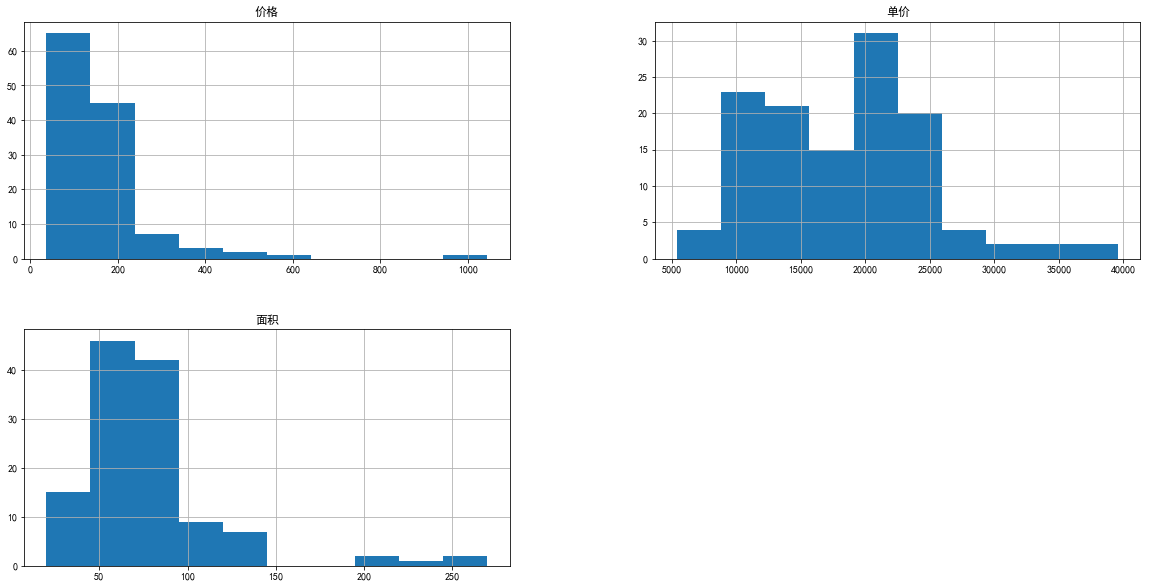
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uf1YwXOG-1574604502722)(output_54_1.png)]
test_ana3 = pd.get_dummies(test_ana3)
test_ana3.head()| 面积 | 价格 | 单价 | 厅室_1室0厅1卫 | 厅室_1室1厅1卫 | 厅室_1室1厅2卫 | 厅室_1室2厅1卫 | 厅室_1室2厅2卫 | 厅室_2室0厅1卫 | 厅室_2室1厅0卫 | ... | 联系人_隆宸地产-石彩荣 | 联系人_隆宸地产-贾文杰 | 联系人_隆宸地产-贾梦杰 | 联系人_顾卿地产-杨亮亮 | 联系人_风越地产-柴山宝 | 联系人_首众房地产-杨思其 | 联系人_鸿睿地产-方毅伟 | 联系人_鸿途房产-徐威 | 联系人_齐星地产-苏飞龙 | 联系人_齐星地产-落丁瑞 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 96.0 | 245.0 | 25520.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 78.0 | 75.0 | 9615.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 97.4 | 280.0 | 28747.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 117.0 | 288.0 | 24615.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 45.0 | 70.0 | 15555.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 1325 columns
y = test_ana3['价格']
X = test_ana3.drop(['价格'],axis=1)
print('data shape: {0}; no. positive: {1}; no. negative: {2}'.format(
X.shape, y[y==1].shape[0], y[y==0].shape[0]))
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)data shape: (3411, 1324); no. positive: 0; no. negative: 0
from sklearn import linear_model
model =linear_model.LinearRegression()
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print('train score: {train_score:.6f}; test score: {test_score:.6f}'.format(
train_score=train_score, test_score=test_score))train score: 0.974414; test score: -1842925904489.912354
y_1 = model.predict(X_test)final=pd.DataFrame(data={
'Income':y_1
})final.plot()<matplotlib.axes._subplots.AxesSubplot at 0x1910f3d6438>

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SmtC9P8u-1574604502723)(output_60_1.png)]
