一、项目概览
利用加州普查数据,建立一个加州房价模型。
目标:模型利用该数据进行学习,然后根据其他指标,预测任何街区的房价中位数
二、划定问题
建立模型不可能是最终目标,而是公司的受益情况,这决定了如何划分问题,选择什么算法,评估模型的指标和微调等等
你建立的模型的输出(一个区的房价中位数)会传递给另一个机器学习系统,也有其他信号传入该系统,从而确定该地区是否值得投资。
设计系统:
1、划定问题:监督与否、强化学习与否、分类与否、批量学习或线上学习
2、确定问题:典型的监督学习任务,多变量的回归问题,样本数据不多可以使用批量学习。
三、选择性能指标
回归问题的典型指标是均方根误差(RMSE),均方根误差测量的是系统预测误差的标准差:
四、核实假设
最好列出并核对迄今做出的假设,这样可以尽早发现严重的问题,例如,系统输出的街区房价会传入到下游的机器学习系统,我们假设这些价格确实会被当做街区房价使用,但是如果下游系统将价格转化为分类(便宜、昂贵、中等等),然后使用这些分类来进行判定的话,就将回归问题变为分类问题,能否获得准确的价格已经不是很重要了。
五、获取数据
使用pandas加载数据的话,获得一个包含所有数据的DataFrame对象,DataFrame对象是表格型的数据结构,提供有序的列和不同类型的列值。
housing.head():查看前5行
housing.info():方法可以快速查看数据的描述,特别是总行数、每个属性的类型和非空值的数量
housing["ocean_proximity"].value_counts():查看非数值的项,也就是距离大海距离的项包含哪些属性,每个属性包含多少个街区
housing.describe():方法查看数值属性的概括(均值、方差、最大最小、分位数等)
housing.hist():柱状图

六、创建测试集
测试集在这个阶段就要进行分割,因为如果查看了测试集,就会不经意的按照测试集中的规律来选择某个特定的机器学习模型,当再使用测试集进行误差评估的时候,就会发生过拟合,在实际系统中表现很差。
随机挑选一些实例,一般是数据集的20%
1、随机划分20%为测试集:
from sklearn.model_selection import train_test_split
train_set,test_set=train_test_split(housing,test_size=0.2,random_state=42)随机划分的特点:
随机的取样方法,当数据集很大的时候,尤其是和属性数量相比很大的时候,通常是可行的,但是如果数据集不大,就会有采样偏差的风险,出现训练和测试数据分布差距太大的问题。
当一个调查公司想要对1000个人进行调查,不能是随机取1000个人,而是要保证有代表性,美国人口的51.3%是女性,48.7%是男性,所以严谨的调查需要保证样本也是这样的比例:513名女性,487名男性,这称为分层采样。
2、分层抽样
将人群分成均匀的子分组,称为分层,从每个分层去取合适数量的实例,保证测试集对总人数具有代表性。
可以利用和最终的房屋价值中位数的关联最大的特征作为分层抽样的标准。
此处收入的中位数对最终结果的预测很重要,所以利用不同收入分布来划分测试集,保证划分之后,每个收入层级的频率分布基本保持不变。
收入中位数是连续值,利用收入中位数/1.5,ceil()对值进行舍入,以产生离散的分类,然后将所有大于5的分类归类于分类5
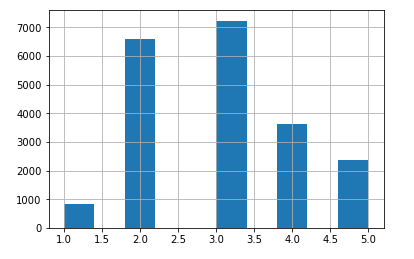
根据收入分类,进行分层采样,使用sklearn的stratifiedShuffleSplit类
分层抽样可以使得测试集和原始的数据集在重要特征的分布上基本一致。
七、数据探索和可视化、发现规律
将地理位置、房价等因素和输出的标签做一个可视化,查看其分布状况。
八、查找关联
1、person系数
因为数据集并不是很大,所以可以使用corr()的方法来计算出每对属性间的标准相关系数,也称为person相关系数
corr_matrix=housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)输出:
median_house_value 1.000000
median_income 0.687160
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population -0.026920
longitude -0.047432
latitude -0.142724
Name: median_house_value, dtype: float64可以看出median_income和最终的输出结果的相关程度很高
2、scatter_matrix()函数:
可以绘制每个数值属性对每个其他数值属性的图,因为现在有11个数值属性,可以得到 112=121112=121 张图,所以只关注几个和房价中位数最有可能相关的属性。
最有希望用来预测房价中位数的属性是收入中位数,因此将这张图放大:
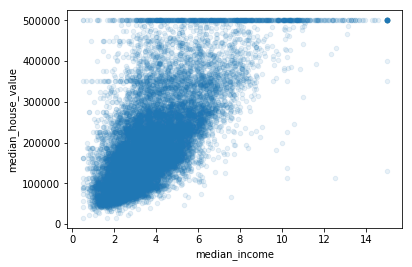
该图说明了几点:
首先,相关性非常高,可以清晰的看到向上的趋势,并且数据点不是很分散
其次,图中在280000美元、350000美元、450000美元、500000美元都出现了水平线,可以去除对应的街区,防止过拟合
九、属性组合实验
创建三个新特征:
roomes_per_household
bedrooms_per_rooms
population_per_household
housing["roomes_per_household"]=housing["total_rooms"]/housing["households"]
housing["bedrooms_per_rooms"]=housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
corr_matrix=housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)# False:降序输出:
median_house_value 1.000000
median_income 0.687160
roomes_per_household 0.146285
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population_per_household -0.021985
population -0.026920
longitude -0.047432
latitude -0.142724
bedrooms_per_rooms -0.259984
Name: median_house_value, dtype: float64与总房间数或卧室数相比,新的特征“每个房子中的卧室数 bedrooms_per_room”属性与房价中位数的关联更强,也就是卧室数/总房间数的比例越低,房价就越高,每户的房间数也比街区的总房间数更有信息,也就是房屋越大,房价就越高。
这一步的数据探索不必非常完备,此处的目的是有一个正确的开始,快速发现规律,以得到一个合理的原型。
十、为机器学习算法准备数据
为机器学习算法准备数据,不用手工来做,你需要写一些函数,理由如下:
函数可以让你在任何数据集上方便的进行重复数据转换
可以慢慢建立一个转换函数库,可以在未来的项目中重复使用
在将数据传给算法之前,你可以在实时系统中使用这些函数
可以让你方便的尝试多种数据转换,查看哪些转换方法结合起来效果最好
先回到干净的训练集,将预测量和标签分开,因为我们不想对预测量和目标值应用相同的转换(注意drop创建了一份数据的备份,而不影响strat_train_set):
housing=strat_train_set.drop("median_house_value",axis=1)
housing_labels=strat_train_set["median_house_value"].copy()1、数据清洗
大多数机器学习算法不能处理缺失的特征,因此创建一些函数来处理特征缺失的问题,前面的total_bedrooms有一些缺失值,有三个解决问题的方法:
去掉对应街区:
housing.dropna()去掉整个属性:
housing.drop()进行赋值(0、平均值、中位数):
housing.fillna(median)
sklearn提供了一个方便的类来处理缺失值:Imputer
- 首先,创建一个Imputer示例,指定用某属性的中位数来替换该属性所有的缺失值
from sklearn.preprocessing import Imputer
imputer=Imputer(strategy="median")- 因为只有数值属性才能算出中位数,需要创建一份不包括文本属性ocean_proximity的数据副本
housing_num=housing.drop("ocean_proximity",axis=1)- 最后,利用fit()方法将imputer实例拟合到训练数据
imputer.fit(housing_num)- 现在就是用该“训练过的”imputer来对训练集进行转换,将缺失值替换为中位数:
X=imputer.transform(housing_num)2、处理文本和类别属性
前面,我们丢弃了类别属性ocean_proximity,因为它是一个文本属性,不能计算出中位数,大多数机器学习算法喜欢和数字打交道,所以让我们把这些文本标签转化为数字。
① 利用转换器LabelEncoder,将四个值转换为0,1,2,3
这种方法会出现不同的大小影响判断的情况,所以引入二元属性。
② 独热编码
3、添加附加属性
4、特征缩放
属性量度差距过大的话,机器学习性能下降,梯度下降寻找最优解的过程不稳定且很耗时。
两种常见的方法让所有的属性具有相同的量度:
线性归一化(MinMaxScalar)
标准化(StandardScalar)
注意:缩放器之能向训练集拟合,而不是向完整的数据集,只有这样才能转化训练集和测试集
5、转换流水线
数据处理过程中,存在许多数据转换步骤,需要按照一定的顺序进行执行,sklearn提供了类——Pipeline来进行一系列转换,
十一、选择并训练模型
前面限定了问题、获得了数据、探索了数据、采样了测试集,写了自动化的转换流水线来清理和为算法准备数据,现在可以选择并训练一个机器学习模型了。
1、在训练集上训练和评估
(1)线性回归模型
from sklearn.linear_model import LinearRegression
lin_reg=LinearRegression()
lin_reg.fit(housing_prepared,housing_labels)RMSE=68628,结果并不好,大多数街区的房价中位数位于120000-265000美元之间,因此预测误差68628并不能让人满意,这是一个欠拟合的例子,所以我们要选择更好的模型进行预测,也可以添加更多的特征,等等。
(2)决策树
from sklearn.tree import DecisionTreeRegressor
tree_reg=DecisionTreeRegressor()
tree_reg.fit(housing_prepared,housing_labels)RMSE=0,过拟合
2、利用交叉验证来评估模型
评估决策树模型的一种方法是用函数train_test_split来分割训练集,得到一个更小的训练集和一个验证集,然后用更小的训练集来训练模型,用验证集进行评估。
另一种方法是使用交叉验证功能,下面的代码采用了k折交叉验证(k=10),每次用一个折进行评估,用其余九个折进行训练,结果是包含10个评分的数组。
from sklearn.model_selection import cross_val_score
scores=cross_val_score(tree_reg,housing_prepared,housing_labels,scoring="neg_mean_squared_error",cv=10)
scores
tree_rmse_scores=np.sqrt(-scores)输出:
array([ -4.69780143e+09, -4.53079547e+09, -5.09684731e+09,
-4.76712153e+09, -5.10478677e+09, -5.49833181e+09,
-5.11203877e+09, -4.83185329e+09, -5.95294534e+09,
-4.98684497e+09])查看得分函数:
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())display_scores(tree_rmse_scores)输出:
Scores: [ 68416.06869621 67700.71364388 70107.46534824 68567.83436176
71987.47320813 74458.15245677 70294.48853581 71217.57501034
76961.44182696 70069.50630652]
Mean: 70978.0719395
Standard deviation: 2723.10200089交叉验证不仅可以让你得到模型性能的评估,还能测量评估的准确性,也就是标准差,决策树的评分大约是70978,波动为+-2723,如果只有一个验证集就得不到这些信息,但是交叉验证的代价是训练了模型多次,不可能总是这样
(3)随机森林
from sklearn.ensemble import RandomForestRegressor
forest_reg=RandomForestRegressor(random_state=42)
forest_reg.fit(housing_prepared,housing_labels)from sklearn.model_selection import cross_val_score
forest_scores=cross_val_score(forest_reg,housing_prepared,housing_labels,scoring="neg_mean_squared_error",cv=10)
forest_rmse_scores=np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)输出:
Scores: [ 51650.94405471 48920.80645498 52979.16096752 54412.74042021
50861.29381163 56488.55699727 51866.90120786 49752.24599537
55399.50713191 53309.74548294]
Mean: 52564.1902524
Standard deviation: 2301.87380392随机森林看起来不错,但是训练集的评分仍然比验证集评分低很多,解决过拟合可以通过简化模型,给模型加限制,或使用更多的训练数据来实现。
可以尝试机器学习算法的其他类型的模型(SVM、神经网络等)
3、模型微调
假设现在有了一个列表,列表里有几个希望的模块,你现在需要对它们进行微调,下面有几种微调的方法。
(1)网格搜索
可以使用sklearn的GridSearchCV来做这项搜索工作:
from sklearn.model_selection import GridSearchCV
param_grid=[{'n_estimators':[3,10,30],'max_features':[2,4,6,8]},
{'bootstrap':[False],'n_estimators':[3,10],'max_features':[2,3,4]},]
# 3棵树、10棵树、30棵树集成
# 最大特征数:2/4/6/8
forest_reg=RandomForestRegressor()
grid_search=GridSearchCV(forest_reg,param_grid,cv=5,scoring='neg_mean_squared_error')
grid_search.fit(housing_prepared,housing_labels)注意:
param_grid:
首先评估所有的列在第一个dict中的n_estimators和max_features的3x4=12种组合
之后尝试第二个dict中超参数的2x3=6种组合,这次会将超参数bootstrap设为False而不是True
总之,网格搜索会探索12+6=18种RandomForestRegressor的超参数组合,会训练每个模型5次,因为是5折交叉验证,也就是总共训练18x5=90轮,最终得到最佳参数组合。
利用grid_search.best_params_得到最佳估计参数:{'max_features': 8, 'n_estimators': 30}
grid_search.best_estimator_也可以得到最佳估计器:
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features=8, max_leaf_nodes=None, min_impurity_split=1e-07,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=30, n_jobs=1,
oob_score=False, random_state=None, verbose=0, warm_start=False)如果GridSearchCV是以默认值refit=True开始运行的,则一旦用了交叉验证找到了最佳估计器,就会在整个训练集上重新训练。
得到评估得分:
cvres=grid_search.cv_results_
for mean_score,params in zip(cvres["mean_test_score"],cvres["params"]):
print(np.sqrt(-mean_score),params)输出:
64215.557922 {'n_estimators': 3, 'max_features': 2}
55714.8764381 {'n_estimators': 10, 'max_features': 2}
53079.4656786 {'n_estimators': 30, 'max_features': 2}
60922.7203346 {'n_estimators': 3, 'max_features': 4}
52804.3071875 {'n_estimators': 10, 'max_features': 4}
50617.4676308 {'n_estimators': 30, 'max_features': 4}
59157.2838878 {'n_estimators': 3, 'max_features': 6}
52452.1859118 {'n_estimators': 10, 'max_features': 6}
50004.9240828 {'n_estimators': 30, 'max_features': 6}
58781.2418874 {'n_estimators': 3, 'max_features': 8}
51669.9337736 {'n_estimators': 10, 'max_features': 8}
49905.3850728 {'n_estimators': 30, 'max_features': 8}
62068.9023546 {'bootstrap': False, 'n_estimators': 3, 'max_features': 2}
53842.6681258 {'bootstrap': False, 'n_estimators': 10, 'max_features': 2}
59645.8537753 {'bootstrap': False, 'n_estimators': 3, 'max_features': 3}
52778.2491624 {'bootstrap': False, 'n_estimators': 10, 'max_features': 3}
59149.2314414 {'bootstrap': False, 'n_estimators': 3, 'max_features': 4}
51774.2952583 {'bootstrap': False, 'n_estimators': 10, 'max_features': 4}该例子中,我们通过设定超参数max_features为8,n_estimators为30,得到了最佳方案,RMSE的值为49959,这比之前使用默认超参数的值52634要好。
(2)随机搜索
当探索相对较少的组合时,网格搜索还可以,但是当超参数的搜索空间很大的时候,最好使用RandomizedSearchCV,该类不是尝试所有可能的组合,而是通过选择每个超参数的一个随机值的特定数量的随机组合,该方法有两个优点:
如果你让随机搜索运行,比如1000次,它会探索每个超参数的1000个不同的值,而不是像网格搜索那样,只搜索每个超参数的几个值
可以方便的通过设定搜索次数,控制超参数搜索的计算量
(3)集成方法
另一种微调系统的方法是将表现最好的模型组合起来,组合之后的性能通常要比单独的模型要好,特别是当单独模型的误差类型不同的时候。
4、用测试集评估系统
调节完系统之后,终于有了一个性能足够好的系统,现在就可以用测试集评估最后的模型了:从测试集得到预测值和标签
运行full_pipeline转换数据,调用transform(),再用测试集评估最终模型:
final_model=grid_search.best_estimator_
X_test=strat_test_set.drop("median_house_value",axis=1)
y_test=strat_test_set["median_house_value"].copy()
X_test_prepared=full_pipeline.transform(X_test)
final_predictions=final_model.predict(X_test_prepared)
final_mse=mean_squared_error(y_test,final_predictions)
final_rmse=np.sqrt(final_mse)
final_rmse输出:47997.889508495638
5、启动、监控、维护系统
(1)启动
需要为实际生产做好准备,特别是接入输入数据源,并编写测试
(2)监控
需要监控代码,以固定间隔检测系统的实时表现,当发生下降时触发警报,这对于捕捉突然的系统崩溃性能下降十分重要,做监控很常见,因为模型会随着数据的演化而性能下降,除非模型用新数据定期训练。
评估系统的表现需要对预测值采样并进行评估,通常人为分析,需要将人工评估的流水线植入系统
(3)维护
数据的分布是变化的,数据会更新,要通过监控来及时的发现数据的变化,做模型的优化。